本文描述的是KMV模型企业信用风险评估,简单说明和实现KMV模型并得出结论。
目录
1.KMV模型简介:主要说明KMV模型是什么,解决什么问题。
2.KMV模型需要的Python库和模型所需的数据和数据处理方法:需要的Python库主要有scipy.optimize.fsolve,scipy.stats,numpy。主要用于解函数和处理整合数据;而输入数据主要有无风险利率,违约触发点,股权收益率的波动率
3.KMV模型数据输入的代码和处理数据的主要函数KMVOptSearch():KMVOptSearch()所需参数为4个主要数据:资产市场价值、资产价值波动率、违约距离和违约概率
4.KMV模型总结:对KMV模型的结论,简单说下该模型的优点和缺点
5.KMV模型进一步优化的方向:分析参数违约距离DD和违约点DPT
1. KMV模型简介
是什么?
KMV模型是一个用来评估企业预期违约概率的信用评估模型。
KMV模型利用证券市场相关数据并基于Black-Scholes期权定价模型,通过计算企业股权价值VE和股权收益率波动率σE推导出企业资产的市场价值VA 和资产收益率的波动率σA,之后根据同样是计算好的违约触发点DP,计算出当前的违约距离,最终根据经验或者标准正态分布表得到预期违约概率。
推导出市场价值VA和资产收益率的波动率σA需要市场当时的无风险利率,该企业的年收益率等等。
解决什么问题?
因此KMV模型是一个基于企业自身的特征同时结合市场的数据,最终得出企业的预期违约概率。那么接下来介绍一下到底如何推导出企业资产的市场价值VA 和资产收益率的波动率σA和计算违约距离和预期违约概率的吧
2. KMV模型计算流程
2.1 KMV模型所需特征
KMV模型所需和得出的变量如下:
VE:当期的股权价值
VA:资产价值
σE :股权收益率的波动率
σA:资产收益率的波动率
D:负债的账面价值
T:债务期限
r:无风险利率
V’A:一年后的企业资产价值,是一个随机变量
下面介绍KMV模型是如何计算企业资产价值VA、资产收益率波动率σA、违约距离DD和预期违约概率EDF:
2.2 KMV模型中的计算过程
(1)企业资产价值VA及资产收益率波动率σA计算
根据Black-Scholes期权定价模型,企业资产价值VA和股权价值VE的关系可由以下公式表示:
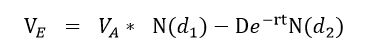
其中VE为企业股权价值,VA为企业资产价值,D为企业负债的账面价值,t为负债期限,一般设为一年,r为无风险收益率,N(x)为标准正态累计分布函数。根据公式2-1通过相关数学推导可得出股权收益率波动率σE和σA满足以下关系:
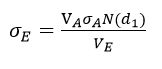
其中,
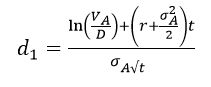
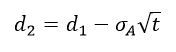
根据以上四个公式可知,由于股权价值VE和股权收益率波动率σE可以从股票市场数据计算得出,因此上式中只存在两个未知量VA和σA,因此联立以上方程即可计算出企业资产价值VA和资产收益率波动率σA。
(2)违约距离DD计算
违约距离DD表示企业资产价值期望E(VA)与违约点DPT的距离,假设企业资产价值服从正态分布,则违约距离DD可用企业资产价值期望值的标准差倍数来表示,具体公式如下:
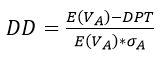
以上公式是基于企业年收益率R为0的假设前提下得出的。
另外,期权定价模型认为当企业资产价值低于债务账面价值D时企业选择违约,但由于企业债务结构中长期负债在某种程度上可以缓解企业短期资金压力,因此单纯将违约触发点DPT等同于企业负债的账面价值D显然与实际情况不符,因此KMV公司通过研究提出违约触发点DPT计算如下:
其中STD表示流动负债,LTD表示长期负债。
(3)预期违约概率EDF计算
预期违约概率计算包含两种方法,一种是基于企业历史违约数据库,根据违约距离DD映射出一个期望违约频率,即经验预期违约概率;另一种则基于企业未来资产价值服从正态分布假设,将企业预期资产价值V'A进行标准化处理,再根据标准正态分布表查出相应的概率,即理论预期违约概率,具体公式如下:
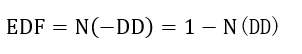
