传统的文本分类一般都是使用词袋模型/Tf-idf作为特征+机器学习分类器来进行分类的。随着深度学习的发展,越来越多的神经网络模型被用来进行文本分类。本文将对这些神经网络模型做一个简单的介绍。
《Enriching Word Vectors with Subword Information》
本文介绍了一种词向量模型,虽然算不得文本分类模型,但由于其可以说是fasttext的基础。因此也简单提一下。
作者认为cbow和skipgram及大部分词向量模型都没有考虑到单词的多态性,而简单的将一个单词的多种形态视为独立的单词。例如like的不同形式有likes,liking,liked,likes,这些单词的意思其实是相同的,但cbow/skipgram模型却认为这些单词是各自独立的,没有考虑到其形态多样性。
因此作者提出了一个可以有效利用单词字符级别信息的n-gram词向量模型,该模型是以skipgram模式实现的。例如单词 where,其n-gram表示为
而在loss方面,文中采用了负采样+binary LogisticRegression的策略。即对每一个目标单词都预测为正负中的一种。
《Bag of Tricks for Efficient Text Classification》
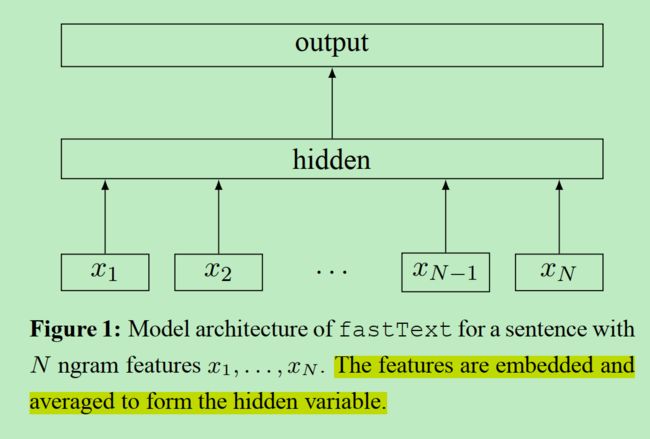
在本文中作者提供了一个基于神经网络的文本分类模型,这个模型是基于cbow的,与cbow非常类似。
和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。不同的是,CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征的embeding表示方式,这些特征用来表示单个文档;CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;CBOW的输出是目标词汇,fastText的输出是文档对应的类标。输出层的实现同样使用了层次softmax,当然如果自己实现的话,对于类别数不是很多的任务,个人认为是可以直接使用softmax的。

最后,贴一个Keras的模型fasttext简化版。
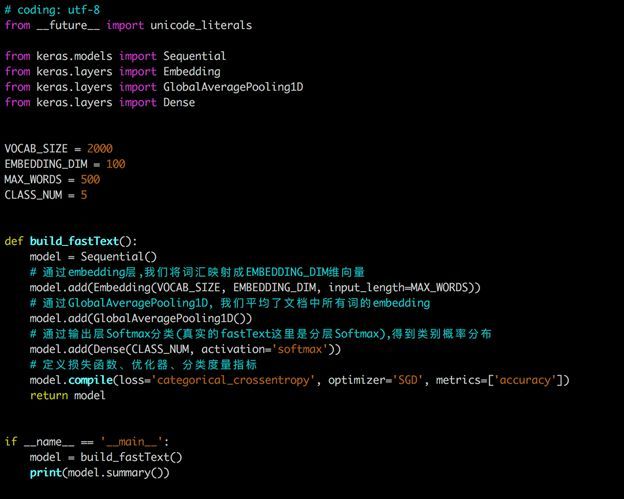
从上面可以看出,其实自己实现fasttext有两种方式,第一种是将embeding词向量训练过程与文本分类任务结合在一起,也就是上面实现的模型;第二种则是单独训练embeding词向量,然后将这个ngram词向量作为特征输入到分类器中,如果分类器是神经网络,则是fasttext,当然此时也可以将词向量作为特征与其他分类器组合来进行训练构建模型。
《Convolutional Neural Networks for Sentence Classification》

基于词向量表示,本文提出利用卷积神经网络来进行文本分类。其算法如上图所示:
- (1)每个单词的词向量表示为一行,而将这所有单词拼接起来的矩阵则与图片非常相似,这些便是模型的输入。也即此时的输入是各个单词的embeding的拼接矩阵。但是也是可以将单词的onehot向量作为输入的,不过此时就是将词向量训练过程与文本分类任务合在一起了,这个其实与推荐算法中的各种id embeding利用类似;
- (2)有了词向量拼接组成的矩阵,便可以使用卷积核进行卷积运算了。不过这里的卷积核与图形中的卷积核略有不同。这里卷积核的长是与embeding维度相同的,而宽则可以认为是跨越几个单词。因此一个卷积核与词向量矩阵的运算可以看作是从一个n-gram单词中提取特征。在文中使用的卷积核宽度有3,4,5,也即使用的n-gram有3,4,5三种情况;
