1. ZooKeeper session建立及超时机制 概述
首先说一下, 为什么要写下这篇, 原因也很简单, 因为session的建立及超时机制特别
1. ZooKeeper 集群的所有 sessionImpl 都在 Leader端, 而Follower端只将 sessionId 与 timeout 存储到 HashMap里面
2. 在 Leader 端 每个 LearnerHandler 会定期的向Follower/Observer发送给ping 包, Follower/Observer在接受到之后, 将会将对应的要检查超时的 sessionId 发给 Leader, 统一让Leader进行检查
3. Leader用SessionTrackerImpl线程来检查Session是否超时, 而 session 将放在一个以 expirationTime为Key的HashMap里面, 定时的获取并检查, 超时的话就进行删除, 不超时的话将session移到下一个将要超时的 Bucket 里面(见touchSession)
接下来就直接上代码(我们这里从Follower的角度出发)
1. Client 连接 Follower
当Client连接Follower时, 会调用 FollowerZooKeeperServer.processPacket 来进行处理(这里不涉及Zookeeper自己的NIO/NettyNIO处理部分), 最后会直接调用 LeaderZooKeeperServer.submitRequest方法将对应的Request进行提交, 到这里有必要说一下 Follower的RequestProcessor处理链
/**
* Follower 的 RequestProcessor 处理链 (2条)
* 第一条 链
* FollowerRequestProcessor: 区分处理 Request, 将 Request 交由下个 RequestProcessor, 而若涉及事务的操作, 则 交由 Follower 提交给 leader (zks.getFollower().request())
* CommitProcessor: 这条链决定这着 Request 能否提交, 里面主要有两条链 , queuedRequests : 存储着 等待 ACK 过半确认的 Request, committedRequests :存储着 已经经过 ACK 过半确认的 Request
* FinalRequestProcessor: 前面的 Request 只是在经过 SynRequestProcessor 持久化到 txnLog 里面, 而 这里做的就是真正的将数据改变到 ZKDataBase 里面(作为 Follower 一定会在 FollowerZooKeeperServer.logRequest 进行同步Request 数据到磁盘里面后再到 FinalRequestProcessor)
*
* 第二条 链
* SynRequestProcessor: 主要是将 Request 持久化到 TxnLog 里面, 其中涉及到 TxnLog 的滚动, 及 Snapshot 文件的生成
* AckRequestProcessor: 主要完成 针对 Request 的 ACK 回复, 对 在Leader中就是完成 leader 自己提交 Request, 自己回复 ACK
*
* 1. FollowerRequestProcessor --> CommitProcessor --> FinalRequestProcessor
* 2. SyncRequestProcessor --> SendAckRequestProcessor
*/
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor, Long.toString(getServerId()), true);
commitProcessor.start();
firstProcessor = new FollowerRequestProcessor(this, commitProcessor);
((FollowerRequestProcessor) firstProcessor).start();
syncProcessor = new SyncRequestProcessor(this, new SendAckRequestProcessor((Learner)getFollower()));
syncProcessor.start();
}
Leader 的RequestProcessor处理链
/**
* Leader 的 RequestProcessor 处理链
*
* 第一条 RequestProcessor 链
* PreRequestProcessor : 创建和修改 TxnRequest
* ProposalRequestProcessor : 提交 Proposal 给各个 Follower 包括 Leader自己 (Leader自己是在 ProposalRequestProcessor 里面通过 syncProcessor.processRequest(request) 直接提交 Proposal)
* CommitProcessor : 将 经过集群中的过半 Proposal 提交(提交的操作直接在 Leader.processAck -> zk.commitProcessor.commit(p.request))
* ToBeAppliedRequestProcessor: 这个处理链其实是 Request 处理时经过的最后一个 RequestProcessor, 其中最令人困惑的是 toBeApplied, 而 toBeApplied 中其实维护的是 集群中经过 过半 ACK 同意的 proposal, 只有经过 FinalRequestProcessor 处理过的 Request 才会在 toBeApplied 中进行删除
* FinalRequestProcessor: 前面的 Request 只是在经过 SynRequestProcessor 持久化到 txnLog 里面, 而 这里做的就是真正的将数据改变到 ZKDataBase 里面
*
* 第二条 RequestProcessor 链
* 在 leader 中, SynRequestProcessor, AckRequestProcessor 的创建其实是在 ProposalRequestProcessor 中完成的
* SynRequestProcessor: 主要是将 Request 持久化到 TxnLog 里面, 其中涉及到 TxnLog 的滚动, 及 Snapshot 文件的生成
* AckRequestProcessor: 主要完成 针对 Request 的 ACK 回复, 对 在Leader中就是完成 leader 自己提交 Request, 自己回复 ACK
