紧接着上回继续翻译吧。有关huey这个python写的的轻量级消息队列
个人才疏学浅,可能很多英文都要借助翻译软件,但尽量做到能够易于理解。
教程指导
这个文档的目的是为了帮助人尽可能快速使用huey。
简单入门
使用huey需要注意有如下三个主要的组成(或者过程):
- 生产者,例如
web应用等。 - 消费者,运行放置在消息队列中的任务(
jobs)。 - 队列,存放任务。例如
Redis等。
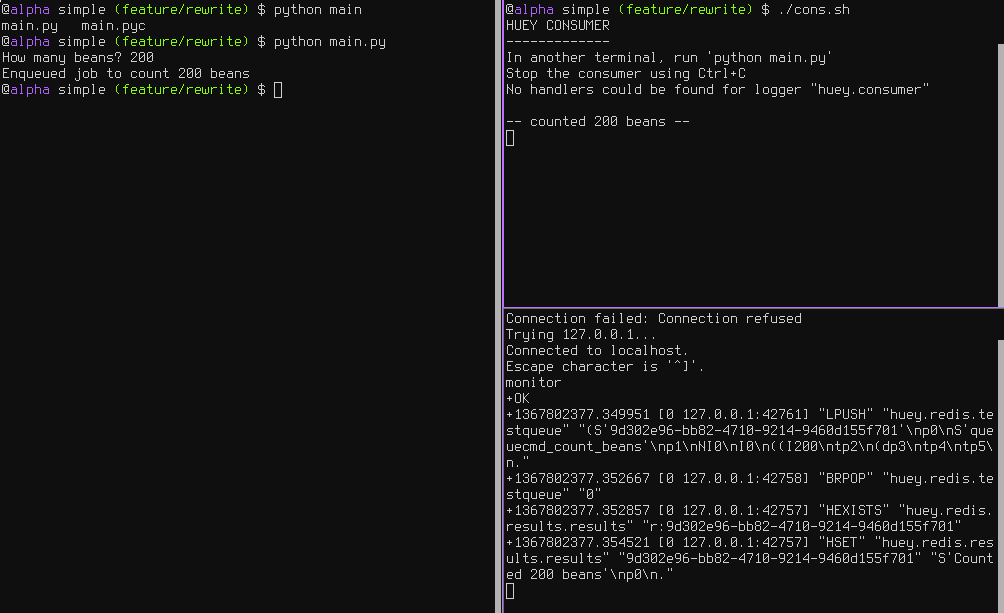
底下的截图展示了上述三个不同的过程。左边是生产者:一个简单的程序询问用户要输入多少的“豆子”。右上角消费者一直运行,它正在做“计算”,举例如图中所示打印了有多少“豆子”被计数。右下角是是一个队列,图中使用的是Redis。我们可以看到任务被添加(LPUSH)入队列和从数据库中读取(BRPOP)任务。
自我尝试
假定你安装了huey,让我们来看一下代码例子。
第一步先配置队列。消费者需要指定一个Huey实例,这代表了使用的后端类型。
# config.py
from huey import RedisHuey
huey = RedisHuey()
huey对象封装了队列。队列负责存储和取回消息,你的应用程序代码使用huey实例来联系函数调用。我们来看一下怎么使用huey来连接一个计算豆子的函数:
# tasks.py
from config import huey # import the huey we instantiated in config.py
@huey.task()
def count_beans(num):
print('-- counted %s beans --' % num)
上述代码展现了如何用API定义最终被消费者执行的“任务”——用task()装饰器简单装饰你想要让消费者运行的函数任务。而当它被调用时候,主进程将立即返回而不是进入函数内部。在消费者进程中会看到这个新消息并运行这个函数。
我们的主程序很简单。它导入了配置和任务——这确保了在我们根据指定的配置运行消费者时,所有任务都会被加载入内存。
# main.py
from config import huey # import our "huey" object
from tasks import count_beans # import our task
if __name__ == '__main__':
beans = raw_input('How many beans? ')
count_beans(int(beans))
print('Enqueued job to count %s beans' % beans)
启动脚本需要依次进行以下步骤:
- 确保本地运行
Redis - 确保安装了
huey - 启动消费者:
huey_consumer.py main.huey(注意是"main.huey"而不是"config.huey",这里提示一下huey_consumer.py需要自己从huey脚本的bin下拷贝到当前的路径,这样才能用该命令来启动。) - 运行主程序:
python main.py
获取结果
上面的例子实现了一个“发送并且忘记”的方法,但是如果你的应用程序需要对任务的结果做些什么呢?要从你的任务中获取结果,只需返回任务函数中的值即可。
如果你得到了存储结果但不使用它们,那么可能会浪费大量空间,特别是如果你的任务量很高。要禁用存储功能,可以在初始化
Huey实例时返回None或指定result_store = False。
为了更好地说明获取结果的代码,我们还将修改tasks.py模块以返回一个字符串,而不是打印结果到标准输出窗口:
from config import huey
@huey.task()
def count_beans(num):
print('-- counted %s beans --' % num)
return 'Counted %s beans' % num
我们准备向消费者输入大量任务。不是简单地执行主程序,我们这回将启动一个解释器并运行以下操作:
>>> from main import count_beans
>>> res = count_beans(100)
>>> print(res) # What is "res" ?