- (3)卷积运算后作者对每个feature map使用了一个maxpooling操作,表示从中提取出最重要的特征,作者认为值越大这个特征越重要;
- (4)将所有fenture map通过maxpooling 提取到的特征组合成一个一维向量,然后构建一个全连接层输出分类结果。
在本文中,作者尝试了多种不同的词向量模式:
- (1)CNN-rand, 所有的词向量都是随机初始化的,随着训练过程一起训练。这种也即我们上面提到的将词向量训练过程与分类任务结合在了一起。这个模型是效果最差的,说明预训练的词向量是非常重要的;
- (2)CNN-static,所有的词向量都来自预训练,且在训练过程中保持固定不进行更新。这个结果相较于CNN-rand有了较大的提升;
- (3)CNN-nonstatic,使用预训练的词向量,但是在训练中进行更新。这种模型的结果比上面的要稍好;
- (4)CNN-multichannel,使用了两个词向量,每个词向量组成的矩阵相当于一个channel(也即相当于图像的RGB三通道)。但是,其中一个词向量保持固定不进行训练,另一个则进行更新。作者认为,仅有一个词向量且进行更新的话可能会过拟合这个当前较小的数据集,因此保留了一个词向量固定不进行训练。最后这个结果与CNN-nonstatic相差无几,还是比较令人意外的。
《Effective Use of Word Order for Text Categorization with Convolutional Neural Networks》
在上一篇文章中CNN网络的输入一般是预训练好的词向量,而在本文中作者提出一种直接将embedding训练与分类任务结合在一起,且能有效提取/保留词序信息,也即有效训练出n-gram的模型方法,其实也可以理解为一种利用CNN来进行embedding的方法。
为了保留词序信息,作者提出了两种模型训练方法,第一种是将各个词的onehot向量合并在一起,以保留词序信息,训练n-gram模型,称为seq-CNN,如'I love it'的bi-gram表示如下:
但是seq-CNN有一些缺点,当n-gram的n过大时,或者词典过大时,seq-CNN的表示方式,会使得向量维度过大(即会堆叠过长),从而造成过多的参数需要学习,加大算法的计算复杂度,因此提出了第二种方式,词袋模型bow-CNN(bag of word CNN),如下:
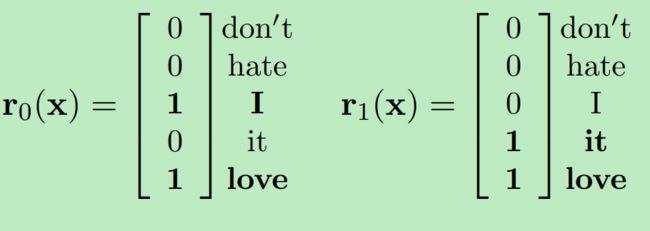
这种方式虽然在很小程度上损失了语序信息(如bi-gram使用bow表示时是没有考虑到语序的),也可以理解为损失了局部语序信息,但是实验结果证明其效果与seq-CNN相似,但是其参数更少,因此推荐使用。
此外,另一个问题是输入序列长度变化问题(在上一篇文章textCNN中通过padding解决的?),在本文作者提出使用一个动态可变的pooling层来解决这个问题,使得卷积层输出的大小是相同的。关于可变pooling其实与图像识别中的空间金字塔池化 (Spatial Pyramid Pooling) 是类似的。
这篇文章有点将fastText与TextCNN结合在一起的感觉,将n-gram embedding与分类任务结合在了一起进行训练,通过CNN来进行Embedding。
《Semi-supervised Convolutional Neural Networks for
Text Categorization via Region Embedding》