*
* PrepRequestProcessor --> ProposalRequestProcessor --> CommitProcessor --> ToBeAppliedRequestProcessor --> FinalRequestProcessor
* \
* SynRequestProcessor --> AckRequestProcessor (这条分支是在 ProposalRequestProcessor 里面进行构建的)
*/
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(
finalProcessor, getLeader().toBeApplied);
// 投票确认处理器
commitProcessor = new CommitProcessor(toBeAppliedProcessor,
Long.toString(getServerId()), false);
commitProcessor.start();
// 投票发起处理器
ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this,
commitProcessor);
proposalProcessor.initialize();
// 预处理器
firstProcessor = new PrepRequestProcessor(this, proposalProcessor);
((PrepRequestProcessor)firstProcessor).start();
}
下面先来张总体的流程图:
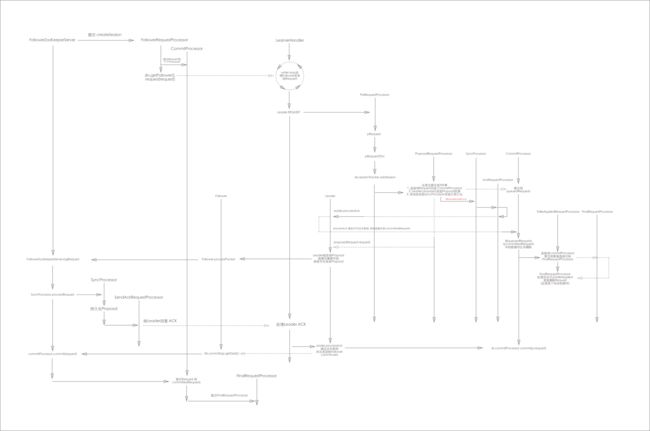
上面这张图片有点大, 建议在 百度云 里面进行下载预览, 接下来我们会一步一步进行下去PS: 吐槽一下的图片系统, 图片一旦大了就预览出问题(不清晰)
整个流程涉及好几个过程, 下面一一分析:
2. FollowerZooKeeperServer createSession
// 创建 session
long createSession(ServerCnxn cnxn, byte passwd[], int timeout) {
long sessionId = sessionTracker.createSession(timeout); // 1. 创建 会话 Session, 生成 SessionImpl 放入对应的 sessionsById, sessionsWithTimeout, sessionSets 里面, 返回 sessionid
Random r = new Random(sessionId ^ superSecret);
r.nextBytes(passwd); // 2. 生成一个随机的 byte[] passwd
ByteBuffer to = ByteBuffer.allocate(4);
to.putInt(timeout);
cnxn.setSessionId(sessionId); // 3. 提交 Request 到RequestProcessor 处理链
submitRequest(cnxn, sessionId, OpCode.createSession, 0, to, null);
return sessionId; // 4. 返回此回话对应的 sessionId
}
3. FinalRequestProcessor 处理请求
switch (request.type) {
case OpCode.sync: // 2. 处理同步数据
zks.pendingSyncs.add(request);
zks.getFollower().request(request);
break;
case OpCode.create: // 3. 从这里 看出 path 创建/删除/设置数据/设置访问权限/创建,关闭session, 多个操作 -> 都 是 Follower 交给 leader 进行处理
case OpCode.delete:
case OpCode.setData:
case OpCode.setACL:
case OpCode.createSession:
case OpCode.closeSession:
case OpCode.multi:
zks.getFollower().request(request); // 4. 将事务类的请求都交给 Leader 处理
break;
}
follower提交 Request 到Leader
/**
* send a request packet to the leader
*
* @param request
* the request from the client
* @throws IOException
*/
void request(Request request) throws IOException {
ByteArrayOutputStream baos = new ByteArrayOutputStream(); // 1. 将要发送给 Leader 的数据包序列化
DataOutputStream oa = new DataOutputStream(baos);
oa.writeLong(request.sessionId);
oa.writeInt(request.cxid);
oa.writeInt(request.type);
if (request.request != null) {
request.request.rewind();
int len = request.request.remaining();
byte b[] = new byte[len];
request.request.get(b);
request.request.rewind();
oa.write(b);
}
oa.close(); // 2. 封装请求数据包
QuorumPacket qp = new QuorumPacket(Leader.REQUEST, -1, baos.toByteArray(), request.authInfo);
writePacket(qp, true); // 3. 将 事务请求 request 发送给 Leader
}
FinalRequestProcessor处理了Request后一方面是follower提交给Leader, 另一方面是提交给 CommitProcessor
4. CommitProcessor 处理请求
@Override
public void run() {
try {
Request nextPending = null;
while (!finished) { // while loop
