一个运行中的程序会存取放在随机存取存储器(RAM)上的数据。RAM 读取速度快,但价格昂贵,需要持续供电,断电后保存在上面的数据会自动消失。磁盘速度比 RAM 慢,但容量大、费用低廉并且多次插拔电源线仍可保持数据。因此,计算机系统在数据存储设计中做出很大的努力来权衡磁盘和 RAM。
1. 文件输入/输出
数据持久化最简单的类型是普通文件,有时也叫平面文件(flat file)。它仅仅是在一个文件名下的字节流,把数据从一个文件读入内存,然后从内存写入文件。
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
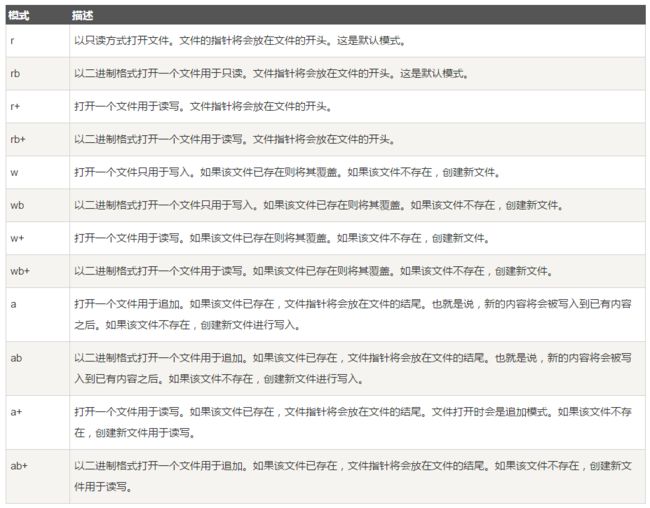
filename:filename 变量是一个包含了你要访问的文件名称的字符串值。
mode:mode 的第一个字母表明对其的操作,mode 的第二个字母是文件类型:t(或者省略)代表文本类型、b 代表二进制文件。
最后需要关闭文件。
1.1 使用write()写文本文件
f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "wt")
num = f.write( "Python 是一个非常好的语言。\n是的,的确非常好!!\n" )
print(num)
# 关闭打开的文件
f.close()
1.2 使用read()、readline()或者readlines()读文本文件
为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。
size 是一个可选的数字类型的参数。 当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
以下实例假定文件 foo.txt 已存在(上面实例中已创建):
#!/usr/bin/python3
# 打开一个文件
f = open("/tmp/foo.txt", "r")
str = f.read()
print(str)
# 关闭打开的文件
f.close()
1.3 使用write()写二进制文件
如果文件模式字符串中包含 'b',那么文件会以二进制模式打开。这种情况下,读写的是字节而不是字符串。
我们手边没有二进制格式的诗,所以直接在 0~255 产生 256 字节的值:
>>> bdata = bytes(range(0, 256))
>>> len(bdata)
256
以二进制模式打开文件,并且一次写入所有的数据:
>>> fout = open('bfile', 'wb')
>>> fout.write(bdata)
256
>>> fout.close()
再次,write() 返回到写入的字节数。
对于文本,也可以分块写二进制数据:
>>> fout = open('bfile', 'wb')
>>> size = len(bdata)
>>> offset = 0
>>> chunk = 100
>>> while True:
... if offset > size:
... break
... fout.write(bdata[offset:offset+chunk])
... offset += chunk
...
100
100
56
>>> fout.close()
1.4 使用read()读二进制文件
>>> fin = open('bfile', 'rb')
>>> bdata = fin.read()
>>> len(bdata)
256
>>> fin.close()
1.5 使用with自动关闭文件
如果你忘记关闭已经打开的一个文件,在该文件对象不再被引用之后 Python 会关掉此文件。这也就意味着在一个函数中打开文件,没有及时关闭它,但是在函数结束时会被关掉。然而你可能会在一直运行中的函数或者程序的主要部分打开一个文件,应该强制剩下的所有写操作完成后再关闭文件。
Python 的上下文管理器(context manager)会清理一些资源,例如打开的文件。它的形式
为 with expression as variable:
>>> with open('relativity', 'wt') as fout:
... fout.write(poem)
...