在本篇文章中作者提出了一个tv-embedding(即two-view embedding),它也属于region embedding(也可以理解为ngram embedding)。这种方法与上面的bow-CNN表示相似,使用bow(bag of words)的方式来表示一个区域的词句,然后通过某个区域(region,左右邻域的单词或词句)来预测其前后的区域(单词或词句),即输入区域是view1,target区域是view2。tv-embedding是单独训练的,在使用的时候与CNN中的embedding组合在一起(形成多个channel?)。作者认为,word2vec方法预训练得到的embedding向量是普适性的,而通过特定任务的数据集的训练得到tv-embedding具有任务相关的一些信息,更有利于提升我们的模型效果。
吐槽一下,这篇文章没太看懂,也可能是英语太差,作者文章中没有那种一眼就能让人理解的网络图,像textCNN的图就非常一目了然,看图就知道是怎么做的了。
《Supervised and Semi-Supervised Text Categorization using LSTM for Region Embeddings》
本文提出了一个使用监督学习加半监督预训练的基于LSTM的文本分类模型。文章作者与上面相同,所以用到的很多技术可以说与上面也是同出一辙。因此简单说下本文的一些思路。
作者认为已有的直接使用LSTM作为文本分类模型并直接将LSTM的最后一个输出作为后续全连接分类器的方法面临两个问题:(1)这种方式一般都是与word embedding整合在一起(即输入onehot经过一个embedding层再进入LSTM),但是embedding训练不稳定,不好训练;(2)直接使用LSTM最后一个输出来表示整个文档不准确,一般来说LSTM输入中后面的单词会在最后输出中占有较重的权重,但是这对于文章表示来说并不总是对的。因此作者对这两点进行了改进:
-
- 对于前面embedding训练不稳定的问题,作者做出了点改进:(1)直接将embedding向量V与LSTM的权重W结合在了一起,也就是现在的W的功能其实是兼具W*V的功能的,而LSTM的输入也就直接变成了onehot向量。(2)作者还使用LSTM进行了tv-embedding半监督预训练,即LSTM中每个时序的输出预测结果为其后面的单词(作者这里使用的双向LSTM,但是原理是一样的反向的预测前面的词语就行了)。除此之外,作者还添加了CNN-tv-embedding到其中。作者将这些预训练的embedding向量合并到各个门的计算中,形式如下:
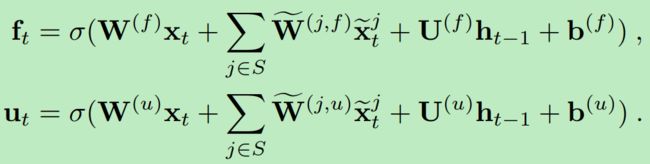
其中头上戴波浪线的就是预训练的embedding向量,其余的则是正常的LSTM门计算的方式。
- 对于前面embedding训练不稳定的问题,作者做出了点改进:(1)直接将embedding向量V与LSTM的权重W结合在了一起,也就是现在的W的功能其实是兼具W*V的功能的,而LSTM的输入也就直接变成了onehot向量。(2)作者还使用LSTM进行了tv-embedding半监督预训练,即LSTM中每个时序的输出预测结果为其后面的单词(作者这里使用的双向LSTM,但是原理是一样的反向的预测前面的词语就行了)。除此之外,作者还添加了CNN-tv-embedding到其中。作者将这些预训练的embedding向量合并到各个门的计算中,形式如下:
- 2、对于利用LSTM的最后一个输出来表示文档不准确的问题,作者提出使用一个maxpooling来对所有时序的输出来进行处理,以从每个时刻中选择最重要的表示,这一点其实跟RCNN想法基本相同的。由于maxpooling可以自动选择最重要的表示值,因此输入输出门不再有意义(这两个门也是用来选择是否对前面时序的输出值(ht,ct)进行遗忘的,功能重复),作者直接将输入输出门都设置为1。