int len = toProcess.size();
for (int i = 0; i < len; i++) {
Request request = toProcess.get(i);
LOG.info("request:"+ request); // 1. Follower 里面就是 丢给 FinalRequestProcessor 处理
nextProcessor.processRequest(request); // 2. 将 ack 过半的 Request 丢给 ToBeAppliedRequestProcessor 来进行处理 (Leader 中是这样处理)
}
toProcess.clear();
synchronized (this) {
if ((queuedRequests.size() == 0 || nextPending != null)// 3. 如果没有 Commit 的请求, 则进行wait, 直到 commit 请求的到来
&& committedRequests.size() == 0) {
wait();
continue;
}
// First check and see if the commit came in for the pending
// request
if ((queuedRequests.size() == 0 || nextPending != null)// 4. 当 Leader 通过了 过半ACK确认后, 则会将这个 Request 丢给 Follower 来处理, Follower 会直接将 Request 丢到 committedRequests 里面, 进而处理
&& committedRequests.size() > 0) {
Request r = committedRequests.remove();
/*
* We match with nextPending so that we can move to the
* next request when it is committed. We also want to
* use nextPending because it has the cnxn member set
* properly.
*/
if (nextPending != null // 5. 这里其实就是比较 nextPending 与 committedRequests 中的 request 请求
&& nextPending.sessionId == r.sessionId // 6. 而 nextPending 又是从 queuedRequests 里面拿出来的, 若相同, 则直接用 committedRequests 里面的 消息头, 消息体, zxid
&& nextPending.cxid == r.cxid) {
// we want to send our version of the request.
// the pointer to the connection in the request
nextPending.hdr = r.hdr;
nextPending.txn = r.txn;
nextPending.zxid = r.zxid;
toProcess.add(nextPending); // 7. 将 请求 直接加入 toProcess, 直到下次 loop 被 nextProcessor 处理
nextPending = null;
} else { // 8. Leader 直接 调用 commit 方法提交的 请求, 直接加入 toProcess, 直到下次 loop 被 nextProcessor 处理 (这个 IF 判断中是 Leader 中处理的)
// this request came from someone else so just
// send the commit packet
toProcess.add(r);
}
}
}
// We haven't matched the pending requests, so go back to
// waiting
if (nextPending != null) {
continue;
}
synchronized (this) {
// Process the next requests in the queuedRequests
while (nextPending == null && queuedRequests.size() > 0) {
Request request = queuedRequests.remove();
switch (request.type) {
case OpCode.create:
case OpCode.delete:
case OpCode.setData:
case OpCode.multi:
case OpCode.setACL:
case OpCode.createSession:
case OpCode.closeSession:
nextPending = request; // 9. 若请求是事务请求, 则将 follower 自己提交的 request 赋值给 nextPending
break;
case OpCode.sync:
if (matchSyncs) {
nextPending = request;
} else {
toProcess.add(request);
}
break;
default: // 10.这里直接加入到 队列 toProcess 中的其实是 非 事务的请求 (比如getData), 丢到 toProcess 里面的请求会丢到下个 RequestProcessor
toProcess.add(request);
}
}
}
}
} catch (InterruptedException e) {
LOG.warn("Interrupted exception while waiting", e);
} catch (Throwable e) {
LOG.error("Unexpected exception causing CommitProcessor to exit", e);
}
LOG.info("CommitProcessor exited loop!");
}
在CommitProcessor 里面有几个特别的队列
/**
* Requests that we are holding until the commit comes in.
*/
// 等待 ACK 确认的 Request
LinkedList queuedRequests = new LinkedList();
/**
* Requests that have been committed.