>>> res() # Get the result of this task
'Counted 100 beans'
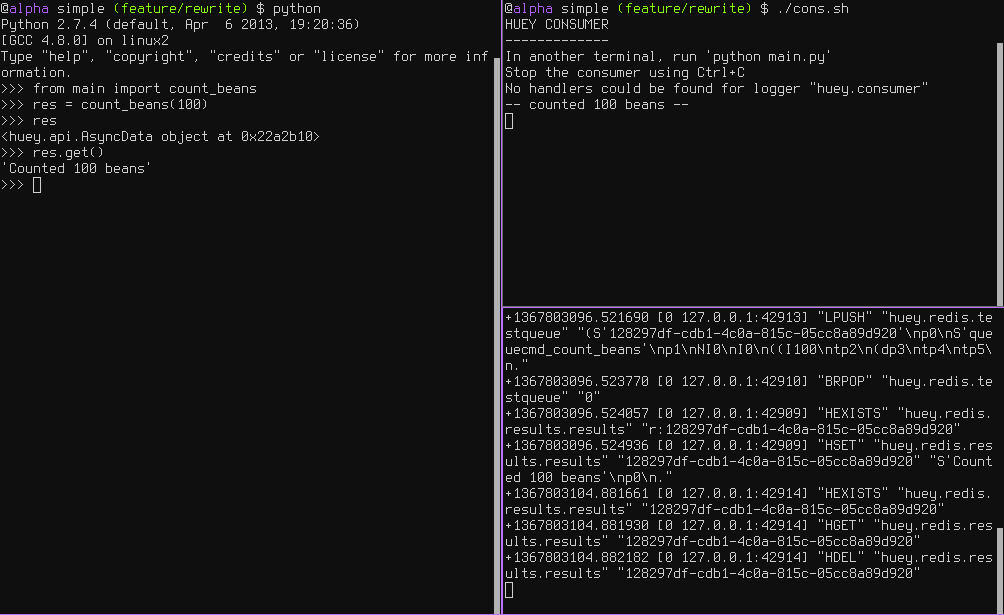
按照与上一个例子相同的布局,下面是三个主要工作流程的截图:
- 左边,解释器生成任务并询问结果
- 右上角, 消费者执行任务并存储结果
- 右下角是
Redis数据库,我们能够看到它储存结果然后在我们取回数据后删除它们
延迟执行任务
将某个特定任务排入任意时间来执行通常很用的,例如,标记在某个时间发布的博客条目。
这在huey中很容易完成。返回上一节描述的在解释器中执行的代码,让我们安排一个一分钟后执行的数豆子的任务,然后看看huey怎么处理它。执行以下代码:
>>> import datetime
>>> res = count_beans.schedule(args=(100,), delay=60)
>>> print(res)
>>> res() # This returns None, no data is ready.
>>> res() # A couple seconds later.
>>> res(blocking=True) # OK, let's just block until its ready
'Counted 100 beans'
你也可以使用datetime类型来指定“预计到达时间”:
>>> in_a_minute = datetime.datetime.now() + datetime.timedelta(seconds=60)
>>> res = count_beans.schedule(args=(100,), eta=in_a_minute)
默认情况下,
Huey实例以UTC时间运行。这对计划任务的影响是,当使用本地的时间时,它们必须与datetime.utcnow()相关联。在上述代码中我们不采用
utcnow()的原因是schedule()包含默认值为True的第三个参数叫做convert_utc。所以在上面的代码中,datetime在被发送到队列之前从本地时间转换为了UTC。当你想要以本地时间模式运行(-o),你需要总是指定
schedule()的第三个参数convert_utc=False,包括在指定delay参数时。
瞧redis的输出,我们看到以下(简化内容):
+1325563365.910640 "LPUSH" count_beans(100)
+1325563365.911912 "BRPOP" wait for next job
+1325563365.912435 "HSET" store 'Counted 100 beans'
+1325563366.393236 "HGET" retrieve result from task
+1325563366.393464 "HDEL" delete result after reading
截图也展示了相同的内容:

重试失败任务
Huey支持有限次重试失败任务。如果在执行任务期间引发了异常,但是你已经指定了retries参数,则任务将重新入队并再次尝试,直到指定的重试次数。
如下显示的一个任务,将重试3次,每次都会抛出异常:
# tasks.py
from config import huey
@huey.task()
def count_beans(num):
print('-- counted %s beans --' % num)
return 'Counted %s beans' % num
@huey.task(retries=3)
def try_thrice():
print('trying....')