- 3、此外,为了加速运算过程,作者将文章进行打断了分别输入到多个LSTM中以实现并行,最终pooling也是从这些所有的打断的LSTM中进行合并得到分类层的输出。
本文其实可以看作是作者将自己前面的tv-embedding半监督训练与RCNN的一个融合吧,大有一种一顿操作猛如虎,一看人头0-5的感觉(因为作者的实验结果跟一般的CNN相比其实也抢不了多少)。
《Deep Pyramid Convolutional Neural Networks for Text Categorization》

本文的作者也是前面两篇使用CNN来进行文本分类处理的文章的作者。因此在本文中,结合了前面两篇文章提出的一些方法,并使用了一个深层的卷积神经网络。具体的细节包括:
- 1、使用词袋向量模式作为模型的输入(即前文中bow-CNN的输入);
- 2、使用两个embedding向量,因此相当于两个embedding channel,一个是嵌合在模型中直接进行训练的CNN embedding,另一个则是上文提到的单独训练的tv-embedding。其中,tv-embedding是可选的,但作者证明tv-embedding是能有效提升模型效果的;
- 3、使用了深达15层的卷积网络,但是与图像中常见的卷积网络不同,在此网络中每一次下采样后网络的feature map数量都不变,而在图像的CNN网络中,每一次下采样后都会增加feature map的数量来增加特征多样性。本文中作者研究表明增加feature map数量并不能有效提升模型效果,而且会增大计算量,因此本文中的网络feature map数量一直未变。但是随着下采样的进行,每个block 都比之前的block feature map小了一半,因此计算量减半,各个block的计算量随着网络加深呈金字塔形状。这也是文章题目中 Pyramid 的由来;
- 4、最后,为了防止梯度消失,与大多数神经网络一样,本文采用resnet中的skip connection。
一点小思考:为什么深度卷积网络对文本分类有用?
在网络的第一层我们通过改变卷积核的大小来进行不同长度ngram的embedding,但是随着n的加大还是会出现长ngram稀疏性问题。而随着网络的加深,每个卷积核的感受野也变得越来越大,可以看作是能够有效的组织理解更长文本的语义。
更多详细的关于DPCNN的细节可以查看从DPCNN出发,撩一下深层word-level文本分类模型。
《Densely Connected CNN with Multi-scale Feature Attention for Text Classification》
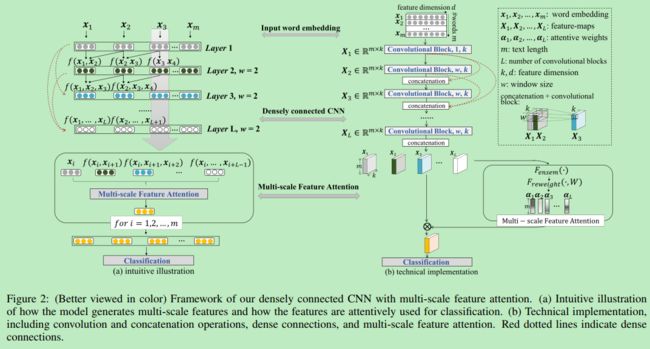
本文提出了一种基于CNN+Attention的文本分类模型。作者认为已有的基于CNN的文本分类模型大都使用的是固定大小的卷积核,因此其学习到的表示也是固定的n-gram表示,这个n与CNN filter大小相关。但是在进行句子的语义表示时,不同句子发挥重要作用的ngram词语常常是不同的,也即是变化的。因此,模型能根据句子来自适应的选择每个句子最佳的n-gram对于提升模型的语义表示能力是非常关键的。本文便是由此思路提出了一种自适应的来选择不同n-gram表示的模型。
本文模型在主题结构上参照了CV中的DenseNet,借由DenseNet中的稠密连接来提取到丰富的n-gram特征表示。举例来说,在layer3的特征不仅能学习到f(x1, x2, x3),还能学习到f(x1(x2,x3))这种更多层次,更加丰富的特征。网络的结构主要包括三部分:DenseCNN主网络,Attention module和最后的全连接层分类网络。下面对这三部分进行简单的说明:
- DenseCNN与DenseNet结构相似,都是由多个Dense block组成的,在每一个包含n个卷积层的Dense block里面都有(1+(N-1))*((N-1)/2)个连接。再来说说每一层网络连接的细节:(1)在图像的卷积网络中一般k个kernel会生成k个feature map,但是在这里略有区别。因为这里的kernel并非等长的,而是与word embedding的长度相同,因此每个kernel与原来的mxd维(m个词d维)的矩阵相乘都会得到一个mx1的向量,相当于一个kernel就是一个word embedding的一维,因此k个kernel即生成了k个mx1的向量(word embedding的k维),将这些向量拼接在一起便形成了一个大的mxk维的feature map。这与图像中的有些不同,相当于将图像中的k个feature map(也即channel)拼接在了一起。(2)skip connection如何连接?每个skip connection 都会有一个kernel与之相乘,得到一个mxk的feature map,然后将这些所有的connection计算得到的feature map按位(element-wise)相加,便得到了我们的输出feature map;
- Attention module. 注意力机制应用在CNN结构的最后,其作用是将前面所有层的特征进行加权,已得到最后分类层的输出向量。具体地,Attention module包括两步:filter ensemble和scale reweight。(1)filter ensemble,这一步会生成一个mxL维(L表示CNN层数)的注意力矩阵 s,其表示的是对于最后输出的mxk中的m行中每一行("单词"表示),所有CNN层的对应行的权重占有多少。举例来说s11表示最后mxk的feature map中的第1行有多少(权重)来自于第1层CNN的第1行(对应的行),而s23表示最后mxk的feature map中的第2行有多少(权重)来自于第3层CNN的第2行(对应行)。其值得sij的值计算也非常简单,直接等于某一个单词的k为数值相加即可,也即s23的值等于第2层的第3行的k个数值相加得到。如此,我们便得到了我们的未归一化的Attention权重矩阵。(2)scale reweight。这一步通过一个softmax(MLP)来对输出进行归一化,得到最后的对于每个单词的最后的各CNN层的权重。
- 第三部分就是一个非常简单的全连接分类层了。
本文通过Dense connection + Attention来自动获取对于文本语义最重要的n-gram特征,结果很好。但是缺点是,这个网络比较适合较短的文本,文中对输入文本进行了padding补齐,对于不同数据集最大长度分别为50,100等,但这对于较长的文本明显是不足的。因此对于较长的文本或许HAN这种借用RNN来不限制输入长短的网络会更好。
《Recurrent Convolutional Neural Networks for Text Classification》

本文提出了一种结合循环神经网络(RNN)和卷积神经网络来进行文本分类的方法,其结构如上图所示,该网络可以分为三部分:
- 第一部分利用一个双向RNN网络来提取各个单词及其上下文的表示。具体地,cli表示某个单词的左侧语句信息,其等于上一个单词的左侧信息cli-1加上上一个单词的embedding表示ei-1。右侧语句信息cr也可通过相同方法计算得到,只不过RNN的方向相反而已。如此便可得到每个单词的上下文信息,将上下文信息与单词的embedding合并起来便可以得到此单词的语义了,即yi;