*/
// 已经 Proposal ACK 过半确认过的 Request, 一般的要么是 Leader 自己 commit, 要么就是 Follower 接收到 Leader 的 commit 消息
LinkedList committedRequests = new LinkedList();
// 等待被 nextProcessor 处理的队列, 其里面的数据是从 committedRequests, queuedRequests 里面获取来的
ArrayList toProcess = new ArrayList();
5. LearnerHandler 处理Request请求
此时LearnerHandler在while loop里面处理对应的Request请求
while (true) {
qp = new QuorumPacket();
ia.readRecord(qp, "packet"); // 47. 这里其实就是不断的从数据流(来源于 Follower 的) 读取数据
LOG.info("qp:" + qp);
long traceMask = ZooTrace.SERVER_PACKET_TRACE_MASK;
if (qp.getType() == Leader.PING) {
traceMask = ZooTrace.SERVER_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logQuorumPacket(LOG, traceMask, 'i', qp);
}
tickOfNextAckDeadline = leader.self.tick + leader.self.syncLimit;
LOG.info("tickOfNextAckDeadline :" + tickOfNextAckDeadline);
ByteBuffer bb;
long sessionId;
int cxid;
int type;
LOG.info("qp.getType() : " + qp);
switch (qp.getType()) {
case Leader.ACK: // 48. 处理 Follower 回复给 Leader 的ACK 包看看之前的投票是否结束 ( 这里是 Follower 在处理 UPTODATE 后恢复 ACK)
if (this.learnerType == LearnerType.OBSERVER) {
if (LOG.isDebugEnabled()) {
LOG.debug("Received ACK from Observer " + this.sid);
}
}
LOG.info("syncLimitCheck.updateAck(qp.getZxid()):" + qp.getZxid());
syncLimitCheck.updateAck(qp.getZxid());
LOG.info("this.sid:" + this.sid + ", qp.getZxid():" + qp.getZxid() + ", sock.getLocalSocketAddress():" + sock.getLocalSocketAddress());
// 49. ack 包处理成功, 如果 follower 数据同步成功, 则将它添加到 NEWLEADER 这个投票的结果中
leader.processAck(this.sid, qp.getZxid(), sock.getLocalSocketAddress());
break;
case Leader.PING: // 50. ping 数据包, 更新 session 的超时时间
// Process the touches
ByteArrayInputStream bis = new ByteArrayInputStream(qp.getData());
DataInputStream dis = new DataInputStream(bis);
while (dis.available() > 0) {
long sess = dis.readLong();
int to = dis.readInt();
LOG.info("leader.zk.touch: sess" + sess + ", to:"+to);
leader.zk.touch(sess, to);
}
break;
case Leader.REVALIDATE: // 51. 检查 session 是否还存活
bis = new ByteArrayInputStream(qp.getData());
dis = new DataInputStream(bis);
long id = dis.readLong();
int to = dis.readInt();
LOG.info("id:"+id + ", to:" + to);
ByteArrayOutputStream bos = new ByteArrayOutputStream();
DataOutputStream dos = new DataOutputStream(bos);
dos.writeLong(id);
boolean valid = leader.zk.touch(id, to);
LOG.info("id:" + id + ", to:" + to + ", valid:" + valid);
if (valid) {
try {
//set the session owner
// as the follower that
// owns the session
leader.zk.setOwner(id, this);
} catch (SessionExpiredException e) {
LOG.error("Somehow session " + Long.toHexString(id) + " expired right after being renewed! (impossible)", e);
}
}
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(LOG,
ZooTrace.SESSION_TRACE_MASK,
"Session 0x" + Long.toHexString(id)
+ " is valid: "+ valid);
}
dos.writeBoolean(valid);
qp.setData(bos.toByteArray());
queuedPackets.add(qp); // 52. 将数据包返回给对应的 follower
break;
case Leader.REQUEST: // 53. REQUEST 数据包, follower 会将事务请求转发给 leader 进行处理
bb = ByteBuffer.wrap(qp.getData());
sessionId = bb.getLong();
cxid = bb.getInt();
type = bb.getInt();
bb = bb.slice(); // 54. 读取事务信息
Request si;
LOG.info(" sessionId:" + sessionId + ", cxid:" + cxid + ", type:" + type);
