TBase - 专业高效的时序空间数据库
TBase - 专业高效的时序空间数据库
- 时序性的
- 结构化的
- 很少更新或删除
- 一般是按到期日期来删除
- 以写为主,读为辅,
- 有常用的统计和计算操作
- 数据量巨大,一天超过10亿条
- 一般按时间段和区域查找
问题:
- 性能价格比地下
- 采用标准SQL接口
- 运维极其简单是
实现 - 完全无中心设计
- 无锁和多核技术,插入和查询速度10倍
- 集群设计,水平扩展,无单点故障
- 列式存储压缩,不到10%
- 极致用户体验,运维自动化,标准SQL接口。
细节
- 每个设备当作一个用户,每个监测点单独一张表;
- 虚拟化的好处,并发同步(无事务)
- 操作,落盘(日志),副本
- 列文件,自动的切分多个文件?
- 没有Master,是P2P模式
- 连续存放
- 按时间分片
问题:
1,每个表,是否再拆分?——按时间分片
2,列的切分,是否可调整?——创建的时候指定(按时间切分)
3,列式数据库的二级索引问题?——
4,Prometheus(普罗米修斯) ——每个监测点一个文件。(几千个点,差不多,超过几万,文件太多不好管理)
对标产品——
- InfluxDB
- OpenTSDB,http://opentsdb.net/
- Druid(IMPLY)
- Prometheus(SoundCloud),官网:http://prometheus.io/
Prometheus是一个开源的服务监控系统和时序列数据库,由社交音乐平台SoundCloud在2012年开发,最近也变得很流行,最新版本为0.17.0rc2。
- 多维数据模型(时序列数据由metric名和一组key/value组成)
- 灵活的查询语言
- 不依赖分布式存储,单台服务器即可工作
- 通过基于HTTP的pull方式采集是序列数据
- 可以通过中间网关进行时序列数据推送
- 多种可视化和仪表盘支持
- Pinot(Linkedin)
2017-10-05 49岁的程序员 | 作者:陶建辉-涛思数据
2017-10-04 陶建辉 49岁的程序员
钱再多,也难让人在历史上留下痕迹,但一幅好的作品却可以传承,让后人好好的品味。
作者介绍:
陶建辉,94年毕业于中国科大,同年到美国印第安纳大学攻读天体物理博士,曾在美国芝加哥Motorola、3Com等公司从事2.5G、3G、WiFi等无线互联网的研发工作,国际顶尖无线数据专家。连续创业者,成功创办了提供移动互联网的IP Push和IP实时消息服务的和信,和专注于母婴智能硬件和母婴健康服务快乐妈咪。目前第三次创业,创办涛思数据,专注时序空间数据的实时高效的处理,其产品TBase比其他业内标杆数据库性能好10倍以上。
今天10月4日,中秋节,按身份证上的日子算,还正好是我49岁生日。太太带儿子去长春参加全国击剑俱乐部联赛,我独自一人在家。一早起来,习惯性的打开笔记本,翻了翻自己写的代码,顺手做了一个小的优化,让系统配置参数又少了一个。数了数自己的代码行数,发现6个月时间,居然已经写下了3万8千多行代码,这个代码量超过了我在美国工作十年的总和。
