1.MapReduce程序运行的模式简介
-
程序运行模式
- 本地模式
- 利用本地的JVM运行,使用本地的IDE进行debug
- 远程模式
- 提交至远程的集群上运行,使用本地的IDE进行debug
- 提交至远程的集群上运行,不使用本地IDE进行debug
- 本地模式
-
数据存放路径
- 远程文件系统(hdfs)
- 本地文件系统(local file system)
2.开发环境简介
- 操作系统:macOS Sierra 10.12.6
- Java版本:1.8.0_131-b11
- Hadoop版本:hadoop-2.7.4
- IDE:IntelliJ IDEA
3.MapReduce程序运行例子
3.1 程序需求
学校里开设了多门课程,有语文(chinese)、数学(math)、英语(english)等。经过了一次年级统考后,每个学生的成绩都被记录在多个文本文件中,文本文件格式如下。
- math.txt
Ben 75
Jack 60
May 85
Tom 91
- english.txt
Jack 72
May 60
Tom 62
Ben 90
- chinese.txt
Ben 79
May 88
Tom 68
Jack 70
现需要根据以上的文本文件,算出每个学生在本次统考中的平均分,并将结果用一个总的文件averageScore.txt进行存储。averageScore.txt的格式如下。
- averageScore.txt
#name #score
Ben 0.0
May 0.0
Tom 0.0
Jack 0.0
3.2 程序设计思路
3.2.1 Mapper的处理逻辑
Mapper每次从文本文件中读取1行内容,即调用1次map方法。Mapper需要把原始数据中一行的内容拆分成学生姓名(student name)和该门课程的分数(score)。按照需求,本程序最终要算出每一个学生的平均分,所以学生姓名应作为一个key,对应的value即为该生的平均分(实际上是不严谨的,因为在实际环境中会出现多个学生重名的现象,若不作特殊处理,key是不允许重复的。最根本的解决方案是采用学号作为key,但为了演示直观,仅采用学生姓名作为key)。
Mapper读完一行的数据后,把{student name,score}这个key-value写入中间结果,准备传送给Reducer作下一步的运算。
3.2.2 Reducer的处理逻辑
Reducer接收到的数据,实际上是一个key与该key对应的value的一个集合(并不仅仅是一个value)。在本需求中,传入reduce方法的参数是学生姓名,以及该生多门课程分数的集合,类似于Ben,[60,70,80,...]。所以Reducer需要将集合中的分数求和,然后求出平均值,最终得到一个{student name, average score}的key-value对。
3.2.3 具体代码设计
- AVGMapper类
用于实现map方法
package mr;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Created by marco on 2017/8/17.
*/
public class AVGMapper extends Mapper
{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
{
String line = value.toString();
if(line.length() == 0) // 文件格式错误,出现空行
return;
String[] split = line.split(" ");
String stuName = split[0];
String stuScore = split[1];
double score = Double.parseDouble(stuScore); // 转成double类型,方便后续求均值计算
context.write(new Text(stuName), new DoubleWritable(score));
}
}
- AVGReducer类
用于实现reduce方法
package mr;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by marco on 2017/8/17.
*/
public class AVGReducer extends Reducer
{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException
{
double sum = 0;
int length = 0;
for(DoubleWritable value : values)
{
sum += value.get();
length++;
}
double avgScore = sum / (double)length;
context.write(key, new DoubleWritable(avgScore));
}
}
- AVGRunner类
用于关联Mapper与Reducer,并创建MapReduce任务(Job)提交运行。基本代码如下所示。
package mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* Created by marco on 2017/8/17.