其中N(*)表示标准正态累积分布函数。
3. KMV模型数据输入的代码和处理数据的主要函数KMVOptSearch()
3.1 KMV模型数据输入方法
首先介绍KMV模型所需和得出特征或数据,具体如下:
VE:当期的股权价值
VA:资产价值
σE :股权收益率的波动率
σA:资产收益率的波动率
D:负债的账面价值
T:债务期限
r:无风险利率
V’A:一年后的企业资产价值,是一个随机变量
下面介绍以上所需特征的获取方法
3.1.1 直接获取
预测周期T:通常设置为1年
企业股权价值VE和无风险收益率r 以及股权拨动率σE可以直接得出,如下图,可以直接读出这两个特征的数值:
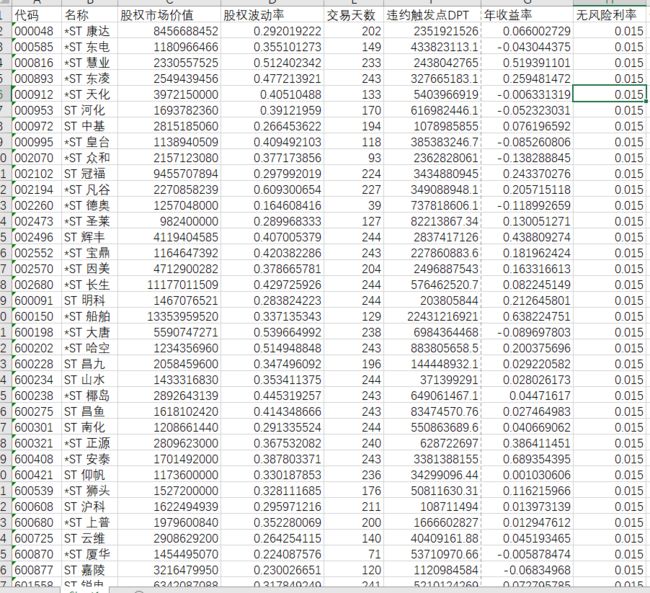
3.1.2 计算或者间接获取
企业总债务D有两种获得方法:
(1)D = SDT + 0.5LDT # SDT为:长期负债、LDT为短期负债
(2)直接数据获取(本次直接获取)
违约触发点DPT直接等于总债务D
年收益率有3种方法:
(1)年收益 = 日收益率*√天数
(2)年收益 = 月变化率×√12
(3)直接读取,本案例就是直接读取
3.2 KMV模型用到的Python库
接下来介绍一些KMV模型中需要的数据处理,用到了两个Python库,分别是scipy和numpy。下面介绍这些库的作用和使用到的方法。
3.2.1 scipy库
scipy是一个Python的第三方科学计算库,可以处理插值、积分、优化、图像处理、常微分方程数值解的求解、信号处理等问题。
主要用于有效计算Numpy矩阵,使Numpy和Scipy协同工作,高效解决问题。
利用Python编程引入第三方科学计算库模块scipy.optimize,并通过其中的fsolve函数根据迭代优化算法进行计算得到资产价值VA、资产收益率波动率σA、违约距离DD。
fsolve:它是最主要求解多变量方程与方程组的函数
函数语法:
[x,fval,exitflag,output,jacobian] = fsolve(fun,x0,options)
输入参数:
Fun: 目标函数 一般用M-文件形式给出
X0: 优化算法初始迭代点
Options: 参数设置
函数输出:
X: 最优点输出(或最后迭代点)
Fval: 最优点(或最后迭代点)对应的函数值
Exitflag: 函数结束信息 (具体参见matlab help )
Output: 函数基本信息 包括迭代次数,目标函数最大计算次数,使用的算法名称,计算规模
Jacobian:Jacobian矩阵(主要用来判断是否得到有效解)
这里也用到了scipy库其中的stats,用于累积密度函数。stats用法和参数可以参考:https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.stats.binom.html
下面代码是一些fsolve()求解函数的代码
from scipy.optimize import fsolve
def f(x):
return 2 * x - x**2 -np.exp(-x)
x0 = 0
x = fsolve(f, 0, full_output=True)
print(x)
def f(x):
return [
2 * x[0] - x[1] -np.exp(-x[0]),
-x[0] + 2 * x[1] - np.exp(-x[1])
]
x = fsolve(f, [-5, -5], full_output=True)
print(x)
def f(x, a, b):
return [
a * x[0] - x[1] -np.exp(-x[0]),
-x[0] + b * x[1] - np.exp(-x[1])
]
a = b = 2
x = fsolve(f, [-5, -5], args=(a,b), full_output=True)
print(x)
执行结果,可以看到使用fsolve()解方程组得到的结果列表:
(array([0.41640296]), {'nfev': 9, 'fjac': array([[-1.]]), 'r': array([-1.82660859]), 'qtf': array([2.32924791e-13]), 'fvec': array([0.])}, 1, 'The solution converged.')