- 第二部分是一个卷积网络中的maxpooling层,对于上面得到的各个单词的语义表示,进行一个相当于channel-wise的maxpooling,也即取各个单词的同一个维度上面的最大值,这样可以将不同长度的文本缩放到同一维度大小的特征;
- 第三部分是一个softmax输出层。
虽然说是RNN与CNN的结合,但是其实只用到了CNN中的pooling,多少有一点噱头的意思。文中还提到了RCNN为什么比CNN效果好的原因,即为什么RCNN能比CNN更好的捕捉到上下文信息:CNN使用了固定大小window(也即kernel size)来提取上下文信息,其实就是一个n-gram。因此CNN的表现很大程度上受window大小的影响,太小了会丢失一些长距离信息,太大了又会导致稀疏性问题,而且会增加计算量。
《Recurrent Neural Network for Text Classification with Multi-Task Learning》

在众多自然语言处理任务中,一个非常突出的问题就是训练数据不足,且标注难度大。因此文本提出了一种多任务共享的RNN模型框架,其使用多个不同任务数据集来训练同一个模型共享参数,已达到扩充数据集的作用。
文中作者提出了三个模型,如上图所示:
- 第一个模型与一般的LSTM模型基本相同,只是在输入端每个单词用了两个两个embedding,一个是共享的,一个是各个任务的数据训练出来的;
- 第二个模型可以看作一个使用了一个两层LSTM的模型,其中每层LSTM作为一个特定任务的参数层,其中两个LSTM层的隐藏层数据又是可以相互交流的,因此充分利用了不同任务的数据;
- 第三个模型使用了三个LSTM层,相比于第二个模型通过隐藏层进行非线性变换后的数据进行交流,第三个模型直接使用了一个中间层来作为共享参数层,其每个任务的数据都可以直接作为这一层LSTM的输入,然后通过共享层的隐藏层进行数据交流。
三个模型的训练方式相同:
- 1、先随机选择一个分类任务及其数据集;
- 2、从此训练集中随机选择一个样本进行训练;
- 3、重复1、2步。
- 4、最后在实际应用于分类时,可以使用特定任务的数据进行继续训练微调一下以达到更好的效果。
《Hierarchical Attention Networks for Document Classification》
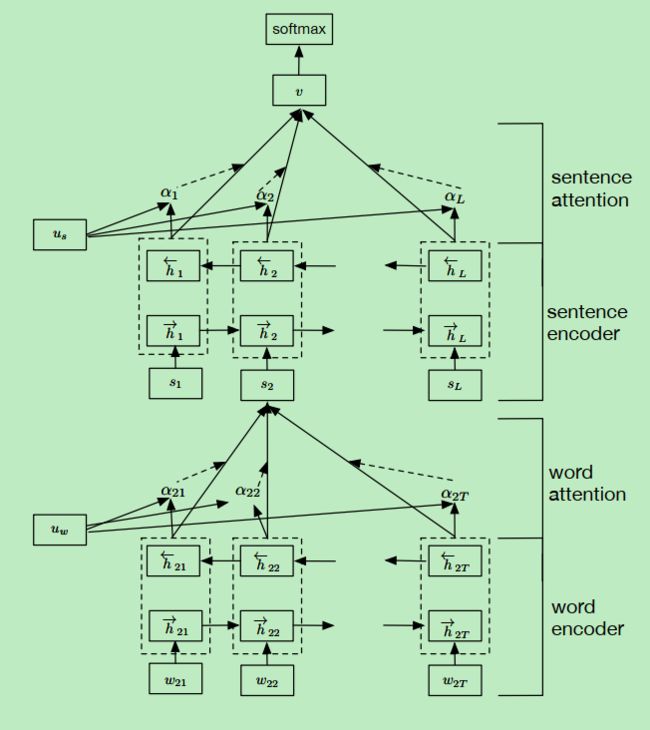
本文提出了一个层次LSTM+Attention模型。作者认为,虽然一篇文章有多个句子组成但真正其关键作用的可能是其中的某几个,因此对各个句子施加了注意力机制,以使得对文章语义贡献较多的句子占有更多的权重。同样的,组成一个句子的单词有多个,但是发挥重要作用的可能就那么几个,因此使用注意力机制以使得重要单词发挥更大的作用,这些便是本文的核心思想。整个网络可分为三层,两个LSTM层分别用来进行word encode和sentence encode,最顶上为一个全连接分类层。若加上两层注意力层,则可认为网络为5层。下面简单聊聊这五层网络的结构:
- 首先是最底层为word encoder层,网络是一个双向LSTM,其输入自然是一个句子的所有词word embedding,双向LSTM(word encoder)用来学习得到句子中各个单词的表示。这个word encoder是用来学习得到各个单词在某个特定上下文中的语义,也即在word embedding的基础上添加了上下文信息。需要注意的是,在整个网络中这样的word encoder的数量是文章句子数量一致的,有几个句子便需要几个word encoder(抑或是所有句子的word encoder都共用一个双向LSTM?貌似这种可能较大,也更容易实现)。这一层的输出是每个单词在双向LSTM中正向和反向输出的拼接