从1984年高一的时候开始写Basic语言程序到现在,程序员的生涯已经33年。虽然经常写程序,也喜欢写程序,但从来认为写程序太简单,不值得去专门学,因此大学和研究生念的是流体力学和天体物理。但离开校门,研究宇宙大尺度结构的我,无法靠天体物理养活自己,最终进了Motorola开始职业程序员的生涯。2007年,我还在Motorola上班,觉得移动互联网的春天真要到来,而移动互联网必须要有推送服务,因此应该做一推送平台,提供专业的移动推动服务。2008年初回到北京创办和信,自己写了约3000行代码,实现了一个现在还引以自豪的高效、省电、省流量的移动互联网推送引擎。2013年初看到智能硬件即将兴起,再次创业,创办快乐妈咪,技术门槛不高,本不想动手写任何一行程序,但研发团队搞不定胎心的计算,最后自己出手,把分析宇宙大尺度结构的方法用上,600来行代码实时准确的计算出胎心率。
在我看来,
程序员写程序,就象画家作画,是在创造作品,如果作品能被人欣赏,那就是最大的回报。
从1984年起,我开发过无数的软件,但最让我得意的是两个,
- 一个是1993年暑假用FoxPro帮姐姐开发的财务软件,20多年后,到今天,姐姐还在使用,打开软件,上面显示的还是“建辉电脑”。
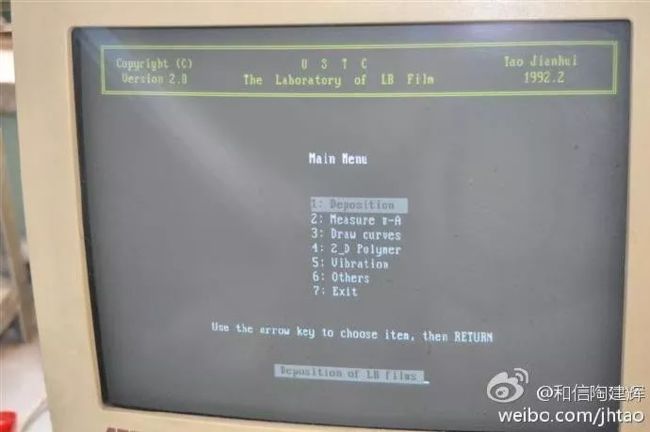
- 还有一个软件,是我在中国科大念书时帮科大高分子LB膜实验室开发的LB膜天平系统,其硬件软件还在天天运行,几百篇SCI论文的数据出自我开发的LB膜天平,现在打开系统,上面清晰的显示着“Tao Jianhui”。
这两个软件,没有让我获得财务上的回报,但是最让我满足,有说不尽的自豪感,因为现在还在用,用的很好。
从念书到工作,一帆风顺,自命不凡,一直以技术高手自居。但一细想,这个技术高手的水分不小,因为世界上任何一款流行的软件,我都不是贡献者。幸运的是,我还没到写不了程序的那一天,仍有机会。
一年前,我发现时序数据库这个细分市场可以大有作为。
- 数据库是底层基础软件,与移动应用和网站类产品不同,更新变化慢,生命周期长,但技术门槛相当高。
- 另外一方面,传统的数据库已经被研究了几十年,各种索引、存储结构都被研究透了,技术上和市场上已经很难有所作为。但由于移动互联网的发展,数据量高速增长,单机已经无法处理,必须依赖集群。
- 数据库的核心技术现在是如何设计分布式系统,处理高并发、高效实时的数据同步、查询、计算了。而我从工作的第一天起,在通讯行业,一直做分布式系统,设计的系统历来都是支持热插拔、在线升级、无单点故障的,这些经验和技术能很好的运用到分布式数据库的设计上,我的知识结构和技能正好吻合,天助我也。因此决定再做一次程序员,开始编写程序。
花了几天时间搭建开发环境,熟悉开发工具后,就真的开干了。接近50的人,本认为与10年前比,效率应该下降不少。但没想到,有了明确的目标后,自己的潜能被完全挖掘出来,从2016年12月中旬起,持续两个月,每天平均工作12小时以上,写下了一万八千多行代码,实现了整个时序数据库的核心引擎。经过简单的对比测试,发现性能指标上远胜MySQL, MongoDB, Cassandra, Influx DB,Open TSDB等数据库,快至少10倍以上。这样的结果让我兴奋不已,决定正式注册公司、融资、组建团队,再一次走在了创业的路上。
获得薛蛮子和明势资本投资后,涛思数据(TAOS Data)6月份正式开张,一下就有了几个人的研发团队,不再是我一个人的战斗。但为保证质量和进度,没想只做指挥和所谓的架构设计,而是与大家一起,又集中精力编写代码。三个月之后,发现自己又贡献了两万行代码,将一个时序空间数据引擎变成了一个可以对外测试的产品TBase,离真正商业化的产品又近了一大步。
