0x00 前言
往往那些不起眼的功能,最能毁掉你的工作成果。
本篇分享一些和数据质量监控相关的内容。数据质量监控是一个在快速发展的业务中最容易被牺牲和忽略的功能,但是它确实至关重要的。
假设你做了100个业务,一旦有其中一个业务在某个时间段出现了数据异常,这个异常还是由业务方发现的而不是你,根据我的经验是,它带来的负面影响会超过你之前做的100个业务带来的正面影响。
文章结构
数据质量监控的意义和价值就不再谈了,本文主要讨论下面两个主题:
- 数据质量监控要做哪些监控内容
- 该怎么做
文中会涉及到数据仓库其它的一些知识点,请参考:http://dantezhao.com/
0x01 什么值得你监控
我把数据质量分成三部分来理解:
- 监控
- 告警
- 多数据源
重点在监控,这点会展开来讲,多数据源这一块是因为在大数据场景下,我们有太多的开源组件来选择,很多组件的数据都需要监控,而且每个都不一样,如果统一地来监控是个重要的话题。
如下图,我先列一个大致的思维导图,然后详细讲每一部分。

一、 监控
监控这一块比较大。整体来讲,我会把它分为这几块:日常监控、数据对账、性能监控。下面分开来讲。
1. 日常监控
日常监控中最重要的一个就是数据落地检查,这应该是所有监控的一个基础,不然没数据你玩个毛啊。
下面是我认为一些比较常用的监控内容:
- 数据落地监控
- 数据掉0监控:实际扩展一下就是数据量阈值监控,少于某个量就告警
- 重复数据监控:很多表一定要监控重复数据的,这点至关重要。
- 关键指标监控
- 数据同比环比监控
这是一些常用的监控,在后面会提到,我们可以做一个规则引擎,上面提到的都坐到规则里面,哪个表需要了就陪一下就行了。
2. 数据对账
这点主要会体现到实时数据上,特别是Kafka数据落地,必须要有一个监控机制来知道我们的数据落地情况。
当然离线数据同样需要数据对账,对账方法有很多,比如可以和业务库来对比。
3. 性能监控
我把这点理解为数据可用性监控,我认为这是一个很重要的点。 如果你做的数据别人用起来十分不爽,或者慢得要死根本没法用,那做了和没做有什么区别?
感觉在性能监控上就是有几个点要注意:
- 查询性能,比如es的某个索引,在不同时间段的查询响应速度,同理presto、hive、kylin这些的查询都需要注意一下,这点可以通过任务监控来观察。
- 数据读写影响,机器故障影响,这点平常不太关注,不过像es这种,在写入数据的时候其实会影响读数据的,需要监控一下,并做相应调整。
二、告警
告警就不用说了,微信、短信和电话都很有必要。
定期的邮件汇总告警也很有必要。
然后有很多的告警可以考虑一个告警报表系统来展示,特别像是数据量趋势这种监控内容,可视化的对比比较有效。
三、 多数据源
在目前的大数据场景下,各种开源组件引入的十分多,而且会有新的组件不停地引入,因此要考虑到对不同组件的数据监控。
目前笔者接触比较多的会有Hive(presto、spark sql)、Mysql、ES、Redis、Kylin(主要是构建的cube)这些常用的,但是不能排除图数据库(neo4j、orientdb)和druid这些组件引入的可能性。
0x02 怎样监控
数据监控相对来讲是属于后台系统,不能算是对外的业务系统,一般重要性可能会被挑战,虽说如此,它还是值得一做的。 不过可能要换一些思路来做,如何快速地实现、并抓住核心的功能点是值得深思的一件事。
这里不会有实现,只会有一些设计思路,欢迎来讨论。
如图是一个整体的构思,我先分析几个个人认识比较重要的点。后面会详细地来分析。
- 规则引擎:来定义各种告警规则,可能是一条sql模板,也可能是一些具体的算法。
- 执行引擎:要来执行各种规则,同时要考虑各种数据源的差异。
- 元数据系统:数据质量监控本来也算是元数据系统的一部分,我们这分开来讲,但是无论如何,在配置表的告警信息时,还是要和元数据系统结合的。