- 往上走就是word Attention层了,这一层是对一个句子的所有单词进行加权以生成一个句子的语义表示。具体地想通过一个MLP层(即全连接层)所有的单词表示相乘以更进一步地得到各个单词的表示uit,与通过一个矩阵uw与句子中所有的单词表示uit相乘softmax归一化以得到各个单词的打分。矩阵uw的意思可以理解为找出那个贡献更多信息的单词并给与更高的权重。最后通过对句子中各个单词加权相加以得到各个句子的表示;
- 第三层是sentence encoder层,其结构与word encoder层相同,作用是用来对句子表示进一步学习表示,加入句子的上下文语义,学习得到其在整个文章中的语义,因此不再赘述;
- 第四层是一个sentence Attention层,其计算方式也与word Attention层的计算方式相同,最后得到各个句子的权重后进行加权便得到了整个文章的向量表示v;
- 第五层便是最后的分类层了,就是一个全连接层,也没有太多需要说的东西。
总体来说,本文看起来还是比较有意思的,符合人阅读文章的习惯,我们写文章的时候也是有中心词和中心句的。但是由于这个层级结构是否会导致训练慢或者不好训练还不得而知。最后,文中还提出对文章按长短先进行排序,长度相似的进入一个batch,这将训练速度加快了3倍。
《Graph Convolutional Networks for Text Classification》
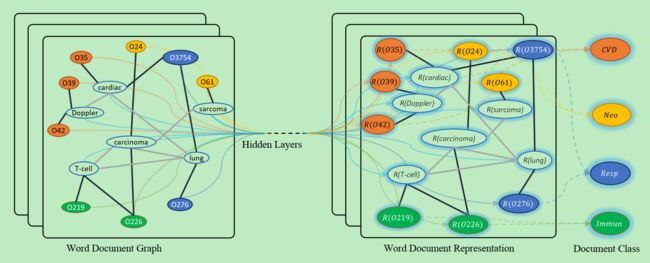
本文提出了一个基于图神经网络的文本分类方法。该方法的主要思想是将所有文章及其包含的词汇都放到一个图网络里面去,图网络中的节点分为两种类型:单词节点和文章节点。其中连接单词节点和文章节点的边的权重使用TF-IDF来表示,而单词与单词之间边的权重则是使用点互信息(PMI)来表示。点互信息与传统语言模型中的条件概率计算方式非常相似。只不过PMI采用的是滑窗方式而条件概率是直接在所有语料中进行统计,可以认为是将所有语料当做一个大窗口,这时就又与PMI相同了。
A表示图网络的邻接矩阵,表示如下:

GCN同样也是可以含有多层隐藏层的,其各个层的计算方式如下:

其中A'为归一化对称邻接矩阵, W0 ∈ R^(m×k) 为权重矩阵,ρ是激活函数,例如 ReLU ρ(x) = max(0,x) 如前所述,可以通过叠加多个GCN层来合并更高阶的邻域信息:
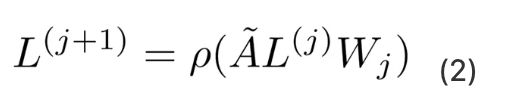
其中j表示层数。
损失函数定义为所有已标记文档的交叉熵误差:
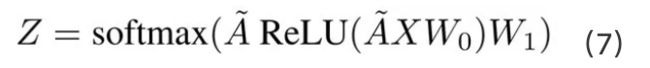
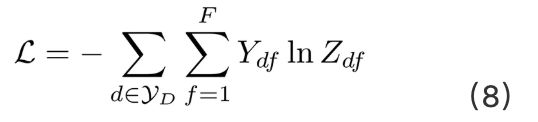
文中提到Text GCN运行良好的原因有两个方面:
- (1)文本图可以同时捕捉文档和单词之间、全局的词与词之间的联系;
- (2)GCN模型作为拉普拉斯平滑的一种特殊形式,将节点的新特征计算为其自身及其二阶邻域的加权平均。
但是其也有一些缺:
- (1)图网络这种表示方式丢失了语序信息,有时候这种信息是非常重要的;
- (2)Text GCN训练的时候是将测试集(不要label)一起放入图网络进行训练的,倘若来了新的数据又需要重新建立网络再次训练。文中提到可能的解决方法是引入归纳或快速GCN模型。
总的来说,文章的idea还是挺有意思的,效果也还不错。初识GCN可能还是有一点难以理解,可以参考如下资料进行进一步学习:
基于图卷积网络的文本分类算法
如何理解 Graph Convolutional Network(GCN)?