过去的十个月时间,几乎天天都在写程序,改BUG。每当解决一个难缠的BUG,总是说不出的高兴,马上请团队一起吃饭。每当又发现一个巧妙的方法,让性能又提高一点,总忍不住马上与团队分享。每当被问题难倒,一定睡不安稳,一定会早早的起来想去解决它。每天十几个小时的开发,没有让我累倒,反而让我回到了20年前,脑子能高速运转起来。如果哪天没写上几行,总觉得还有什么事情没做。两周前在上海参加一个论坛,听着发言的同时,顺手就实现了Naggle算法,还测试通过,立马就有一股强烈的满足感和自豪感。
很庆幸自己一年前的决定,在老去之前,还有机会开发一款顶尖的有相当技术门槛的产品,能把自己多年积累的技术和经验全部用上。而且幸运的是,又再次获得薛蛮子和明势资本的天使投资,组建了一个精干但十分牛气的技术团队。根据TBase目前的测试结果来看,已经胜券在握。无论今后的市场推广如何,无论是开源还是商业化,我相信一定会有不少人喜欢这款产品,品味我设计和编程的美妙之处。如果能象我为姐姐开发的财务软件,为实验室开发的LB膜天平一样,20年之后,还有人在使用TBase的话,那时我一定会是世界上最开心的老头。如果儿子那时自豪的告诉他人,大家用的TBase的核心引擎是我父亲49岁时开发的,那便是我留给他的最大的财富。如果孙子还知道TBase和TAOS Data, 那便是我给他最大的传承。
前面两次创业的经历,让我看够了潮起潮落、云卷云舒。
我最擅长的是写程序,所受的教育、训练能让我在这方面远胜他人,为何要去搞地推、运营、做一些表面红红火火,而不需要任何技术门槛的活呢?还是继续写程序,而且好好的写,用心去写,就像画家一样,用心去创作一幅作品,而不画应酬之作。希望10年后,无论TAOS Data是已经IPO还是小公司一个,我还在积极的为TBase贡献代码,20年后还能参与技术细节的讨论,还能动手解决BUG。我生命的最后一刻,希望还在计算机屏幕前。
钱再多,也难让人在历史上留下痕迹,但一幅好的作品却可以传承,让后人好好的品味。愿我领头开发的TBase成为传世之作,Leave a dent in the world!
2017年10月4日于北京
知乎 时序数据库的选择?
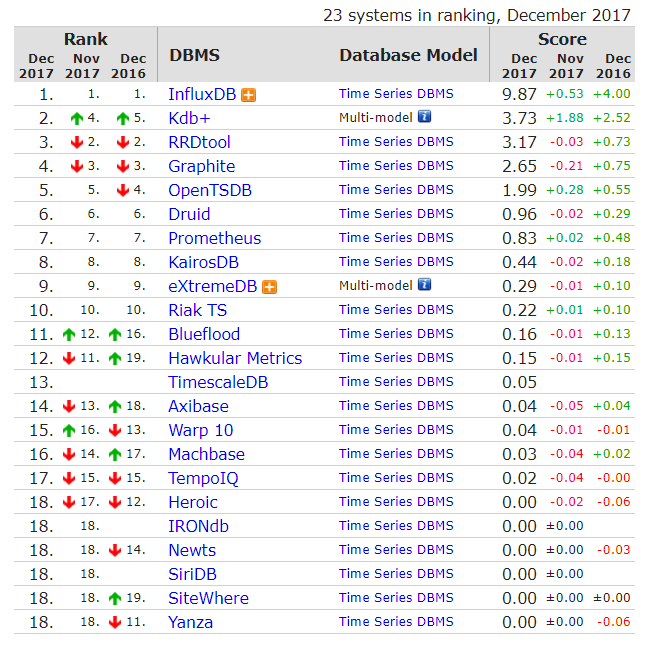
我们最近也在做TSDB的选型,先发一个DB-Engine上的排名供参考吧:
- 序列数据库的排名
有提供一些对比:
- 时序列数据库武斗大会之什么是TSDB
- 时序列数据库武斗大会之TSDB名录 Part 1
- 时序列数据库武斗大会之TSDB名录 Part 2
- 时序列数据库武斗大会之OpenTSDB篇
- 时序列数据库武斗大会之KairosDB篇
- 时间序列数据的存储和计算 - 概述
- 时间序列数据的存储和计算 - 开源时序数据库解析(一)
2015-03-27 Hummer Time Series DB(蜂鸟时序数据库)技术介绍
1 背景介绍
不知不觉中,我们已经跨入“大数据”时代,而大数据的主要来源是来自于各种“传感器”所产生的时序数据记录。这些时序数据不但数量越积越多、而且频率也越来越快,但传统数据库对于这种数目庞大、更新频繁的时序数据,无论存储或检索都难以应对(“存不下”、“查不出”)。因此工业界当前迫切需要一种面向时序数据特征而专门设计的新型时序数据库 —— 蜂鸟时序数据库正是在此背景下,为存储和检索时序数据而研发的分布式数据库。