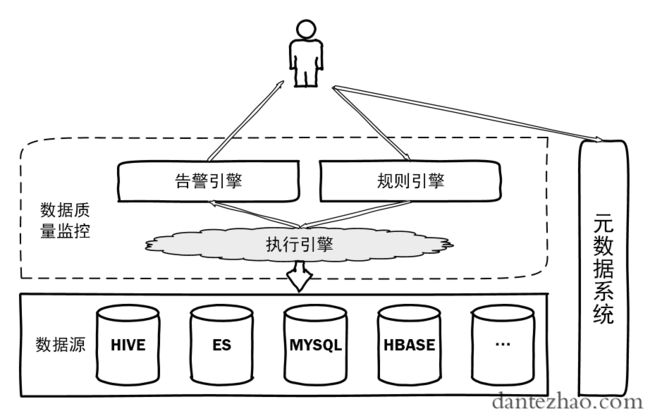
下面会分开来分析一下这几个组件。
一、 规则引擎
举几个典型例子:数据延迟到达、数据同比环比、数据趋势、一些定制化算法。
这块的设计可以很灵活,也可以临时开发一个简单的。这里提几个点。
1. Sql模板
在大多数存储引擎中,通过Sql使用的数据(比如Hive、Mysql)会是比较重要的一种数据,这种数据我们可以考虑用Sql模板。
我们会有一张表或者一些配置文件来定义我们的规则。简单来讲,比如说数据同比环比,我们可以写一个presto的sql模板,来和历史数据进行对比,这种sql很简单,自己写好模板就行。
这种模板最简单,也最快,我相信能解决大部分问题。
2. 元数据
很多数据库都是有元数据管理的,比如Hive,它的表的行数都是在元数据库中有存放的,我们可以直接通过Hive的元数据来抓取表的每天的数据量的。
注意:这点十分重要,它能节省我们大部分的工作,而且比较稳定,但是能满足的功能比较少。需要结合其它来使用。
3. 自定义模板
有很多算法不是简单的sql就能搞定的,而且很多存储系统也不是所有都支持sql。比如es这种。因此就需要一些定制化的算法来实现。
这方面的主要工作量应该是在执行引擎上,但是在规则引擎应该有设计到。
二、执行引擎
这块应该是比较重要的。 实现起来可以很简单,也可以很复杂。下面大概聊一下。
1. Sql执行
很多规则都可以通过sql来执行的,这点在规则引擎里面提到了。
其实我很推荐,刚开始的比较粗糙的监控都可以这样来做。 我们提前配置好大部分的sql模板,然后需要监控哪张表了就在这张表配置一下就行。
具体的执行引擎的话可以考虑presto或者spark sql,特别大的任务可以考虑hive。
优点:
- 简单,方便实现
- 能满足大部分的需求
缺点:
- 灵活度不够,比如es,对sql支持太差
- 速度慢:很多sql执行起来会比较慢,特别是使用hive引擎的时候,会巨慢。
- 不稳定:一些监控会不太稳定,比如重复数据监控,对一些大的表来讲,用presto这种,是很难出结果的,经常会挂掉,但是换成hive的话又会很慢。
那么如何解决?
嗯,解决的话,我只有下面几个思路:
- 合理的任务调度,一般集群都是能容纳很多任务的,合适地调度监控任务比较重要。
- 合理地替换执行引擎,这个下一节会提供一种方案。
- 合理的任务依赖,比如说是重复数据监控,这点必然会依赖于数据是否到达,如果数据没达到就没必要执行重复数据监控的程序。
2. 直接获取数据量
前面提到了Sql执行的一个执行效率问题,我们这节提供一个优化的方法。因为Hive目前来讲是十分重要的一种引擎了,所以单说Hive。
Hive是有元数据管理的,它的元数据库中是记录Hive的所有表的记录数的,这些记录数可以直接用作数据量相关的监控,比如数据掉零、数据量环比同比、数据量趋势等。
3. 算法执行引擎
很多算法可以通过自定义地方式实现,这一点实现起来就会比较复杂一些。
因为定制化比较强,在设计这一块的话需要一个比较灵活的架构,这里不再展开来讲,因为在常见的数据领域里面,前两点已经能满足很多需求了。
4. 多数据源
多数据源这一块,在规则引擎里面需要加一些区分,因为这毕竟和元数据系统关联,区分还是比较简单。
在执行的时候,可能要稍微分开来实现。不过相对来讲不是很复杂。
0xFF 总结
本篇主要分享了一些和数据质量监控相关的内容,有一些泛泛而谈的感觉,但是理清思路后很多实现起来也是很简单的, 想做个简单能用的出来,用python半天就能搞定。
这里主要是思路,具体的实现就不再写了。毕竟根据业务需求,实现的程度也会不一样。
作者:dantezhao | | CSDN | GITHUB
个人主页:http://dantezhao.com
文章可以转载, 但必须以超链接形式标明文章原始出处和作者信息