raise Exception('nope')
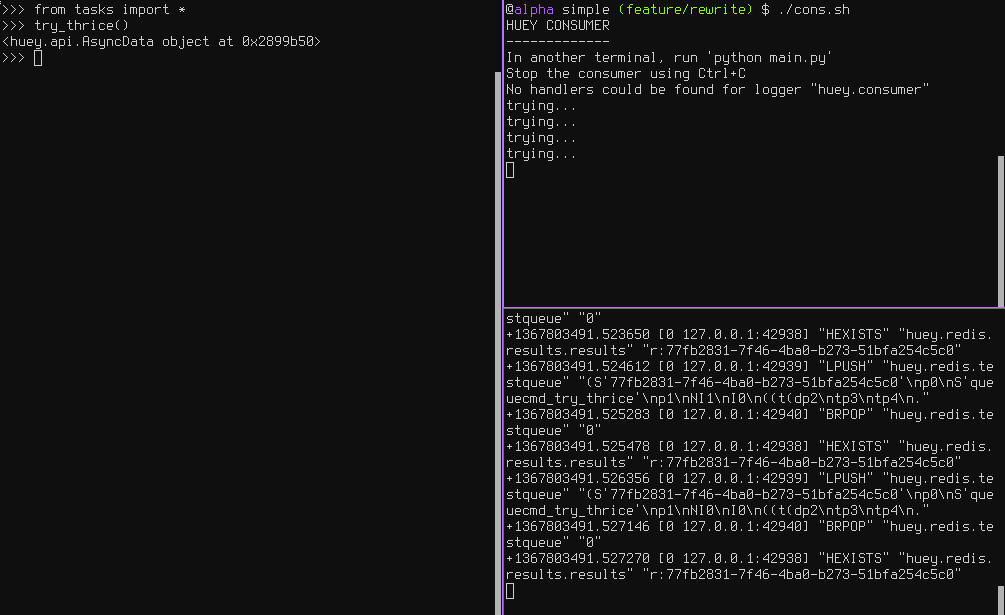
控制台输出显示我们的任务在解释器会话中被调用,然后当消费者接收然后执行它时,我们看到它失败但进行了重试:
在重试之间等待一定的时间间隔通常是个好的主意。你可以指定重试之间的delay参数(以秒为单位),这会是任务重试之前等待的最短时间。这里我们修改代码使它包含delay参数,并打印当前时间来显示它的工作。
# tasks.py
from datetime import datetime
from config import huey
@huey.task(retries=3, retry_delay=10)
def try_thrice():
print('trying....%s' % datetime.now())
raise Exception('nope')
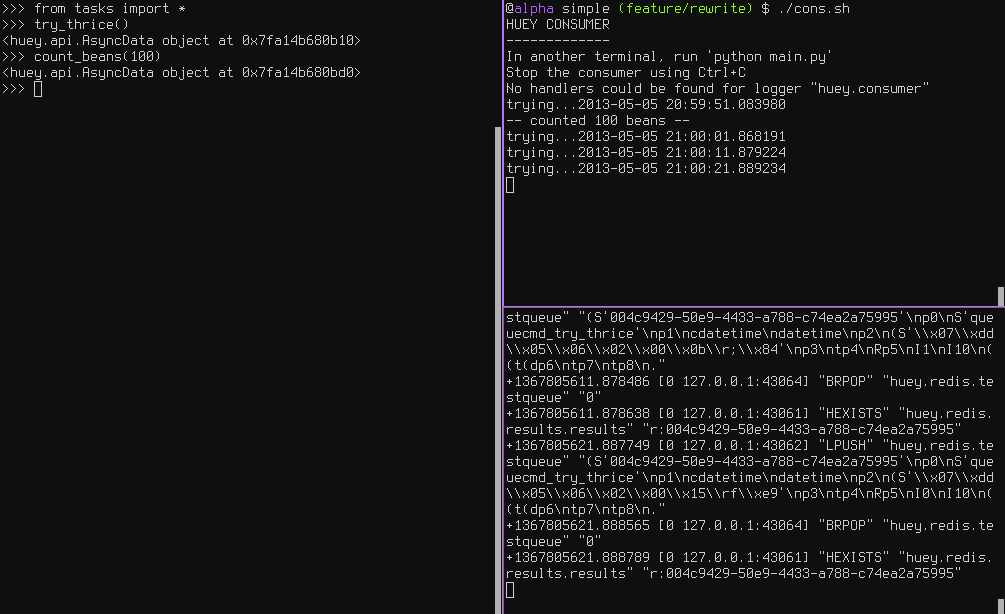
下面的控制台输出显示正在重试的任务,同时在重试过程中,我还在添加了“数豆子”的任务——处于正常执行状态。
定期任务
huey支持的另一个使用模式是定期执行任务。依照crontab行为,同时遵循类似的语法。定期执行的任务,不应返回有意义的结果,也不应接受任何参数。
让我们添加一个每分钟打印一次字符窜的新任务——我们将使用它来测试消费者是否正在按计划执行任务。
# tasks.py
from datetime import datetime
from huey import crontab
from config import huey
@huey.periodic_task(crontab(minute='*'))
def print_time():
print(datetime.now())
现在,当我们运行消费者时,它将每分钟开始打印时间:
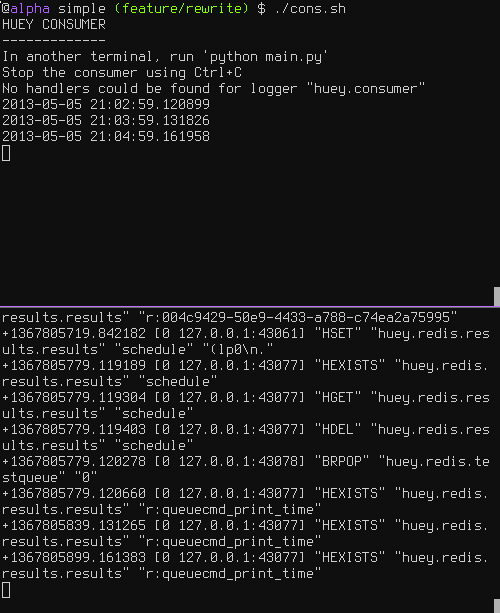
取消或暂停任务
huey可以停止任务执行。这适用于正常任务,延迟任务和定期任务。
为了“revoke(撤销)”任务,你需要在实例化Huey对象时指定一个result_store参数。
如果消费者没有开始执行任务,你可以取消正常的任务:
# count some beans
res = count_beans(10000000)
# provided the command has not started executing yet, you can
# cancel it by calling revoke() on the TaskResultWrapper object
res.revoke()
这同样适用于延迟任务:
res = count_beans.schedule(args=(100000,), eta=in_the_future)
res.revoke()