if(type == OpCode.sync){
si = new LearnerSyncRequest(this, sessionId, cxid, type, bb, qp.getAuthinfo());
} else {
si = new Request(null, sessionId, cxid, type, bb, qp.getAuthinfo());
}
si.setOwner(this);
LOG.info("si:" + si);
leader.zk.submitRequest(si); // 55. 将事务请求的信息交由 Leader 的 RequestProcessor 处理
break;
default:
}
}
LearnerHandler调用Leader.zk.submitRequest(Request request) 到RequestProcessor处理链里面;
6. PrepRequestProcessor 处理请求
case OpCode.createSession: // 创建 session
request.request.rewind();
int to = request.request.getInt();
request.txn = new CreateSessionTxn(to); // 组装事务体, 事务头在最前面已经弄好了
request.request.rewind();
zks.sessionTracker.addSession(request.sessionId, to); // 调用 sessionTracker.addSession() 将follower里的session加入到Leader的sessionsWithTimeout里面
zks.setOwner(request.sessionId, request.getOwner());
break;
这里的操作就是将session加入到Leader的sessionsById里面
7. ProposalRequestProcessor 处理请求
nextProcessor.processRequest(request); // 1. 这里的 nextProcessor 其实就是 CommitProcessor
if (request.hdr != null) { // 2. 若是 事务请求
// We need to sync and get consensus on any transactions
try {
zks.getLeader().propose(request); // 3. Leader 进行 Request 的投票 (Proposal) 将 request 发送给 Follower
} catch (XidRolloverException e) {
throw new RequestProcessorException(e.getMessage(), e);
}
syncProcessor.processRequest(request); // 4. 将 request 交给 syncProcessor 进行落磁盘
}
这里就这几步:
1. 提交请求到CommitProcessor.queuedRequests里面
2. 通过zks.getLeader().propose(request) 向各个Follower提交 Leader.PROPOSAL
3. 本机的 syncProcessor处理请求(持久化, 接下来就是本机的 AckRequestProcessor回复ack给 Leader.processAck 阻塞这里, ACK过半了就不会阻塞)
8. Follower.processPacket 处理请求
接着就是 Follower处理Leader提出的Proposal
case Leader.PROPOSAL: // 1. 处理 Leader 发来的 Proposal 包, 投票处理
TxnHeader hdr = new TxnHeader();
Record txn = SerializeUtils.deserializeTxn(qp.getData(), hdr);// 2. 反序列化出 Request
if (hdr.getZxid() != lastQueued + 1) { // 3. 这里说明什么呢, 说明 Follower 可能少掉了 Proposal
LOG.warn("Got zxid 0x"
+ Long.toHexString(hdr.getZxid())
+ " expected 0x"
+ Long.toHexString(lastQueued + 1));
}
lastQueued = hdr.getZxid();
fzk.logRequest(hdr, txn); // 4. 将 Request 交给 FollowerZooKeeperServer 来进行处理
fzk.logRequest 提交Request到syncProcessor里面, 而后就是通过SendAckRequestProcessor向Leader发送刚才Proposal对应的ack
9. Leader.processAck 处理Follower发来的ack
/**
* 参考资料
* http://blog.csdn.net/vinowan/article/details/22196707
*
* Keep a count of acks that are received by the leader for a particular
* proposal
*
* @param zxid the zxid of the proposal sent out
*/
synchronized public void processAck(long sid, long zxid, SocketAddress followerAddr) {
LOG.info("sid:" + sid + ", zxid:" + zxid + ", followerAddr:" + followerAddr);
if (LOG.isTraceEnabled()) {
LOG.trace("Ack zxid: 0x{}", Long.toHexString(zxid));
for (Proposal p : outstandingProposals.values()) {
long packetZxid = p.packet.getZxid();
LOG.trace("outstanding proposal: 0x{}",
Long.toHexString(packetZxid));
}
LOG.trace("outstanding proposals all");
}
LOG.info("(zxid & 0xffffffffL) == 0 :" + ((zxid & 0xffffffffL) == 0));
if ((zxid & 0xffffffffL) == 0) { // 1. zxid 全是 0
/*
* We no longer process NEWLEADER ack by this method. However,
* the learner sends ack back to the leader after it gets UPTODATE
* so we just ignore the message.