注 : 取名蜂鸟源自于蜂鸟令人惊叹的挥翅速度。蜂鸟每秒翅膀能挥动15-80次不等。想象一下,蜂鸟本身就犹如一个“传感器”,而翅膀挥动就好比不断产生时序数据。
2 时序数据带来的新挑战
2.1 数据量急剧膨胀
机器(传感器)产生的时序数据量与人手工录入的传统档案类数据量相比,完全不是一个数量级—— 前者百万、千万记录量已触顶,而后者动暨数十亿、数百亿的记录规模。面对如此大量的时序数据,传统数据库既“存不下”,也“查不出”(原因见 2.2/2.3/2.4)。
因此当前业界普遍采用的妥协方案是:
或者只存近期数据(无奈的丢弃老数据),或者只存储一些抽样记录(如: 降频down-sampling到只记录整点数据)。
显然这些方案都无法避免丢弃宝贵数据。在数据为王的时代,谁拥有的数据更多,谁就拥有更强的竞争力,被迫放弃数据实为可惜!
2.2 数据需高速实时导入,且可实时数据获取(ingestin real time)
大量的传感器数据从四面八方、实时涌来(每分钟成千上万,甚至每秒钟成千上万条记录),若想从中找到瞬息万变的“机会”,就需要数据能高速入库,同时还能允许及时查询刚入库的新鲜数据。
但传统数据库在大量随机数据实时写入时,性能欠佳 (入库速度明显不够),更糟的是在入库同时当有并发读操作时,读写性能都将变的更差。
因此当前业界普遍采用的妥协办法是:
延迟入库(如,到晚上无查询业务时再入库新数据),或批量入库(如,每天积攒一批数据再批量入库) —— 这些方法实际上都是为了避免或减少读写混合发生。
显然上述方案肯定会牺牲数据处理的实时性,因此也必然降低了数据的内在“价值”。
2.3 按时间断面(区间)高速检索数据
时序数据最普遍的查询需求是:“在时间断面上,(精确、条件、模糊)检索数据”。
其检索特征更偏向于数据扫描(Scan) —— 而不是传统数据库最擅长的数据定位(seek)。
对于数据量有限的档案数据,传统数据库只需在时间列上和键(key)上建立索引,就得能应这类检索。但不幸的是当时序数据上量后,索引无法继续驻留在内存;更糟的是不断的更新操作(如无序插入)又带来了索引分片(indexfragment)的麻烦。这两点都使得传统数据库在按时段查询时无法顺序扫描目标数据区(磁头需要跳跃寻址),因此传统数据库的查询性能会随时序数据增加和持续更新变的越来越差,而且是指数性下降。
除了时序数规模增长和持续更新对传统数据库索引机制造成冲击外,数据乱序入库对传统索引机制更是灾难 —— 乱序入库是指 : 记录入库顺序并非严格按时间有序(试想多地传感器数据从远程输送来,然后再集中入库。经这个“漫长”过程后,几乎可以肯定数据入库顺序已然不等于数据的发生时间顺序了)。传统数据库在时序数据无序写入的情形下,会造成数据在物理存储上也无序分布。所以即便在时间列上建有索引,按时间断面查询还是无法顺序扫描磁盘,而需要不断seek才能定位数据 —— 我们知道在磁盘上只有顺序读写性能才是最佳,随机读写性能要相差百倍以上。
2.4 数据分析重要性越发突出
时序数据存储的目的有两类:
- 第一是“事故反演、场景回放”;
- 第二是“分析统计和预测”。而分析类需求从简单到复杂可再分为三小类:
- 朴素的统计分析(如多维分析等)?
