【1:】数据去重
"数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。下面就进入这个实例的MapReduce程序设计。
注:戴#号的是重复数据
file1数据:
2012-3-1 a
2012-3-2 b
2012-3-3 c #
2012-3-4 d #
2012-3-5 a #
2012-3-6 b
2012-3-7 c
2012-3-3 c #
file2数据:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d #
2012-3-5 a #
2012-3-6 c
2012-3-7 d
2012-3-3 c #
输出结果:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
设计思路:
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求。当reduce接收到一个
在MapReduce流程中,map的输出
代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DataNoHeavy {
public static class DataMap extends Mapper{
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
Text line = value;
context.write(line, new Text(""));
};
}
public static class DataReduce extends Reducer{
protected void reduce(Text key, Iterable value, Context context)
throws java.io.IOException ,InterruptedException {
context.write(key, new Text(""));
};
}
public static void main(String[] args) {
Configuration conf = new Configuration();
//设置mapper的配置,既就是hadoop/conf/mapred-site.xml的配置信息
conf.set("mapred.job.tracker", "hadoop01:9001");
try {
//新建一个Job工作
Job job = new Job(conf);
//设置运行类
job.setJarByClass(JobRun.class);
//设置要执行的mapper类(自己书写的)
job.setMapperClass(DataMap.class);
//设置要执行的reduce类(自己书写的)
job.setReducerClass(DataReduce.class);
//设置输出key的类型
job.setMapOutputKeyClass(Text.class);
//设置输出value的类型
job.setMapOutputValueClass(Text.class);
//设置ruduce任务的个数,默认个数为一个(一般reduce的个数越多效率越高)
job.setNumReduceTasks(1);
//mapreduce 输入数据的文件/目录
FileInputFormat.addInputPath(job, new Path("/usr/input/wc/Demo/dataNoHeavy"));
//mapreduce 执行后输出的数据目录
FileOutputFormat.setOutputPath(job, new Path("/usr/output/Demo/dataNoHeavy"));
//执行完毕退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
图例:

【2】数据排序
"数据排序"是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。下面进入这个示例。
数据文件:
file1:
2
32
654
32
15
756
65223
file2:
5956
22
650
92
file3:
26
54
6
输出结果:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
设计思路:
这个实例仅仅要求对输入数据进行排序,熟悉MapReduce过程的读者会很快想到在MapReduce过程中就有排序,是否可以利用这个默认的排序,而不需要自己再实现具体的排序呢?答案是肯定的。
但是在使用之前首先需要了解它的默认排序规则。它是按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String的Text类型,那么MapReduce按照字典顺序对字符串排序。
了解了这个细节,我们就知道应该使用封装int的IntWritable型数据结构了。也就是在map中将读入的数据转化成IntWritable型,然后作为key值输出(value任意)。reduce拿到
代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DataSort {
public static class DataSortMap extends Mapper {
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
String line = value.toString();
context.write(new IntWritable(Integer.parseInt(line)), new IntWritable(1));
};
}
public static class DataSortReduce extends Reducer {
private static IntWritable linenum = new IntWritable(1);
protected void reduce(IntWritable key, Iterable value, Context context)
throws java.io.IOException ,InterruptedException {
for(IntWritable val:value){
context.write(linenum, key);
linenum = new IntWritable(linenum.get()+1);
}
};
}
public static void main(String[] args) {
Configuration conf = new Configuration();
//设置mapper的配置,既就是hadoop/conf/mapred-site.xml的配置信息
conf.set("mapred.job.tracker", "hadoop01:9001");
try {
//新建一个Job工作
Job job = new Job(conf);
//设置运行类
job.setJarByClass(JobRun.class);
//设置要执行的mapper类(自己书写的)
job.setMapperClass(DataSortMap.class);
//设置要执行的reduce类(自己书写的)
job.setReducerClass(DataSortReduce.class);
//设置输出key的类型
job.setOutputKeyClass(IntWritable.class);
//设置输出value的类型
job.setOutputValueClass(IntWritable.class);
