Intro to ML
- Def of ML by Tom Mitchell:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
Supervised Learning
Give the algorithm a dataset which contains the right answers(labels), then:
- Regression: teach the algorithm to predict a continuous value output.
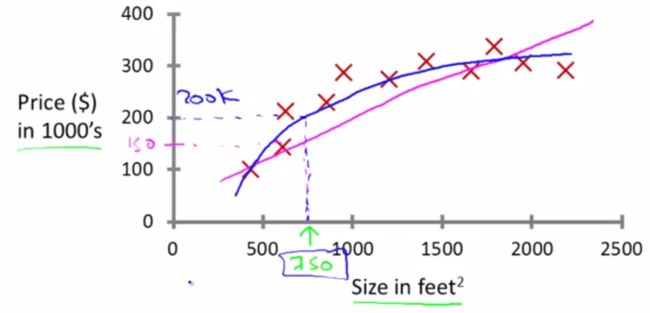
- Classification : teach the algorithm to predict a category value output

Supervised Learning
- Clustering: Give the algorithm a dataset without knowing the labels, then teach the algorithm to cluster them and then given a new data, to predict which cluster it probably belongs to.

eg: Google news clusters new stories about the same topics together.
- Cocktail Party Algorithm
Separate mixed audio source recording into individual voice.
Programming with Octave in Matlab :
[W,s,v]=svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
Remark: With unsupervised learning there is no feedback based on the prediction results.
Exercise
Some of the problems below are best addressed using a supervised learning algorithm, and the others with an unsupervised learning algorithm. Which of the following would you apply supervised learning to? (Select all that apply.) In each case, assume some appropriate dataset is available for your algorithm to learn from.
- Take a collection of 1000 essays written on the US Economy, and find a way to automatically group these essays into a small number of groups of essays that are somehow "similar" or "related".
This is an unsupervised learning/clustering problem (similar to the Google News example in the lectures).
- Given a large dataset of medical records from patients suffering from heart disease, try to learn whether there might be different clusters of such patients for which we might tailor separate treatements.
This can be addressed using an unsupervised learning, clustering, algorithm, in which we group patients into different clusters.
- Given genetic (DNA) data from a person, predict the odds of him/her developing diabetes over the next 10 years.
This can be addressed as a supervised learning, classification, problem, where we can learn from a labeled dataset comprising different people's genetic data, and labels telling us if they had developed diabetes.
- Given 50 articles written by male authors, and 50 articles written by female authors, learn to predict the gender of a new manuscript's author (when the identity of this author is unknown).
This can be addressed as a supervised learning, classification, problem, where we learn from the labeled data to predict gender.
- In farming, given data on crop yields over the last 50 years, learn to predict next year's crop yields.
This can be addresses as a supervised learning problem, where we learn from historical data (labeled with historical crop yields) to predict future crop yields.
- Examine a large collection of emails that are known to be spam email, to discover if there are sub-types of spam mail.
This can addressed using a clustering (unsupervised learning) algorithm, to cluster spam mail into sub-types.
- Examine a web page, and classify whether the content on the web page should be considered "child friendly" (e.g., non-pornographic, etc.) or "adult."
This can be addressed as a supervised learning, classification, problem, where we can learn from a dataset of web pages that have been labeled as "child friendly" or "adult."
- Examine the statistics of two football teams, and predicting which team will win tomorrow's match (given historical data of teams' wins/losses to learn from)
This can be addressed using supervised learning, in which we learn from historical records to make win/loss predictions.
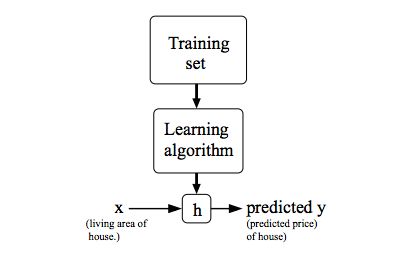
Regression
Training set : m training examples ( x(i), y(i) )
features : x
target : y
hypothesis : h: x->y
eg: Univariate linear regression
-
Cost function
objective function which we want to minimize
eg: squared error function
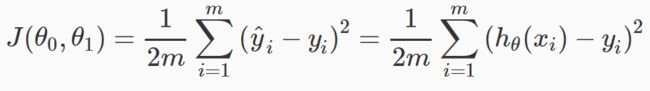 squared error function
squared error function
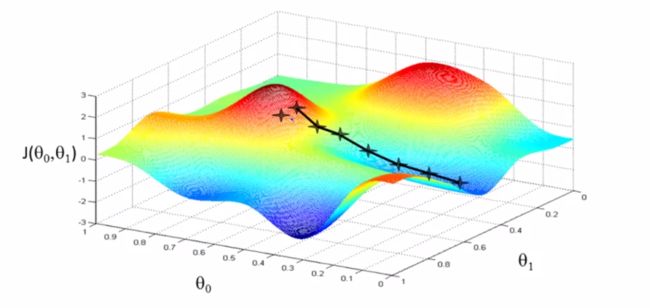
Visualize function J -> Contour Plot
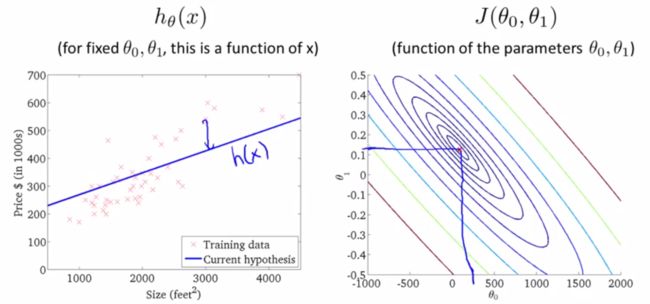
Our task is to teach the alogorithm(machine) to automatically find the value of parameters(theta) which minimize the cost function.
Gradient Descent
initialization of a position on the mountain -> walk down hill step by step -> until valley
Remark :
Assignment a:=b, a:=a+1
Truth assertion a=b

Remark :
simultaneously update the parameters
learning rate(alpha) too small -> slowly converge
learning rate(alpha) too large -> overshoot the minimun -> diverge
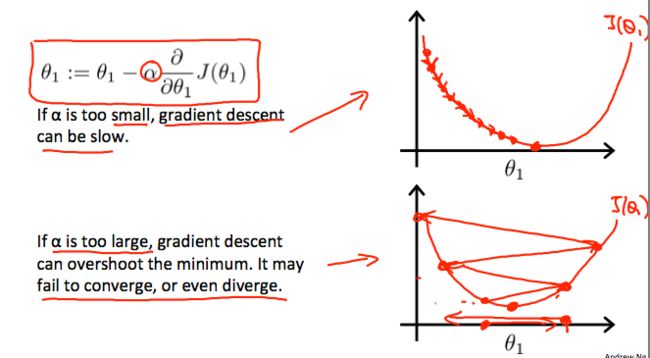
Remark :
Step gets smaller automatically -> no need to decrease learning rate at each time
"Batch" GD: each step of GD uses all the training examples
Linear Algebra
- Matrix multiplication property:
non-community : AB != BA
associative : (AB)C=A(BC) - Matrix inverse
- Matrix transpose