- 基于移动平均值或者差值的预测分析
- 基于机器学习等的预测和挖掘分析
统计分析离不开SQL和各种聚合函数和窗口函数;而对于预测、挖掘则往往需要借助于Hadoop体系的M/R、BSP等计算框架。
传统数据库对于统计需求,在数据量不大时还算比较擅长,但若要与Hadoop等NOSQL系统配合,则多有不便 —— 或者接口支持不好、或不能最大发挥硬件能力。
2.5 可控的实施成本
时序数据相关业务才刚刚起步,而且多属于运营支撑性业务。相对于一线盈利业务而言其业务价值和技术本身都存在一定风险;另外业务的数据规模也不一定能一步到位,数据往往是由少到多逐步积累,一开始或相当时间内数据量都很有限。鉴于上述实时,我们建议在项目实施开始阶段应尽量控制成本,降低实施风险。
成本控制从技术角度讲最好的选择是:
- 使用普通PC机器,也可用私有云提供的标准虚拟机。
- 先部署有限规模的机器集群(如先满足未来半年数据存储需求)。当业务价值得已证实、数据规模逐步上量后,再对集群进行扩容也不迟(避免初期实施就一步到位,而闲置大量资源)。
上述需求换而言之就是要求:
- 系统在软件层面要做好、做足容错工作(因为普通pc机缺少小型机所具备的硬件容错设备)。传统数据库往往把容错都交给硬件做,不但成本高,而且实际上也不如软件层面更可靠和可控。
- 系统必须有良好的横向扩展能力,即补充同类机器机即可实现自动扩容。而传统数据库初期就要购置昂贵的小机,而且扩容时多是采用纵向扩展方式,即需要用户再购买更高配置的小机代替原先的小型机。
综上所述(2.1-2.5),传统数据库由于设计初衷是应对“档案”数据,而非时序数据,所以面对当前大规模时序数据时,传统数据库就显得捉襟见肘,难以应对了。正是如此,原先并不被业界所重视的“时序数据库”得以快速走向前台,并日渐受到重视和推崇。
时序数据库适用场景
系统运行环境要求
-
体系架构
 image.png
image.png 时序数据存储格式
上述的数据存储格式核心目的都是为了让时序数据在磁盘上“有序存储”,从而按区间扫描时磁头可保证高速顺序移动,并且遍历的数据尽可能少。如果理解了这个准则,那么自然可知上述时序数据格式各自的优缺点了:
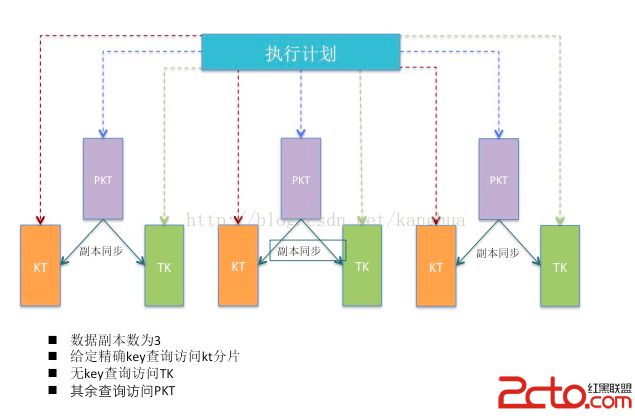
- TK 格式(即 TIMESTAMP-KEY 格式) —— 该格式首先按照事件发生时间排序,当时间相同时,则再按照事件ID(key)排序。具体 Layout 见表 6.1:
- KT 格式(即 KEY-TIMESTAMP 格式) —— 该格式首先按照key排序。当在key相同时,则再按照事件发生时间再排序。具体 Layout 见表 6.2:
- PKT 格式(即 PARTITION-KEY-TIMESTAMP 格式) —— 该格式首先按照时间分区分组排序(其中partition可选择小时、天、月、年等时间单位,其类似传统数据库中的分区概念),在组内首先按照KEY排序,相同KEY再按照事件时间排序。具体 Layout 见表 6.3
- 重要特性和优势
蜂鸟系统的数据存储格式和体系架构决定了蜂鸟系统的最重要的几个特性:
- 面向时序检索和分析优化 ?