*/
return;
}
LOG.info("outstandingProposals :" + outstandingProposals);
if (outstandingProposals.size() == 0) { // 2. 没有要回应 ack 的 Proposal 存在
if (LOG.isDebugEnabled()) {
LOG.debug("outstanding is 0");
}
return;
}
LOG.info("lastCommitted :" + lastCommitted + ", zxid:" + zxid);
if (lastCommitted >= zxid) { // 3. Leader 端处理的 lastCommited >= zxid, 说明 zxid 对应的 proposal 已经处理过了
if (LOG.isDebugEnabled()) {
LOG.debug("proposal has already been committed, pzxid: 0x{} zxid: 0x{}", Long.toHexString(lastCommitted), Long.toHexString(zxid));
}
// The proposal has already been committed
return;
}
Proposal p = outstandingProposals.get(zxid); // 4. 从投票箱 outstandingProposals 获取 zxid 对应的 Proposal
LOG.info("p:" + p);
if (p == null) {
LOG.warn("Trying to commit future proposal: zxid 0x{} from {}", Long.toHexString(zxid), followerAddr);
return;
}
LOG.info("p:" + p + ", sid:" + sid);
p.ackSet.add(sid); // 5. 将 follower 的 myid 加入结果列表
if (LOG.isDebugEnabled()) {
LOG.info("Count for zxid: 0x{} is {}", Long.toHexString(zxid), p.ackSet.size());
}
LOG.info("self.getQuorumVerifier().containsQuorum(p.ackSet):" + self.getQuorumVerifier().containsQuorum(p.ackSet));
if (self.getQuorumVerifier().containsQuorum(p.ackSet)){ // 6. 判断是否票数够了, 则启动 leader 的 CommitProcessor 来进行处理
LOG.info("zxid:" + zxid + ", lastCommitted:" + lastCommitted);
if (zxid != lastCommitted+1) {
LOG.warn("Commiting zxid 0x{} from {} not first!", Long.toHexString(zxid), followerAddr);
LOG.warn("First is 0x{}", Long.toHexString(lastCommitted + 1));
}
LOG.info("outstandingProposals:" + outstandingProposals);
outstandingProposals.remove(zxid); // 7. 从 outstandingProposals 里面删除那个可以提交的 Proposal
if (p.request != null) {
toBeApplied.add(p); // 8. 加入到 toBeApplied 队列里面, 这里的 toBeApplied 是 ToBeAppliedRequestProcessor, Leader 共用的队列, 在经过 CommitProcessor 处理过后, 就到 ToBeAppliedRequestProcessor 里面进行处理
LOG.info("toBeApplied:" + toBeApplied); // 9. toBeApplied 对应的删除操作在 ToBeAppliedRequestProcessor 里面, 在进行删除时, 其实已经经过 FinalRequestProcessor 处理过的
}
if (p.request == null) {
LOG.warn("Going to commmit null request for proposal: {}", p);
}
commit(zxid); // 10. 向 集群中的 Followers 发送 commit 消息, 来通知大家, zxid 对应的 Proposal 可以 commit 了
inform(p); // 11. 向 集群中的 Observers 发送 commit 消息, 来通知大家, zxid 对应的 Proposal 可以 commit 了
zk.commitProcessor.commit(p.request); // 12. 自己进行 proposal 的提交 (直接调用 commitProcessor 进行提交 )
// 13. 其实这里隐藏一个细节, 就是有可能 有些 Proposal 在 Follower 上进行了 commit, 而 Leader 上还没来得及提交, 就有可能与集群间的其他节点断开连接
LOG.info("pendingSyncs :" + pendingSyncs);
if(pendingSyncs.containsKey(zxid)){
for(LearnerSyncRequest r: pendingSyncs.remove(zxid)) {
sendSync(r);
}
}
}
}
这里处理ACK时, 若已经收到集群中过半的ack则就可以向集群中的其他节点发送commit, 或inform其他Observer节点, 然后 zk.commitProcessor.commit(p.request) 提交request到Leader的commitProcessor.committedRequests里面, 最后就是 先在FinalRequestProcessor处理一下, 再在ToBeAppliedRequestProcessor.toBeApplied删除request
10. FollowerZooKeeperServer.commit(long zxid) 提交Proposal
/**
* When a COMMIT message is received, eventually this method is called,
* which matches up the zxid from the COMMIT with (hopefully) the head of
* the pendingTxns queue and hands it to the commitProcessor to commit.