*/
public class AVGRunner
{
static public void main(String[] args) throws Exception
{
// 设置hdfs的handler
Configuration fsConf = new Configuration();
fsConf.set("fs.default.name","hdfs://localhost:9000/");
FileSystem fs = FileSystem.get(fsConf);
// MapReduce的配置参数
Configuration mrConf = new Configuration();
// 新建一个求平均值的Job
Job avgJob = Job.getInstance(mrConf);
avgJob.setJarByClass(AVGRunner.class);
// 设置Mapper类与Reducer类
avgJob.setMapperClass(AVGMapper.class);
avgJob.setReducerClass(AVGReducer.class);
// 设置输入输出的数据结构
avgJob.setMapOutputKeyClass(Text.class);
avgJob.setMapOutputValueClass(DoubleWritable.class);
avgJob.setOutputKeyClass(Text.class);
avgJob.setOutputValueClass(DoubleWritable.class);
// 检查结果输出目录,若已存在则删除输出目录
if(fs.exists(new Path("/avg/output")))
{
fs.delete(new Path("/avg/output"), true);
}
// 设置数据目录以及结果输出目录
FileInputFormat.setInputPaths(avgJob, new Path(""));
FileOutputFormat.setOutputPath(avgJob, new Path(""));
// 提交任务,等待完成
System.exit(avgJob.waitForCompletion(true)?0:1);
}
}
3.3 MapReduce程序运行
若使用本地文件系统的数据文件,且在本地模式运行,无需配置hdfs相关的参数,数据目录以及结果输出目录填写本地路径即可。(确保结果输出文件夹未被创建,否则会报异常)
// 均填写本地文件路径即可
FileInputFormat.setInputPaths(avgJob, new Path(""));
FileOutputFormat.setOutputPath(avgJob, new Path(""));
若使用hdfs上的数据文件,且在本地模式运行,应配置hdfs相关参数,数据目录以及结果输出目录均填写hdfs的路径。(确保结果输出文件夹未被创建,否则会报异常)
// 设置hdfs参数,并用该配置创建一个新的Job
Configuration fsConf = new Configuration();
fsConf.set("fs.default.name","hdfs://localhost:9000/");
Job avgJob = Job.getInstance(fsConf);
// 均填写hdfs路径即可
FileInputFormat.setInputPaths(avgJob, new Path(""));
FileOutputFormat.setOutputPath(avgJob, new Path(""));
3.3.1 本地模式运行
本地模式运行,直接编译执行AVGRunner的main方法即可,程序运行结束后会在自行设置的结果输出目录中生成运行结果。
3.3.2 远程集群运行
首先使用IDE将程序打成一个jar包,本例中命名为hadoop.jar
提交到远程集群上运行分两种情况
-
使用本地IDE(IntelliJ IDEA)运行,任务被提交到集群运行,但可使用IDE进行跟踪debug
新建一个MapReduce的配置对象,将已经打包好的jar包传入配置中
// MapReduce的配置参数,远程运行,本地debug Configuration mrConf = new Configuration(); mrConf.set("mapreduce.job.jar","hadoop.jar"); mrConf.set("mapreduce.framework.name","yarn"); //利用以上配置新建一个Job Job avgJob = Job.getInstance(mrConf); avgJob.setJarByClass(AVGRunner.class);
-
在终端直接使用hadoop命令将任务提交到集群运行,无法使用IDE进行跟踪debug
直接在终端中输入hadoop命令
hadoop jar $jar包名称 $待执行的类的名称在本例中应输入
hadoop jar avg.jar mr.AVGRunner
####################### 注意⚠️ #######################
在OS X中,使用IntelliJ IDEA打包jar包后,若在终端中直接使用
hadoop jar $jar包名称 $待执行的类的名称提交MapReduce任务,会报出异常,因为OS X系统的文件系统对大小写不敏感(case-insensitive)。经过对此异常的搜索,暂时的解决方案是通过删除jar包中的LICENSE文件,使任务顺利提交。
# 在终端中执行以下命令 zip -d $jar包名称 META-INF/LICENSE zip -d $jar包名称 LICENSE#####################################################
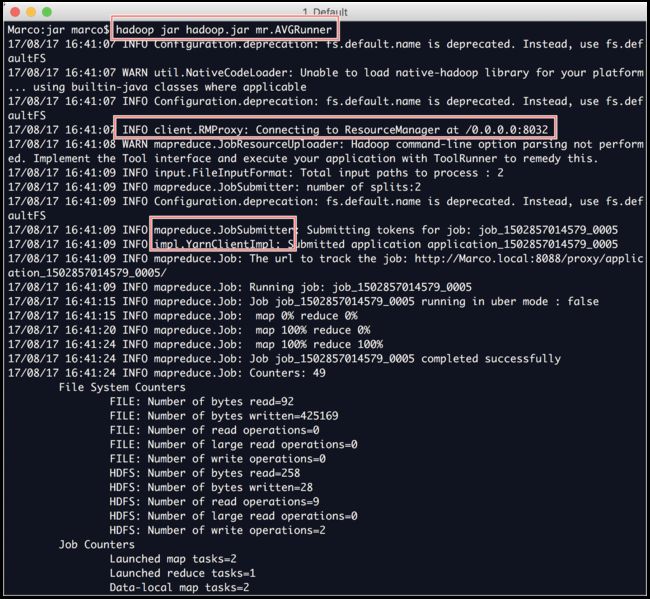

并且在MapReduce任务管理页面可看到任务已经完成的历史记录。
4.总结
MapReduce任务可在本地运行,也可提交到集群上运行。
在开发初期,需要编写Demo程序时,可在本地进行开发与测试,将数据文件放置在本地文件系统,直接使用IDE运行主类的main方法,观察运行结果。
上线前调试,可采用远程模式运行,不直接使用hadoop命令提交,而是使用IDE进行提交与debug,这样既可以保证程序运行在远处集群上(生产环境or开发环境),也可以在本地方便跟踪调试。
可上线时,使用hadoop命令直接提交到远程集群,并通过localhost:50070(默认配置)的任务管理页面进行观察。