(array([0.56714329, 0.56714329]), {'nfev': 16, 'fjac': array([[-0.71438715, 0.69975067],
[-0.69975067, -0.71438715]]), 'r': array([-107.07100209, 107.04806463, -2.2161566 ]), 'qtf': array([4.51781575e-15, 4.06157915e-13]), 'fvec': array([-1.11022302e-16, 2.22044605e-16])}, 1, 'The solution converged.')
(array([0.56714329, 0.56714329]), {'nfev': 16, 'fjac': array([[-0.71438715, 0.69975067],
[-0.69975067, -0.71438715]]), 'r': array([-107.07100209, 107.04806463, -2.2161566 ]), 'qtf': array([4.51781575e-15, 4.06157915e-13]), 'fvec': array([-1.11022302e-16, 2.22044605e-16])}, 1, 'The solution converged.')
3.2.2 numpy库
使用NumPy,开发人员可以执行以下操作:
(1)数组的算数和逻辑运算。
(2)傅立叶变换和用于图形操作的例程。
(3)与线性代数有关的操作。 NumPy 拥有线性代数和随机数生成的内置函数。
这里使用了线性代数相关的操作,结合scipy一起使用。
3.3 KMVOptSearch()代码
KMVOptSearch()嵌套了一个KMVfun函数,参数为:
EtoD:E/D,为公司的股权价值比公司负债的市场价值;由于两个未知变量VA和 σA 数量级相差巨大,VA数量级为亿、千万等等,而 σA 取值范围一般为[0,10],fsolve函数使用迭代方法进行方程组计算,为准确求解方程组必须将VA标准化,将VA根据负债D进行标准化,引入参数EtoD为E/D,便于fsolve函数迭代求解。若不变化,将出现程序失败或计算结果误差巨大的情况。
r:无风险利率
T:预测周期(债务期限)
EquityTheta (σE):公司的股权价值的波动率σE
X:公司资产的市场价值 Va = XE 比例
该函数相当于构建多元多次方程组。使用fsolve函数迭代求解,每次返回一个列表赋给x,最终得到列表后赋值给VaThetaX* 。
Va(公司资产的市场价值) = VaThetaX[0] * E
AssetTheta(σA)(公司资产价值的波动率) = VaThetaX[1]
最终返回这两个变量Va和AssetTheta。
具体KMVOptSearch()函数代码,可以看到里面先引入参数EtoD,后定义一个函数KMVfun()来将前面讲到的d1和d2的关系式用代码组合成方程组。该函数写完后进行最后的处理,使用fsolve解出数据并进行相关处理,最终得到了Va和σA并返回。
def KMVOptSearch(E, D, r, T, EquityTheta): # 计算KMV,返回值
EtoD = float(E) / float(D)
def KMVfun(x, EtoD, r, T, EquityTheta): # 构建方程式d1,d2,通过fsolve()求解得出VA和σA
EtoD, r, T, EquityTheta = float(EtoD), float(r), float(T), float(EquityTheta)
d1 = (np.log(x[0] * EtoD) + (r + 0.5 * x[1] ** 2) * T) / (x[1] * np.sqrt(T))
d2 = d1 - x[1] * np.sqrt(T)
return [
x[0] * stats.norm.cdf(d1, 0.0, 1.0) - np.exp(-r * T) * stats.norm.cdf(d2, 0.0, 1.0) / EtoD - 1,
stats.norm.cdf(d1, 0.0, 1.0) * x[0] * x[1] - EquityTheta
]
VaThetaX = fsolve(KMVfun, [1, 0.1], args=(EtoD, r, T, EquityTheta))
Va = VaThetaX[0] * E
AssetTheta = VaThetaX[1]