* @param zxid - must correspond to the head of pendingTxns if it exists
*/
public void commit(long zxid) {
if (pendingTxns.size() == 0) {
LOG.warn("Committing " + Long.toHexString(zxid)
+ " without seeing txn");
return;
}
long firstElementZxid = pendingTxns.element().zxid; // 1. http://blog.csdn.net/fei33423/article/details/53749138
if (firstElementZxid != zxid) { // 2. 这里就有经典问题, 在 Leader 端提交了 3 个 Proposal 的信息(comit 1, comit 2, comit 3), 但 follower 在接收到 comit 1 后就接收到 comit 3
LOG.error("Committing zxid 0x" + Long.toHexString(zxid) // 3. 则就会打印这里的日志, 并且进行退出
+ " but next pending txn 0x"
+ Long.toHexString(firstElementZxid));
System.exit(12);
}
Request request = pendingTxns.remove();
commitProcessor.commit(request); // 4. 提交到 commitProcessor.committedRequests 里面
}
而后就是Follower.FinalRequestProcessor进行最终的响应客户端处理
11. Session超时机制 Leader.ping()
在Leader上有个while loop会遍历 LearnerHandler 然后发送 ping请求给 Follower/Observer
/**
* ping calls from the leader to the peers
*/
// 这里其实是 Leader 向 Follower 发送 ping 请求
// 在向 Learner 发送ping消息之前, 首先会通过 syncLimitCheck 来检查
public void ping() {
long id;
if (syncLimitCheck.check(System.nanoTime())) {
synchronized(leader) {
id = leader.lastProposed;
}
QuorumPacket ping = new QuorumPacket(Leader.PING, id, null, null);
queuePacket(ping);
} else {
LOG.warn("Closing connection to peer due to transaction timeout.");
shutdown();
}
}
12. Follower处理Leader发来的ping请求
Follower在接到Leader的ping请求后会将sessionId及timeout发送给Leader, 进行超时机制检查
// Follower 将自己的 sessionId 及超时时间发送给 Leader, 让 Leader 进行 touch 操作, 校验是否 session 超时
protected void ping(QuorumPacket qp) throws IOException {
// Send back the ping with our session data
ByteArrayOutputStream bos = new ByteArrayOutputStream();
DataOutputStream dos = new DataOutputStream(bos);
HashMap touchTable = zk // 1. 获取 Follower/Observer 的 touchTable(sessionId <-> sessionTimeout) 发给 Leader 进行session超时的检测
.getTouchSnapshot();
for (Entry entry : touchTable.entrySet()) {
dos.writeLong(entry.getKey());
dos.writeInt(entry.getValue());
}
qp.setData(bos.toByteArray()); // 2. 转化成字节数组, 进行数据的写入
writePacket(qp, true); // 3. 发送数据包
}
13. Leader处理Follower发来的sessionId及timeout
Leader在接收到Follower发来的sessionId及timeout, 将会调用SessionTrackerImpl.touchSession(long sessionId, int timeout)来进行校验
// 更新 session 的过期时间
synchronized public boolean touchSession(long sessionId, int timeout) {
ZooTrace.logTraceMessage(LOG,
ZooTrace.CLIENT_PING_TRACE_MASK,
"SessionTrackerImpl --- Touch session: 0x"
+ Long.toHexString(sessionId) + " with timeout " + timeout);
SessionImpl s = sessionsById.get(sessionId); // 1. 从 sessionsById 获取 session, sessionsById 是一个 SessionId <-> SessionImpl 的 map
// Return false, if the session doesn't exists or marked as closing
if (s == null || s.isClosing()) {
return false;
} // 2. 计算过期时间
long expireTime = roundToInterval(System.currentTimeMillis() + timeout);
if (s.tickTime >= expireTime) {
// Nothing needs to be done
return true;
}
SessionSet set = sessionSets.get(s.tickTime); // 3. 这里的 SessionSet 就是一个 timeout 对应额 Bucket, 将有一个线程, 在超时时间点检查这个 SessionSet
if (set != null) {
set.sessions.remove(s);
}
s.tickTime = expireTime; // 4. 下面的步骤就是将 session 以 tickTime 为单位放入 sessionSets 中
set = sessionSets.get(s.tickTime);
if (set == null) {
set = new SessionSet();
sessionSets.put(expireTime, set);
}
set.sessions.add(s); // 5. 将 SessionImpl 放入对应的 SessionSets 里面
return true;
}
总结
zookeeper的session机制只适用于有少量client连接Server的场景(zookeeper的默认maxClientCnxns 是60, 超过的话就会socket主动关闭), 当有百万连接时, 用这种session集中, 用一条线程检测超时的机制可能在性能上出现问题, 当zookeeper还是给出了一种很好的思考方向! 在理解了session创建机制后, 对应的create/setData/delete就很好理解了!