完成上下文管理器的代码后,文件会被自动关闭。
1.6 使用seek()改变位置
f.tell()
f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
f.seek()
如果要改变文件当前的位置, 可以使用f.seek(offset, from_what) 函数。
from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,例如:
- seek(x,0) : 从起始位置即文件首行首字符开始移动 x 个字符
- seek(x,1) : 表示从当前位置往后移动x个字符
- seek(-x,2):表示从文件的结尾往前移动x个字符
from_what 值为默认为0,即文件开头。下面给出一个完整的例子:
>>> f = open('/tmp/foo.txt', 'rb+')
>>> f.write(b'0123456789abcdef')
16
>>> f.seek(5) # 移动到文件的第六个字节
5
>>> f.read(1)
b'5'
>>> f.seek(-3, 2) # 移动到文件的倒数第三字节
13
>>> f.read(1)
b'd'
2. 结构化的文本文件
对于简单的文本文件,唯一的结构层次是间隔的行。然而有时候需要更加结构化的文本,用于后续使用的程序保存数据或者向另外一个程序传送数据。
结构化的文本有很多格式,区别它们的方法如下所示。
• 分隔符,比如 tab('\t')、逗号(',')或者竖线('|')。逗号分隔值(CSV)就是这样的例子。
• '<' 和 '>' 标签,例如 XML 和 HTML。
• 标点符号,例如 JavaScript Object Notation(JSON2)。
• 缩进,例如 YAML(即 YAML Ain't Markup Language 的缩写),要了解更多可以去搜索。
• 混合的,例如各种配置文件。
每一种结构化文件格式都能够被至少一种 Python 模块读写
2.1 CSV
>>> import csv
>>> villains = [
... ['Doctor', 'No'],
... ['Rosa', 'Klebb'],
... ['Mister', 'Big'],
... ['Auric', 'Goldfinger'],
... ['Ernst', 'Blofeld'],
... ]
>>> with open('villains', 'wt') as fout: # 一个上下文管理器
... csvout = csv.writer(fout)
... csvout.writerows(villains)
可得:
Doctor,No
Rosa,Klebb
Mister,Big
Auric,Goldfinger
Ernst,Blofeld
现在,我们来重新读这个文件:
>>> import csv
>>> with open('villains', 'rt') as fin: # 一个上下文管理器
... cin = csv.reader(fin)
... villains = [row for row in cin] # 使用列表推导式
...
>>> print(villains)
[['Doctor', 'No'], ['Rosa', 'Klebb'], ['Mister', 'Big'],
['Auric', 'Goldfinger'], ['Ernst', 'Blofeld']]
2.2 XML
带分隔符的文件仅有两维的数据:行和列。如果你想在程序之间交换数据结构,需要一种方法把层次结构、序列、集合和其他的结构编码成文本。
XML 是最突出的处理这种转换的标记(markup)格式,它使用标签(tag)分隔数据.
在 Python 中解析 XML 最简单的方法是使用 ElementTree
其他标准的 Python XML 库如下。
• xml.dom
JavaScript 开发者比较熟悉的文档对象模型(DOM)将 Web 文档表示成层次结构,它会把整个 XML 文件载入到内存中,同样允许你获取所有的内容。
• xml.sax
简单的XML API或者SAX都是通过在线解析XML,不需要一次载入所有内容到内存中,因此对于处理巨大的 XML 文件流是一个很好的选择。
2.3 HTML
在 Web 网络中,海量的数据以超文本标记语言(HTML)这一基本的文档格式存储。然而更多的 HTML 是用来格式化输出显示结果而不是用于交换数据。
2.4 JSON
JavaScript Object Notation是源于 JavaScript 的当今很流行的数据交换格式,它是 JavaScript 语言的一个子集,也是 Python 合法可支持的语法。对于Python 的兼容性使得它成为程序间数据交换的较好选择。
不同于众多的 XML 模块,Python 只有一个主要的 JSON 模块 json(名字容易记忆)。
2.5 YAML
和 JSON 类似,YAML同样有键和值,但主要用来处理日期和时间这样的数据类型。标准的 Python 库没有处理 YAML 的模块,因此需要安装第三方库 yaml将 YAML 字符串转换为 Python 数据结构,而 dump() 正好相反
2.6 安全提示
有格式保存数据对象到文件中,或者在文件中读取它们。在这个过程中也可能会产生安全性问题。
2.7 其他交换格式
这些二进制数据交换格式通常比 XML 或者 JSON 更加快速和复杂:
• MsgPack(http://msgpack.org)
• Protocol Buffers(https://code.google.com/p/protobuf/)
• Avro(http://avro.apache.org/docs/current/)