return Va, AssetTheta
3.4 整个KMV模型程序演示代码
3.4.1 KMV模型示例的数据来源及代码和运行结果
在商业保理融资业务中,商业保理公司对买卖双方都应做好信用风险评估工作,而广州浪奇在两次保理业务中分别担任过买方和卖方角色,且都在实务中顺利通过保理公司的审核,因此下面的代码演示中选择广州浪奇作为研究对象,探讨KMV模型在保理融资信用风险评估应用的有效性。
因此下面就使用广州浪奇在2015.06-2017.12的数据来跑整个KMV模型代码程序。
广州浪奇在2015.06-2017.12的数据如下: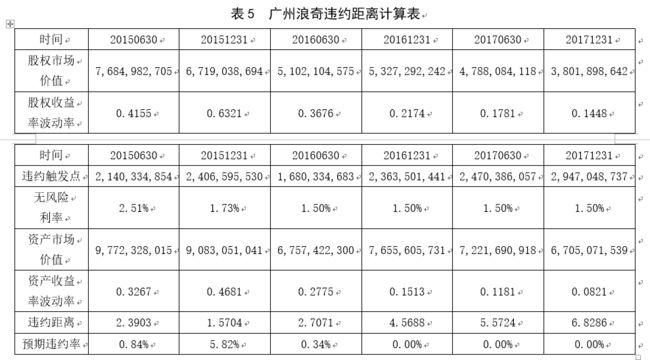
从表中可以直接得到:
VE:当时的股权价值
σE :股权收益率的波动率
DP:违约触发点
r:无风险利率
其他特征如债券价值D直接等同于DP来处理。
代码如下,前半部分主要是引入Python库和KMV模型的核心代码,前面已经介绍过了因此不再多说;后半部分为特征参数的数据赋值,有数据的特征均用列表存储,然后迭代处理,最后将每个时间段的结果输出:
from scipy import stats
from scipy.optimize import fsolve
import numpy as np
def KMVOptSearch(E, D, r, T, EquityTheta):
EtoD = float(E) / float(D)
def KMVfun(x, EtoD, r, T, EquityTheta):
EtoD, r, T, EquityTheta = float(EtoD), float(r), float(T), float(EquityTheta)
d1 = (np.log(x[0] * EtoD) + (r + 0.5 * x[1] ** 2) * T) / (x[1] * np.sqrt(T))
d2 = d1 - x[1] * np.sqrt(T)
return [
x[0] * stats.norm.cdf(d1, 0.0, 1.0) - np.exp(-r * T) * stats.norm.cdf(d2, 0.0, 1.0) / EtoD - 1,
stats.norm.cdf(d1, 0.0, 1.0) * x[0] * x[1] - EquityTheta
]
# print()
VaThetaX = fsolve(KMVfun, [1, 0.1], args=(EtoD, r, T, EquityTheta))
Va = VaThetaX[0] * E
AssetTheta = VaThetaX[1]
return Va, AssetTheta
"""
时间 20150630 20151231 20160630 20161231 20170630 20171231
股权市场价值 7,684,982,705 6,719,038,694 5,102,104,575 5,327,292,242 4,788,084,118 3,801,898,642
股权收益率波动率 0.4155 0.6321 0.3676 0.2174 0.1781 0.1448
违约触发点 2,140,334,854 2,406,595,530 1,680,334,683 2,363,501,441 2,470,386,057 2,947,048,737
无风险利率 2.51% 1.73% 1.50% 1.50% 1.50% 1.50%
资产市场价值 9,772,328,015 9,083,051,041 6,757,422,300 7,655,605,731 7,221,690,918 6,705,071,539
资产收益率波动率 0.3267 0.4681 0.2775 0.1513 0.1181 0.0821
违约距离 2.3903 1.5704 2.7071 4.5688 5.5724 6.8286
预期违约率 0.84% 5.82% 0.34% 0.00% 0.00% 0.00%
"""
# 无风险列表
r_list = [0.0251, 0.0173, 0.0150, 0.0150, 0.0150, 0.0150]
# 违约触发点列表
DP_list = [2140334854, 2406595530, 1680334683, 2363501441, 2470386057, 2947048737]
# 债券面值列表
D_list = [30983551225, 29893388116, 23062745183, 22235856439]
