Python+PhantomJS+selenium+BeautifulSoup实现简易网络爬虫
简易网络小爬虫,目标站:http://www.toutiao.com/
已实现的功能
| 日期 | 功能 |
|---|---|
| 2017.08.12 | 可获取首页轮播图数据并保存到本地数据库 |
| 2017.08.16 | 可获取首页新闻列表每一项的全部数据(作者头像除外)并保存到本地数据库 |
仅供学习使用,如有侵权,敬请原谅。<(▰˘◡˘▰)>
Github地址: https://github.com/LalaTeam/PythonTrip
介绍
PhantomJS+selenium可以说是...无敌的...
一一介绍一下:
PhantomJS: 实质上就是一个没有界面的浏览器,最主要的功能是能够读取js加载的页面。
selenium: 浏览器自动化测试框架.能够模拟用户的一些行为操作,比如填写指定输入框,下拉操作等。
BeautifulSoup: 它是python的一个库,最主要的功能是从网页抓取数据。配合lxml解析,快速获取指定标签。
设计
基本思路:
- 利用PhantomJS模拟请求url
- 拿到网页源码,解析xml
- 获取指定标签
- 根据标签拿到需要的属性值
- 存入本地数据库
网站分析
首先看一下我们能要拿的数据
首页有一个轮播图和一个新闻列表
轮播图包括图片和文字标题
新闻列表包括图片,标题,时间,分类,作者昵称,评论数等等
打开浏览器开发者模式,分析一下标签内容,
发现每个标签都带有一个类似key的东西作为唯一标识,

截取a标签的href属性group后面的一串数字作为唯一标识,
点击每一条新闻,发现新闻详情的Url是头条首页Url+这个唯一标识,
新闻详情url暂时不获取,这里只是先获取首页数据.
再分析一下,
每一类标签都是相同的标签名并且有相同的class,这样就好办了许多,只需要找到这一堆相同class的标签,再遍历获取里面的属性值就可以了.
想到这里,基本就可以开工了,
但实际上还是有一个问题,
就是新闻列表不是一次性加载出来的,并且新闻的图片是懒加载的,怎么办?
思前想后,还是利用PhantomJS去滚动页面,
由于图片是懒加载,所以必须滚动一遍到底部停留3秒才可以拿到图片URL 否则是图片拿到的是svg+xml的Base64,
一直获取到新闻时间为一天前就停止获取,
但是这样还是会获取到有重复的新闻,
所以,还是利用它自带的key去判断是否已存在,不存在则存入数据库.
Perfect~
开工
driver = webdriver.PhantomJS()
driver.get(web_url)
# driver.page_source:网页源码
# 利用lxml解析源码拿到标签
# 找到指定的一类标签
item_tags = BeautifulSoup(driver.page_source, 'lxml')
.find_all('div', class_='bui-box single-mode')
获取每一类数据的标签
for itemTag in item_tags:
# key
k = itemTag.find('div', class_='bui-left single-mode-lbox')
.a['href'].split('/')[2]
# 图片
u = itemTag.find('div', class_='bui-left single-mode-lbox').a.img['src']
# 时间
t = itemTag.find('div', class_='single-mode-rbox')
.find('span', class_='footer-bar-action').text
# 标题
title = itemTag.find('div', class_='title-box').a.text
# 分类
type = itemTag.find('div', class_='bui-left footer-bar-left').a.text
# 作者头像
# head = itemTag.find('div', class_='single-mode-rbox')
# .find('a', class_='footer-bar-action media-avatar')
# 作者昵称
name = itemTag.find('div', class_='bui-left footer-bar-left')
.find_all('a', class_='footer-bar-action source')
na = "" if len(name) == 0 else name[0].text
# 评论数
num = itemTag.find('div', class_='bui-left footer-bar-left')
.find_all('a',class_='footer-bar-action source')
数据库判断插入或更新
@staticmethod
def isExistList(self, list):
try:
with connection.cursor() as cursor:
for item in list:
key = item[2]
cursor.execute(list_select_sql, (key))
result = cursor.fetchone()
if result is None:
self.db_operate(list_insert_sql, item)
else:
temp = (item[0], item[1], item[5], item[8], item[2])
self.db_operate(list_update_sql, temp)
finally:
# connection.close()
print('isExistList finally')
滚动到底部的三种方式
# 滚动到底部三种方式
# 1、driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 2、actions = ActionChains(driver)
# actions.move_to_element(e).perform()
elems = driver.find_elements_by_class_name("lazy-load-img")
driver.execute_script("arguments[0].scrollIntoView();", elems[len(elems) - 1])
# 停留三秒
time.sleep(3)
各种SQL语句
home_insert_sql = "INSERT INTO `tt_home_page` (`content`, `pic_url`,`click_key`,`create_time`,`type`) VALUES (%s,%s,%s,%s,%s)"
home_select_sql = "SELECT `*` FROM `tt_home_page` WHERE `click_key`=%s"
home_update_sql = "UPDATE tt_home_page SET content = %s, pic_url = %s WHERE click_key = %s"
list_insert_sql = "INSERT INTO `tt_home_list` (`content`, `pic_url`,`click_key`,`create_time`,`type`,`web_time`,`author_name`,`author_head`,`comment_num`) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
list_select_sql = "SELECT `*` FROM `tt_home_list` WHERE `click_key`=%s"
list_update_sql = "UPDATE tt_home_list SET content = %s, pic_url = %s, web_time = %s, comment_num = %s WHERE click_key = %s"
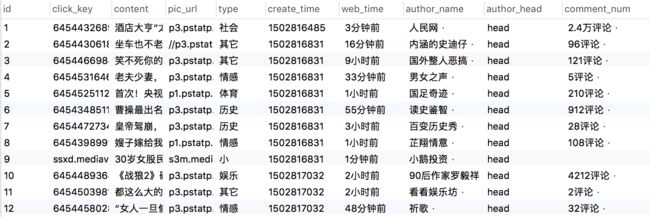
获取到的数据
- 首页列表数据
- 首页轮播数据

以上一个简单爬虫就完成了,很有意思~
具体项目可看Github,欢迎Star~