# and you can actually change your mind and restore it, provided
# it has not already been "skipped" by the consumer
res.restore()
要撤消给定任务的所有实例,请对任务本身使用revoke()和restore()方法:
count_beans.revoke()
assert count_beans.is_revoked() is True
res = count_beans(100)
assert res.is_revoked() is True
count_beans.restore()
assert count_beans.is_revoked() is False
取消或暂停定期任务
当我们开始处理定期任务时,撤销选项会更有意思。
我们将使用打印时间代码作为示例:
@huey.periodic_task(crontab(minute='*'))
def print_time():
print(datetime.now())
我们可以防止周期性的任务在下一个循环中执行:
# only prevent it from running once
print_time.revoke(revoke_once=True)
由于上述任务每分钟执行一次,我们将看到输出将跳过下一次的一分钟,然后才恢复正常。
我们也可以防止任务执行直到指定时间:
# prevent printing time for 10 minutes
now = datetime.datetime.utcnow()
in_10 = now + datetime.timedelta(seconds=600)
print_time.revoke(revoke_until=in_10)
当指定
revoke_until设置,如果消费者以UTC默认时间模式运行,本地时间需要关联到datetime.utcnow()。如果消费者以本地时间(-o参数指定),则可以使用datetime.now()。
最后,我们可以防止任务无限期地运行:
# will not print time until we call revoke() again with
# different parameters or restore the task
print_time.revoke()
assert print_time.is_revoked() is True
我们随时可以恢复任务,它将会正常执行:
print_time.restore()
查看更多
这总结了huey的基本使用模式。以下是有关API其他方面的详细信息的链接:
- Huey——负责协调可执行任务和队列后端
- Huey.task()——装饰器来指示可执行任务
- Huey.periodic_task() ——装饰器以指示以周期性间隔执行的任务
- TaskResultWrapper.get() ——从任务获取返回值
- crontab() ——用于定义执行周期性任务的间隔时间
结束
有一周混过去了,继续啃爬虫去了。。。。