# 股权收益率波动率列表
PriceTheta_list = [0.4155, 0.6321, 0.3676, 0.2174, 0.1781, 0.1448]
# 股权市场价值列表
E_list = [7684982705, 6719038694, 5102104575, 5327292242, 4788084118, 3801898642]
for i in range(6):
# 利用KMV模型计算
r = r_list[i] # 无风险利率
T = 1 # 期权到期时间,以年为单位
SD = 1e8 # LD为长期负债 (单位:元)
LD = 50000000 # TD短期负债 (单位:元)
DP = DP_list[i] # 违约触发点DPT # DP=(TD-LD) +0.5LD (7) 其中:TD为总负债;LD为长期负债。 (单位:元)
D = DP # D=TD-LD+0.5∗LD 债券的面值是D (单位:元)
PriceTheta = PriceTheta_list[i] # 交易波动率,可以是日月年的数据 (单位:%)
EquityTheta = PriceTheta # 股权收益率的波动率σE
E = E_list[i] # 公司股票的市场价值 (单位:元)
Va, AssetTheta = KMVOptSearch(E, D, r, T, EquityTheta) # 资产价值VA(单位:元)资产收益率波动率σA
AssetTheta = AssetTheta # 资产收益率波动率σA (单位:%)
DD = (Va - DP) / (Va * AssetTheta) # 违约距离DD
EDF = stats.norm.cdf(-DD) # 预期违约概率EDF(单位:%)
print("第{}季度的情况:".format(i + 1))
print('Va=', Va)
print('AssetTheta=', AssetTheta)
print('DD=', DD)
print('EDF={}%'.format(EDF * 100))
print()
输出结果如下:
第1季度的情况:
Va= 9772263434.931034
AssetTheta= 0.3267525444829447
DD= 2.390122462924572
EDF=0.8421377834976101%
第2季度的情况:
Va= 9083106960.02237
AssetTheta= 0.4680222412040535
DD= 1.5705388233612272
EDF=5.814490484965715%
第3季度的情况:
Va= 6757422299.682998
AssetTheta= 0.2775516666969532
DD= 2.707009363163147
EDF=0.33946171265493935%
第4季度的情况:
Va= 7655605730.798142
AssetTheta= 0.15128173708732184
DD= 4.569433197772461
EDF=0.000244522505414333%
第5季度的情况:
Va= 7221690918.179633
AssetTheta= 0.11808284113476768
DD= 5.571693351529703
EDF=1.2613758736260054e-06%
第6季度的情况:
Va= 6705071539.410734
AssetTheta= 0.08210425796848593
DD= 6.8263777109131425
EDF=4.354273089294426e-10%
3.4.2 结果分析
通过结果分析可知,在数据的时间区间内,广州浪奇违约距离最高值为6.8286,对应预期违约概率为0,最低值为1.5704,对应预期违约概率5.82%,从变化趋势看,除了2015年12月31日违约距离相比2015年6月30日违约距离有所下降外,其余区间违约距离均呈现不断上升的趋势。在6个研究时点上,广州浪奇违约距离均值为3.9396,预期违约率均值为1.17%,预期违约概率相对较低。另外从资产市场价值与违约触发点的差值分析,研究区间内广州浪奇资产市场价值与违约触发点差值虽然逐渐缩小,但最低差值仍有3,758,022,802元,可见资产市场价值仍远大于违约触发点,公司选择违约的可能性相对较低。
4.KMV模型总结
下面对KMV模型的一些优点和缺点总结。
4.1 KMV的优点:
KMV 是一种动态的模型,可以及时反映信用风险的变化。