- 分布式存储和计算
- 高可用性
-
支持SQL,并扩充时序分析SQL
上述特性将为用户处理大规模时序数据带来显著好处,具体如下。
7.1. 读写性能突出
7.2. 恒时检索(Constant Query Time)
7.3. 实时数据获取(ingest data in real time)
7.4. 支持面向时序的SQL查询
7.5. 节约空间
7.6. 在线离线处理一体化(混合负载支持)
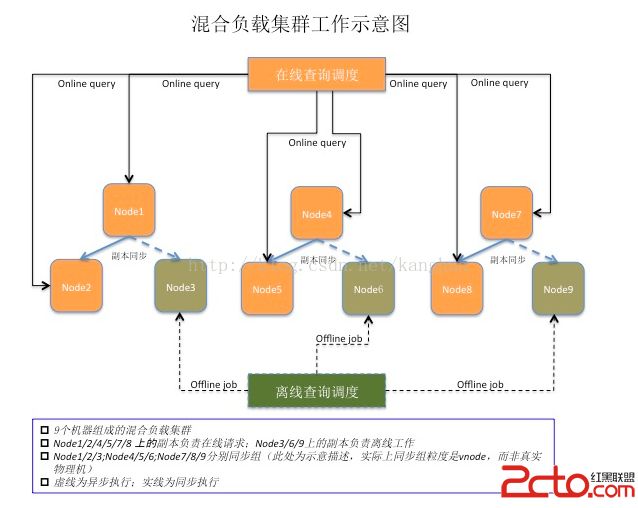 image.png
image.png
7.7. 灵活的数据一致性
7.8. 高可用性和高数据安全性
7.9. 可扩展性优势
7.10. 高并发优势
7.11. 互联互通性
7.12.丰富的分析函数
7.13. 简单易用的管理界面
7.14. 其它优势
- 编程和使用接口
- 竞品分析
9.1主要竞品分析
- Oralce/Mysql/MS-SQL
- Hbase
- Cassandra
- Druid、Geras、InfluxDB、KairosDB、KDB+、OpenTSDB、SiteWhere、TempoDB、TreasureData
- Hive/Impala
- Informix Timeseries
- Oracle xadata
基准测试
最佳实践(实例介绍)
11.1 电力-智能电表相关业务:
11.2 交通-卡口监控相关业务:
11.3 刑侦:通讯记录检索相关业务
https://db-engines.com/en/ranking 总排行
1 1. 1. Oracle detailed information Relational DBMS 1341.54 -18.51 -62.86
2 2. 2. MySQL detailed information Relational DBMS 1318.07 -3.96 -56.34
3 3. 3. Microsoft SQL Server detailed information Relational DBMS 1172.48 -42.59 -54.17
4 4. 4. PostgreSQL detailed information Relational DBMS 385.43 +5.51 +55.41
5 5. 5. MongoDB detailed information Document store 330.77 +0.29 +2.09
6 6. 6. DB2 detailed information Relational DBMS 189.58 -4.48 +5.24
176 up arrow 177. TiDB Relational DBMS 0.52 +0.02
296 up arrow 310. Alibaba Cloud HybridDB Relational DBMS 0.00 ±0.00
296 up arrow 310. Alibaba Cloud MaxCompute Relational DBMS 0.00 ±0.00
296 up arrow 310. Alibaba Cloud Table Store Wide column store 0.00 ±0.00
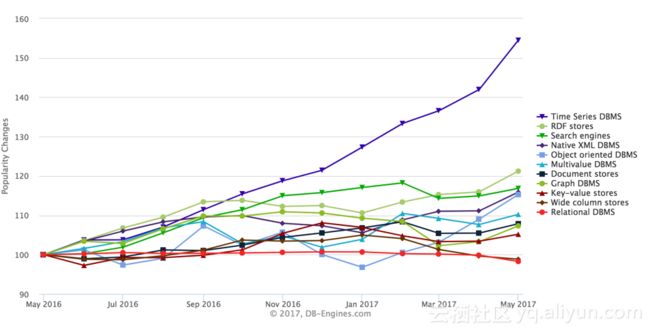
https://yq.aliyun.com/articles/104243 时间序列数据的存储和计算 - 概述
从DB-Engines的数据库类别流行度趋势榜上可以看到,时序数据库(Time Series DB)的流行度在最近的两年内,一直都是保持一个很高的增长趋势。