写在最前面,本文大部分内容来自Fast R-CNN-晓雷的文章

在R-CNN中,Ross Girshick提出使用卷积网络来替代传统的提取图像特征的方法,大大提高了目标检测的性能。而在Fast R-CNN中,Ross Girshick大神继续提出改进,利用一个网络的多任务学习不仅将R-CNN中的三段式系统(即提取候选框特征,SVM分类,候选框坐标精修)合在了一个网络中,还借鉴SPPnet的思想,共享同一张图片的卷积计算,大大缩短了检测时间。而在Faster R-CNN中,针对R-CNN、Fast R-CNN中留下来的问题,同时也是Fast R-CNN检测时间限制的瓶颈所在——如何获取候选框(region proposals)。Shaoqing Ren提出了一个专门寻找候选框的网络RPN(region proposals Network),并将其与Fast R-CNN中的检测网络整合在一起,最后形成了一个端到端的检测网络。在本篇将对Faster R-CNN作简单的介绍。
Region Proposal Networks (RPN)
关于候选框(region proposal bounding boxes)生成有很多现成的算法,广泛使用的候选框生成算法包括基于超像素分组(如选择性搜索,CPMC,MCG)和那些基于滑动窗口的方法(如EdgeBoxes)。但是目前候选框生成基本都是独立于目标检测器的一个独立模块(R-CNN和Fast R-CNN中的选择性搜索生成候选框都是独立于检测部分存在的)。
在Faster R-CNN中,作者提出了一个一体化的端到端的目标检测网络。这个网络主要包括两部分,第一个是生成目标候选框的全卷积网络(RPN),另一部分是与Fast R-CNN中相同的检测网络,其中RPN和检测网络部分可以共享网络前面的卷积计算。如下图所示:
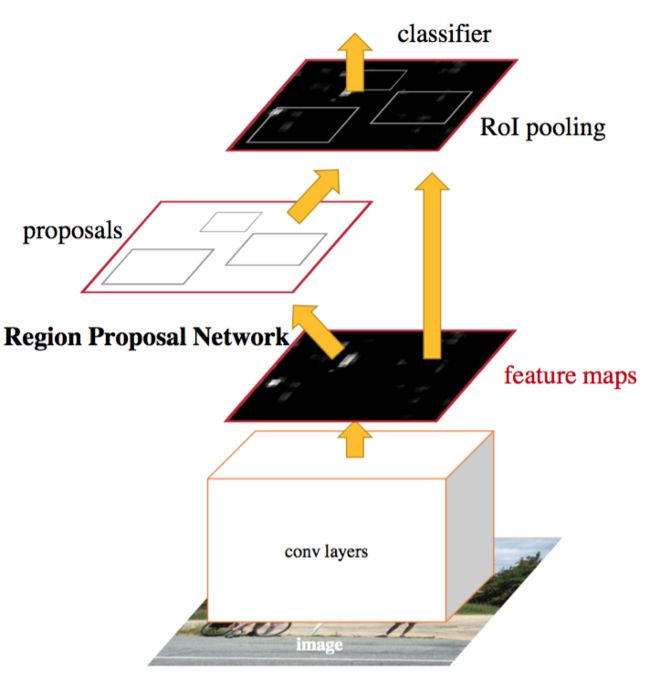
RPN借鉴了SPPnet 的空间金字塔池化和Fast R-CNN Roi池化中从feature map上直接生成候选框的方法。先通过对应关系(高维)feature map的点映射回原图上(参看: 原始图片中的ROI如何映射到到feature map?),在每一个对应的原图设计不同的anchor box,训练RPN时根据anchor box与ground truth的IoU给它正负标签,进行学习。
生成anchor boxes
由于我们只需要找出大致的地方,无论是精确定位位置还是尺寸,后面的工作都可以完成,作者对bbox做了三个固定:固定尺度变化(三种尺度),固定scale ratio变化(三种ratio),固定采样方式(只在feature map的每个点在原图中的对应ROI上采样,反正后面的工作能进行调整) 。如此就可以降低任务复杂度。
可以在特征图上提取proposal之后,网络前面就可以共享卷积计算结果(SPP减少计算量的思想)。这个网络的结果就是卷积层的每个点都有有关于k个achor boxes的输出,包括是不是物体,调整box相应的位置。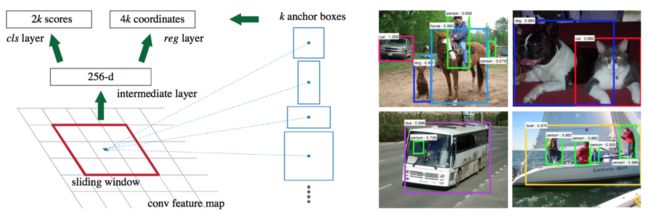
具体过程:
- 得到最终用来预测的feature map:图片在输入网络后,经过一系列的卷积核池化后,最后会得到一个feature map,无论是SPPnet还是Fast R-CNN都是从这个feature map上来提取proposal的;
- 计算anchor boxes:在feature map上进行滑窗(sliding window),文章滑窗的大小是3x3,将这3x3的滑窗的中心作为anchor box的中心,围绕这个中心选取k个不同scale、aspect ratio的anchor boxes。论文中使用了3个scale(3种面积{128x128, 256x256,512x512}),3个纵横比(aspect ratio){1:1, 1:2, 2:1},即每次滑动产生9个anchor boxes。