(1)上市公司的股价每个交易日都发生变化,且每季度公布财务报表。KMV可以据此更新模型的输入参数,及时反映市场预期。
KMV是一种前瞻性的模型,克服了依赖历史数据向后看的数理统计模型(历史变化可以在未来重现)的缺陷。
(2)EDF来自于对股票价格的实时分析,股价不仅反映了该企业历史和当前的发展状况,还反映了投资者对该企业信用状况未来发展趋势的判断。
EDF指标在本质上是一种对风险的基数衡量法。
(3)序数衡量法只能反映企业间信用风险的高低顺序,如BB级高于B级,不能明确说明高到什么程度。
(4)基数衡量法不仅可以反映风险水平的高低顺序,而且可以反映风险水平差异的程度,因而更加准确。
4.2 KMV的缺点
KMV 的使用范围受到限制。
(1)KMV适用于对上市公司的信用风险进行评估,而对非上市公司进行评估则会遇到困难。
EDP的计算给予企业资产价值服从正态分布的假设。
(2)在现实中,并非所有借款企业的资产价值都服从正态分布。
KMV无法分辨长期债务的不同类型。
(3)如果不区分长期债务的类别:优先偿还顺序、是否担保、是否可转化,可能造成违约点的计算不准确。
KMV没有考虑税收的影响。
(4)负债可以带来抵税的好处,增加企业的价值,因此在为负债企业估值时,应该把抵税效果考虑进去。
5.KMV模型进一步优化的方向
查看资料了解到关于该模型在中国应用的参数修正。
5.1 关于违约点DPT
kmv公司根据经验将违约点设在dp=sd+0.5ld,国内学者普遍认为不适合中国国情。中国上市公司失信状况比较严重,违约点的设定应提高。国内对违约点设定的研究目前还不是很多,大部分学者继续沿用违约点是公司长短期债务函数的观点,一些学者将影响违约点的因素拓展,还有学者用其他方法设定违约点。
在将违约点设为公司债务函数的研究中,出现了各种尝试:
(1)主观设定一个固定违约点,通常高于kmv模型违约点。如张智梅和章仁俊设定违约点dp=sd+0.75ld。这种方法主观性较强,未充分论证违约点设定的理论依据,因此略显粗糙。
(2)主观设立多个固定的违约点,通过实证研究选择使样本的违约组和非违约组违约概率差异最大的违约点。如张玲、杨贞柿、陈收设立了三个违约点进行对比:sd、sd+0.5ld、sd+0.75ld,结果表明违约点设在最高的sd+0.75ld时模型的信用风险差异识别能力最强,设在最低的时识别能力最差[13]。赵建卫按长期负债等差变化设立了五个违约点,分别是sd、sd+0.25ld、sd+0.5ld、sd+0.75ld、sd+ld,实证结果表明五个违约点中最高的违约点使kmv模型最有效[14]。从这些研究者的结论来看,在中国违约点的设定应明显高于kmv公司的经验违约点,从实证上支撑了中国失信状况严重的理论预期。
(3)在一定范围内改变短期负债和长期负债的系数组合,尝试各种匹配下的模型效果。如李磊宁、张凯设违约点为dp=sd+mld,0≤m≤1,m在取值范围内以0.1为步长,共设定了11个违约点,但其结论显示只有当m为0.1和0.2时模型才能通过显著性检验,在两者之中又以m=0.1效果略好,这个结论显示中国的违约点较低,与中国失信严重的理论预期有一定差异[15]。
(4)章文芳、吴丽美、崔小岩设定违约点为dp=ald+bsd,采用穷举法在(a,b)=[(0,0),(10,10)]的正方形内尝试,在考察期内,如果公司资产价值撞击违约点和公司随后被st处理的事件没有同时发生即为错判,用最小错判法寻求最优的参数组合(a,b),最终测定dp=1.2ld+3.05sd时错判率最低,正确率最高,并将此违约点与kmv公司的经验违约点sd+0.5ld的模型效果做了对比,表明kmv公司的违约点测出的st和非st公司的违约距离都大于0,用来度量中国公司的违约情况失效,而新违约点只有非st公司的违约距离大于0,与实际符合[16]。
5.2 关于违约距离DD
计算违约距离dd时使用了公司的预期资产价值,部分学者对资产的预期增长率进行了研究。李磊宁和张凯用公司近三年净收益增长率的算术平均值近似预期增长率。笔者认为,公司资产的增长率在实际中随时间而变化,尤其对违约公司,在从正常状态发展到违约的过程中,理论上应该是增长率下降甚至负增长,因此简单假定资产的预期增长率为零显然会对计算结果造成误差。
关于这些模型所用到的特征参数的调优论文还有很多,比如说使用遗传算法对违约触发点的进一步选择优化来提高KMV模型的准确率、或者使用BP-神经网络处理国内的一些未上市公司的财政报告中的特征并融合到KMV模型来对国内未上市公司的预测违约率,还有等等。这些都是接下来探讨的方向
参考代码、数据文件和文章或论文码云地址:https://gitee.com/hwang_zc/KMV_GUJI