//设置ruduce任务的个数,默认个数为一个(一般reduce的个数越多效率越高)
//job.setNumReduceTasks(1);
//mapreduce 输入数据的文件/目录
FileInputFormat.addInputPath(job, new Path("/usr/input/wc/Demo/dataSort"));
//mapreduce 执行后输出的数据目录
FileOutputFormat.setOutputPath(job, new Path("/usr/output/Demo/dataSort"));
//执行完毕退出
System.exit(job.waitForCompletion(true) ? 0 : 1 );
} catch (Exception e) {
e.printStackTrace();
}
}
}
【3】平均值
"平均成绩"主要目的还是在重温经典"WordCount"例子,可以说是在基础上的微变化版,该实例主要就是实现一个计算学生平均成绩的例子。
对输入文件中数据进行就算学生平均成绩。输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。要求在输出中每行有两个间隔的数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。
数据:
math:
张三 88
李四 99
王五 66
赵六 77
china:
张三 78
李四 89
王五 96
赵六 67
english:
张三 80
李四 82
王五 84
赵六 86
输出结果:
张三 82
李四 90
王五 82
赵六 76
设计思路:
计算学生平均成绩是一个仿"WordCount"例子,用来重温一下开发MapReduce程序的流程。程序包括两部分的内容:Map部分和Reduce部分,分别实现了map和reduce的功能。
Map处理的是一个纯文本文件,文件中存放的数据时每一行表示一个学生的姓名和他相应一科成绩。Mapper处理的数据是由InputFormat分解过的数据集,其中InputFormat的作用是将数据集切割成小数据集InputSplit,每一个InputSlit将由一个Mapper负责处理。此外,InputFormat中还提供了一个RecordReader的实现,并将一个InputSplit解析成
Map的结果会通过partion分发到Reducer,Reducer做完Reduce操作后,将通过以格式OutputFormat输出。
Mapper最终处理的结果对
代码:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class AvgSource {
public static class AvgSourceMap extends Mapper {
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
String line = value.toString();
StringTokenizer tok = new StringTokenizer(line, "\n");
while(tok.hasMoreElements()){
String name = tok.nextToken();
String source = tok.nextToken();
context.write(new Text(name), new IntWritable(Integer.parseInt(source)));
}
};
}
public static class AvgSourceReduce extends Reducer {
protected void reduce(Text key, Iterable value, Context context)
throws java.io.IOException ,InterruptedException {
int sum = 0 ;
int count = 0;
Iterator iterator = value.iterator();
while(iterator.hasNext()){
sum+= iterator.next().get();
count++;
}
int avg = (int)sum/count;
context.write(key, new IntWritable(avg));
};
}
public static void main(String[] args) {
Configuration conf = new Configuration();
//设置mapper的配置,既就是hadoop/conf/mapred-site.xml的配置信息
conf.set("mapred.job.tracker", "hadoop01:9001");
try {
//新建一个Job工作
Job job = new Job(conf);
//设置运行类
job.setJarByClass(JobRun.class);
//设置要执行的mapper类(自己书写的)
job.setMapperClass(AvgSourceMapper.class);
//设置要执行的reduce类(自己书写的)
job.setReducerClass(AvgSourceReduce.class);
//设置输出key的类型
job.setMapOutputKeyClass(Text.class);
//设置输出value的类型
job.setMapOutputValueClass(IntWritable.class);
//设置ruduce任务的个数,默认个数为一个(一般reduce的个数越多效率越高)
job.setNumReduceTasks(1);
//mapreduce 输入数据的文件/目录
FileInputFormat.addInputPath(job, new Path("/usr/input/wc/Demo/avgSource"));
//mapreduce 执行后输出的数据目录
FileOutputFormat.setOutputPath(job, new Path("/usr/output/Demo/avgSource"));
//执行完毕退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
【4】单表链接
前面的实例都是在数据上进行一些简单的处理,为进一步的操作打基础。"单表关联"这个实例要求从给出的数据中寻找所关心的数据,它是对原始数据所包含信息的挖掘。下面进入这个实例。
实例中给出child-parent(孩子——父母)表,要求输出grandchild-grandparent(孙子——爷奶)表。
数据:
file
child parent
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
家谱关系:
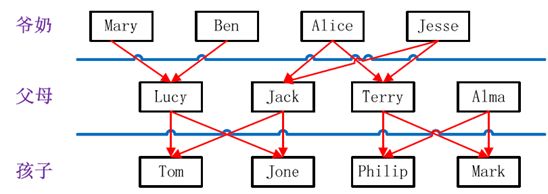
输出结果:
grandchild grandparent
Tom Alice
Tom Jesse
Jone Alice
Jone Jesse
Tom Mary
Tom Ben
Jone Mary
Jone Ben
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
代码:
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SingleRelation {
public static int time = 0;
/*
* map将输出分割child和parent,然后正序输出一次作为右表,
* 反序输出一次作为左表,需要注意的是在输出的value中必须