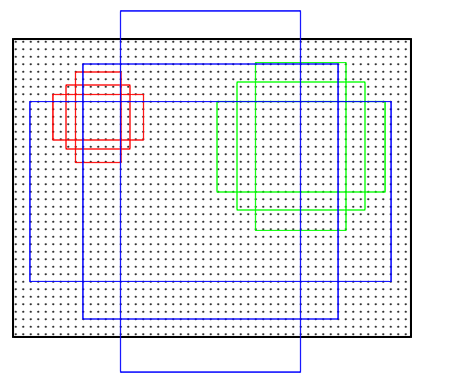
多尺度预测主要有两种方法:第一种方法是基于图像/特征金字塔,图像在多个尺度上进行缩放,并针对每个尺度计算特征映射。这种方法通常是有效的,但也是非常耗时的。第二种方法是在特征映射上使用多尺度(和/或长宽比)的滑动窗口,如DPM使用不同的滤波器大小(如7x5和5x7)分别对不同长宽比的模型进行训练。如果使用这种方法来解决多尺度问题,可以将其看作是一个‘滤波器金字塔’。第二种方法通常和第一种方法联合使用。
而文章中基于锚点(anchor)建立的锚点金字塔更加高效。该方法参照多尺度和长宽比的anchor boxes来分类和回归边界框。它只依赖单一尺度的图像和特征映射,并使用单一尺寸的滤波器(特征映射上的滑动窗口)。实验结果显示这种解决多尺度和尺寸的方法是非常有效的。
注意:
- 在到达全连接层之前,卷积层和Pooling层对图片输入大小其实没有size的限制,因此RCNN系列的网络模型其实是不需要实现把图片resize到固定大小的;
- n=3看起来很小,但是要考虑到这是非常高层的feature map,其size本身也没有多大,因此 3×33×3 9个矩形中,每个矩形窗框都是可以感知到很大范围的。
关于RPN训练时正负样本的划分
考察训练集中的每张图像的所有anchor box和ground truth的关系:
- a. 对每个标定的ground truth区域,与其重叠比例最大的anchor box记为正样本(确保每个ground truth至少对应一个正样本anchor);
- b. 对于(a)中剩余的anchor,如果与其某个标定区域重叠比例大于0.7,记为正样本(每个ground true box可能会对应多个正样本anchor。但每个正样本anchor 只可能对应一个grand true box);如果其与任意一个标定的重叠比例都小于0.3,记为负样本。
- c. 对于(a)(b)剩余的anchor,弃去不用;
-
d. 跨越图像边界的anchor弃去不用。
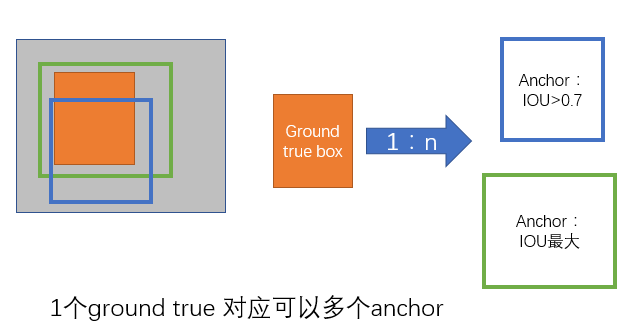 图片来自https://zhuanlan.zhihu.com/p/24916624
图片来自https://zhuanlan.zhihu.com/p/24916624
RPN损失函数
对于每个anchor,首先在后面接上一个二分类softmax,有2个score输出对这个anchor box是否包含物体的概率进行打分(pi),然后再接上一个bounding box的regressor输出代表这个anchor的4个位置(ti),因此RPN的总体loss函数可以定义为
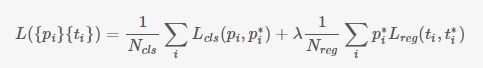
loss第二项前面的系数p*i 表示这些regressor的loss指针对正样本而言,因为负样本时其概率为该项被消去。
其中i表示第i个anchor,当anchor是正样本时p*i =1 ,是负样本则为0 。t*i =1表示 一个与正样本anchor 相关的ground true box 坐标 (每个正样本anchor 只可能对应一个ground true box: 一个正样本anchor 与某个grand true box对应,那么该anchor与ground true box 的IOU要么是所有anchor中最大,要么大于0.7);
x,y,w,h分别表示box的中心坐标和宽高,x, xa, t*i 分别表示 predicted box, anchor box, and ground truth box (y,w,h同理)。ti表示predict box相对于anchor box的偏移, t*i表示ground true box相对于anchor box的偏移,学习目标自然就是让前者接近后者的值。
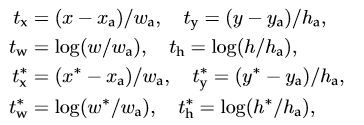

其中L reg是:


RPN训练
如果对每幅图的所有anchor都去优化loss function,那么最终会因为负样本过多导致最终得到的模型对正样本预测准确率很低。因此,在每幅图像中随机采样256个anchor boxes去参与计算一次mini-batch的损失。正负比例1:1(若正样本不足128个则以负样本作为补充)
RPN和Fast R-CNN共享特征
在上面已经解决了如何使用卷积网络来生成region proposals,但是上面进行训练的时候是单独的RPN进行训练的,还没有将RPN与Fast R-CNN的检测网络结合起来。如何将这两个网络结合起来并使其共享前面的特征计算层是一个非常关键的问题。下面我们来看看如何将这两个网络合并起来训练使其共享图像特征的卷积计算。文中提出了三种方式:
1、Alternating training
此方法其实就是一个不断迭代的训练过程,既然分别训练RPN和Fast-RCNN可能让网络朝不同的方向收敛,a)那么我们可以先独立训练RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出proposal作为此时Fast-RCNN的输入训练Fast R-CNN。b) 用Fast R-CNN的网络参数去初始化RPN。之后不断迭代这个过程,即循环训练RPN、Fast-RCNN。在本文中使用的训练方法就是基于这个迭代训练。

2、Approximate joint training
这里与前一种方法不同,不再是串行训练RPN和Fast-RCNN,而是尝试把二者融入到一个网络内,具体融合的网络结构如下图所示,可以看到,proposals是由中间的RPN层输出的,而不是从网络外部得到。需要注意的一点,名字中的"approximate"是因为反向传播阶段RPN产生的cls score能够获得梯度用以更新参数,但是proposal的坐标预测则直接把梯度舍弃了,这样使得该网络反向传播时只能得到一个近似解,但是这种方式相对于Alternating training减少了25-50%的训练时间。

3、Non-approximate training
上面的Approximate joint training把proposal的坐标预测梯度直接舍弃,所以被称作approximate,那么理论上如果不舍弃是不是能更好的提升RPN部分网络的性能呢?作者把这种训练方式称为“ Non-approximate joint training”。在本文中作者只提及但并没有实现这种方法。
虽然提到了3中可能的方法,但是作者实际用的其实是一个4步训练法,思路与Alternating training类似,但是细节略有差别:
- 第一步:使用ImageNet预训练模型初始化训练一个RPN网络;
- 第二步:依然使用ImageNet预训练模型初始化来训练Fast R-CNN检测网络,但是此时的输入是RPN网络产生的region proposals,到这里我们训练了两个网络——RPN网络和Fast R-CNN检测网络,这两个网络现在参数不共享;
- 第三步:使用第二步的Fast R-CNN网络参数来初始化一个新的RPN模型,但在这里把RPN、Fast R-CNN共享的卷积层的学习率设置为0,即不更新这些共享网络层。这一步仅更新RPN特有的那些网络层。这一步训练完,这个时候这个一体化模型中RPN和Fast R-CNN的前面卷积部分已经实现了参数共享;
- 第四步:仍然将两个网络的共享层进行固定,fine-tune Fast R-CNN特有的网络层。至此,一个包含region proposal生成和Fast R-CNN检测两部分的一体化网络已经形成。
-
类似的交替训练可以运行更多的迭代。
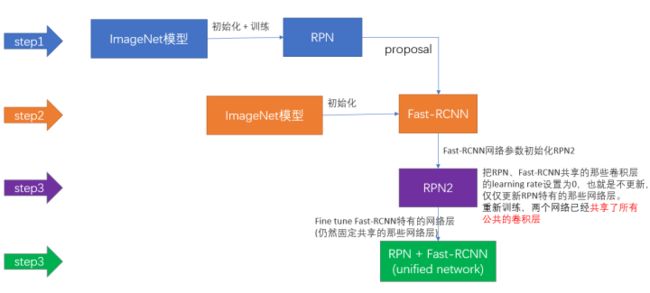 图片来自https://zhuanlan.zhihu.com/p/24916624
图片来自https://zhuanlan.zhihu.com/p/24916624
实验结果
作者在多个数据集上进行测试,检测RPN即文中提出的一体化网络的有效性,结果当然是好,不然也没必要发出来了。
总结
最后做一个简单的总结,在这篇文章总其实一共仅做了两件事,但这两件事都是非常关键的,他使得目标检测的速度得到了几乎上百倍的加速同时还没有降低检测的性能。
1、提出了RPN网络,这个网络与Fast R-CNN共享前面图像特征的卷积计算。其在最后feature map上生成映射到原图的anchor boxes,这些anchor boxes还有效的解决了多尺度问题(通过多尺度anchor box);
2、将RPN网络与Fast R-CNN结合在一起形成一个unified Network(通过文中的4步法进行训练),真正实现了端到端的目标检测。
虽说到这里是对Faster R-CNN有了一个简单的了解,但对其中的细节还是没有理解,譬如RPN提出的anchor box是如何传给Fast R-CNN的,这些实现细节还需要慢慢琢磨。
参考:
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.
Fast R-CNN-晓雷的文章
Faster R-CNN论文翻译——中英文对照