• Thrift(http://thrift.apache.org/)
因为它们都是二进制文件,所以人们是无法使用文本编辑器轻易编辑的。
2.8 使用pickle序列化
存储数据结构到一个文件中也称为序列化(serializing)。像 JSON 这样的格式需要定制
的序列化数据的转换器。Python 提供了 pickle 模块以特殊的二进制格式保存和恢复数
据对象。
还记得 JSON 解析 datetime 对象时出现问题吗?但对于 pickle 就不存在问题:
>>> import pickle
>>> import datetime
>>> now1 = datetime.datetime.utcnow()
>>> pickled = pickle.dumps(now1)
>>> now2 = pickle.loads(pickled)
>>> now1
datetime.datetime(2014, 6, 22, 23, 24, 19, 195722)
>>> now2
datetime.datetime(2014, 6, 22, 23, 24, 19, 195722)
3. 结构化二进制文件
有些文件格式是为了存储特殊的数据结构,它们既不是关系型数据库也不是 NoSQL 数据库。
3.1 电子数据表
电子数据表,尤其是 Microsoft Excel,是广泛使用的二进制数据格式。如果你把电子数据表保存到一个 CSV 文件中,就可以利用之前提到的标准 csv 模块读取它。如果你有一个xls 文件,也可以使用第三方库 xlrd 读写文件。
3.2 层次数据表
层次数据格式(HDF5)是一种用于多维数据或者层次数值数据的二进制数据格式。它主要用在科学计算领域,快速读取海量数据集(GB 或者 TB)是常见的需求。即使某些情况下 HDF5 能很好地代替数据库,但它在商业应用上也是默默无闻的。它能适用于 WORM(Write Once/Read Many;一次写入,多次读取)应用,不用担心写操作冲突的数据保护。
下面是两个可能有用的模块:
• h5py 是功能全面的较低级的接口,参考文档(http://www.h5py.org/)和代码(https://
github.com/h5py/h5py);
• PyTables 是具有数据库特征的较为高级的接口,参考文档(http://www.pytables.org/)和
代码(http://pytables.github.com/)。
4. 关系型数据库
之所以被称为关系型(relational)是因为数据库展现了表单(table)形式的不同类型数据之间的关系。
4.1 SQL
SQL 是用于访问和处理数据库的标准的计算机语言。这类数据库包括:MySQL、SQL Server、Access、Oracle、Sybase、DB2 等等。

SQL教程
4.2 DB-API

4.3 SQLite
SQLite是一种轻量级的、优秀的开源关系型数据库。它是用Python 的标准库实现, 并且存储数据库在普通文件中。这些文件在不同机器和操作系统之间是可移植的,使得 SQLite 成为简易关系型数据库应用的可移植的解决方案。它不像功能全面的 MySQL 或者 PostgreSQL, SQLite 仅仅支持原生 SQL 以及多用户并发操作。浏览器、智能手机和其他应用会把 SQLite 作为嵌入数据库。
SQLite - Python
4.4 MySQL
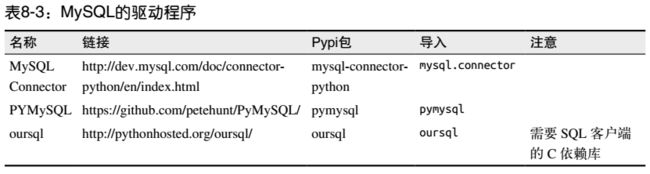
MySQL是一款非常流行的开源关系型数据库。不同于 SQLite,它是真正的数据库服务器,因此客户端可以通过网络从不同的设备连接它。
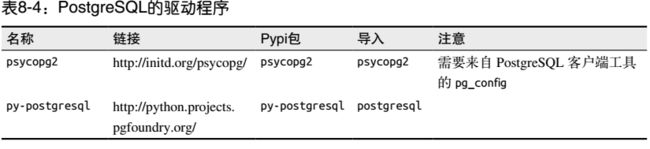
4.5 PostgreSQL
PostgreSQL是一款功能全面的开源关系型数据库,在很多方面超过 MySQL。
4.6 SQLAlchemy
对于所有的关系型数据库而言, SQL 是不完全相同的,并且 DB-API 仅仅实现共有的部
分。每一种数据库实现的是包含自己特征和哲学的方言。许多库函数用于消除它们之间的
差异,最著名的跨数据库的 Python 库是 SQLAlchemy
5. NoSQL数据存储
有些数据库并不是关系型的,不支持 SQL。它们用来处理庞大的数据集、支持更加灵活的数据定义以及定制的数据操作。 这些被统称为 NoSQL(以前的意思是 no SQL,现在理解为 not only SQL)
5.1 dbm family

5.2 memcached
memcached是一种快速的、内存键值对象的缓存服务器。它一
般置于数据库之前, 用于存储网页服务器会话数据。 Linux 和 OS X 点此链接https://code.google.com/p/memcached/wiki/NewInstallFromPackage下 载, 而 Windows 系 统 在 此
( http://zurmo.org/wiki/installing-memcache-on-windows) 下载。如果你想要尝试使用,需要一个 memcached 服务器和 Python 的驱动程序
当然存在很多这样的驱动程序, 其中能在 Python 3 使用的是 python3-memcached( https://github.com/eguven/python3-memcached)
可以通过下面这条命令安装:
pip install python-memcached
5.3 Redis
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
5.4 其他的NoSQL

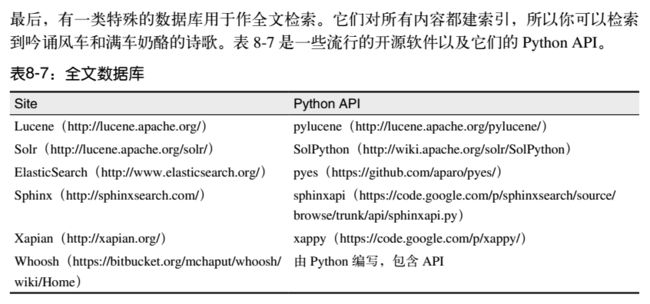
6. 全文数据库