* 加上左右表的区别标识。
*/
public static class SingleRelationMap extends Mapper {
protected void map(LongWritable key, Text value, Context context)
throws IOException ,InterruptedException {
String child = new String();//孩子名字
String parent = new String();//父母名字
String relation = new String();//左右表标示
// 输入的一行预处理文本
StringTokenizer st = new StringTokenizer(value.toString());
String[] values = new String[2];
int i = 0;
while(st.hasMoreTokens()){
values[i] = st.nextToken();
i++;
}
if(values[0].compareTo("child") != 0){
child = values[0];
parent = values[1];
//输出左表
relation = "1";
context.write(new Text(parent), new Text(relation+"+"+child+"+"+parent));
//输出右表
relation = "2";
context.write(new Text(child), new Text(relation+"+"+child+"+"+parent));
}
};
}
public static class SingleRelationReduce extends Reducer {
protected void reduce(Text key, Iterable value, Context context)
throws IOException ,InterruptedException {
//输出表头
if(0 == time){
context.write(new Text("grandchild"), new Text("grandparent"));
time++;
}
int grandchildnum = 0 ;
String[] grandchild = new String[10];
int grandparentnum = 0;
String[] grandparent = new String[10];
Iterator ite = value.iterator();
while (ite.hasNext()) {
String record = ite.next().toString();
int len = record.length();
int i = 2;
if(0 == len){
continue;
}
// 取得左右表标识
char relation = record.charAt(0);
// 定义孩子和父母变量
String child = new String();
String parent = new String();
// 获取value-list中value的child
while(record.charAt(i) != '+'){
child += record.charAt(i);
i++;
}
i = i + 1;
while(i < len){
parent += record.charAt(i);
i++;
}
// 左表,取出child放入grandchildren
if ('1' == relation) {
grandchild[grandchildnum] = child;
grandchildnum++;
}
// 右表,取出parent放入grandparent
if ('2' == relation) {
grandparent[grandparentnum] = parent;
grandparentnum++;
}
// grandchild和grandparent数组求笛卡尔儿积
}
if (0 != grandchildnum && 0 != grandparentnum) {
for (int m = 0; m < grandchildnum; m++) {
for (int n = 0; n < grandparentnum; n++) {
// 输出结果
context.write(new Text(grandchild[m]), new Text(grandparent[n]));
}
}
}
};
}
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "hadoop01:9001");
try {
Job job = new Job(conf);
job.setJarByClass(JobRun.class);
// 设置Map和Reduce处理类
job.setMapperClass(SingleRelationMap.class);
job.setReducerClass(SingleRelationReduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path("/usr/input/wc/Demo/single"));
FileOutputFormat.setOutputPath(job, new Path("/usr/output/Demo/single"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行过程解析
map处理
child parent àà 忽略此行
Tom Lucy àà
Tom Jack àà
Jone Lucy àà
Jone Jack àà
Lucy Mary àà
Lucy Ben àà
Jack Alice àà
Jack Jesse àà
Terry Alice àà
Terry Jesse àà
Philip Terry àà
Philip Alma àà
Mark Terry àà
Mark Alma àà
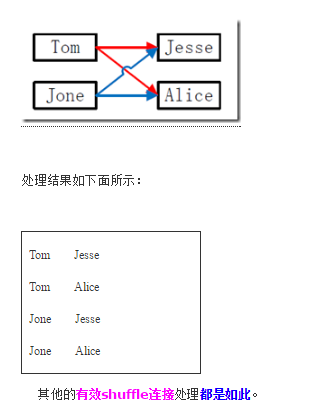
Shuffle处理

reduce处理
首先由语句"0 != grandchildnum && 0 != grandparentnum"得知,只要在"value-list"中没有左表或者右表,则不会做处理,可以根据这条规则去除无效的shuffle连接*。

然后根据下面语句进一步对有效的shuffle连接做处理。
// 左表,取出child放入grandchildren
if ('1' == relationtype) {
grandchild[grandchildnum] = childname;
grandchildnum++;
}
// 右表,取出parent放入grandparent
if ('2' == relationtype) {
grandparent[grandparentnum] = parentname;
grandparentnum++;
}
针对一条数据进行分析:
分析结果:左表用"字符1"表示,右表用"字符2"表示,上面的
根据上面针对左表与右表不同的处理规则,取得两个数组的数据如下所示:

然后根据下面语句进行处理。
for (int m = 0; m < grandchildnum; m++) {
for (int n = 0; n < grandparentnum; n++) {
context.write(new Text(grandchild[m]), new Text(grandparent[n]));
}
}