本文参考《极客时间》- 从0开始学架构
关系型数据库:查询出来的数据是对象
关系模型来组织数据的数据库。通过外键来建立表与表之间的关联。
产品:Mysql,Oracle,Sqlserver,DB2,SyBase
优势:
(1)保持数据的一致性(事务处理)最大优势
(2)由于以标准化为前提,数据更新的开销很小(相同的字段基本上都只有一处)
(3) 可以进行Join等复杂查询
缺点:
(1)关系数据库存储的是行记录,无法存储数据结构
(2)关系数据库的表结构schema扩展很不方便,强约束,操作不存在的列会报错。务变化时扩充列也比较麻烦,需要执行DDL(如CREATE、ALTER、DROP等)语句修改(增量脚本),而且修改时可能会长时间锁表(例如,MySQL可能将表锁住1个小时)。
(3)关系数据库在大数据场景下I/O较高。
如果对一些大量数据的表进行统计之类的运算,关系数据库的I/O会很高,因为即使只针对其中某一列进行运算,关系数据库也会将整行数据从存储设备读入内存。
(4)关系数据库的全文搜索功能比较弱。全文搜索只能like,性能低,互联网复杂场景下难满足业务要求
NoSQL数据库只应用在特定的领域,不做复杂的操作。是为了弥补关系型的不足产生的。
非关系型数据库 NoSQL:查询出来的数据是数组。
通过对象的形式存储在数据库中,而对象之间的关系,通过每个对象自身属性来决定。
常见的NoSQL方案分为4类。
(1)Key-Value存储:解决关系数据库无法存储数据结构的问题,以Redis为代表。 高性能并发读写
(2)文档数据库:解决关系数据库强schema约束的问题,以MongoDB为代表。 不定义表结构
(3)列式数据库:解决关系数据库大数据场景下的I/O问题,以HBase为代表(可扩展性的分布式数据库)。
(4)全文搜索引擎:解决关系数据库的全文搜索性能问题,以Elasticsearch为代表。Redis:数据变化快,且大小可遇见,(适合内存容量大的)
MongoDB:动态数据查询
CouchDB:数据变化小,执行预定义查询,CRM,CMS系统
Hbase(HadoopDatabase):构建在HDFS之上的分布式、面向列的存储系统。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。
优点:
(1) 高并发读写操作
(2) 列动态添加,节省内存
(3) 自动切分数据
缺点:
(1) 不支持条件查询,Row key查询
(2) 不知道master故障切换,当Master宕机后,整个存储系统就会挂掉
(3) 数据结构单一,没有类型。
NoSQL方案带来的优势,本质上是牺牲ACID中的某个或者某几个特性.应该将NoSQL作为SQL的一个有力补充,
高性能NoSQL方案的典型特征和应用场景
K-V存储 (Key-Value存储)
Redis是K-V存储的典型代表,它是一款开源的高性能K-V缓存和存储系统。
Redis的Value是具体的数据结构,包括string、hash、list、set、sorted
set、bitmap和hyperloglog,所以常常被称为数据结构服务器。
以List数据结构为例,Redis提供了下面这些典型的操作
(更多请参考链接:http://redis.cn/commands.html#list):
LPOP key从队列的左边出队一个元素。
LINDEX key index获取一个元素,通过其索引列表。
LLEN key获得队列(List)的长度。
RPOP key从队列的右边出队一个元素。
以上这些功能,如果用关系数据库来实现,就会变得很复杂。例如,LPOP操作是移除并返回 key对应的list的第一个元素。如果用关系数据库来存储,为了达到同样目的,需要进行 下面的操作:
每条数据除了数据编号(例如,行ID),还要有位置编号,否则没有办法判断哪条数据是第一条。注意这里不能用行ID作为位置编号,因为我们会往列表头部插入数据。 查询出第一条数据。
删除第一条数据。
更新从第二条开始的所有数据的位置编号。
可以看出关系数据库的实现很麻烦,而且需要进行多次SQL操作,性能很低。
Redis的缺点主要体现在并不支持完整的ACID事务,Redis虽然提供事务功能,但Redis的事务和关系数据库的事务不可同日而语,Redis的事务只能保证隔离性和一致性(I和C),无法保证原子性和持久性(A和D)。
虽然Redis并没有严格遵循ACID原则,但实际上大部分业务也不需要严格遵循ACID原则。
文档数据库
文档数据库最大的特点就是no-schema没有表结构,可以存储和读取任意的数据。
目前绝大部分文档数据库存储的数据格式 是JSON(或者BSON),因为JSON数据是自描述的,无须在使用前定义字段,读取一个JSON中不存在的字段也不会导致SQL那样的语法错误。
优势:
1.新增字段简单 业务上增加新的字段,无须再像关系数据库一样要先执行DDL语句修改表结构,程序代码直接读写即可。
2.历史数据不会出错对于历史数据,即使没有新增的字段,也不会导致错误,只会返回空值,此时代码进行兼容处理即可。
3.可以很容易存储复杂数据。JSON是一种强大的描述语言,能够描述复杂的数据结构。用关系数据库需要设计多张表的。使用文档数据库,一 个JSON就可以全部描述。
文档数据库的这个特点,特别适合电商和游戏这类的业务场景。
例如,冰箱的属性和笔记本电脑的属性差异非常大(同类型的LCD/LED显示器参数也很大差异)
如下图所示。

例子:YTX以前电商项目数据库用的MYSQL。
商品表相关就有很多张表。
其中,属性(基本属性「材质,季节」/sku属性「颜色-尺寸」)相关的表有
item 商品表
item_category 商品分类表
item_property 商品属性表
item_property_tmpl 商品属性模板表
item_property_value 商品属性默认值
item_sku 商品销售属性表(sku表)
item_template 商品模版表
item_template_property 商品模板属性表
sku_property 商品sku属性具体值
sku_property_tmpl 商品sku属性模板表
sku_property_value 商品sku属性默认值
当初这块的需求处理起来相当麻烦,并且细节点相当多。
现在想来如果用文档数据库,简单很多、方便许多,扩展新的属性也更加容易。
缺点:
1.正因为没有表结构的优势,最主要的缺点就是不支持事务。对事务要求严格的场景不能使用文档数据库
2.无法实现关系数据库的join操作。关系型数据库多表查询即可的。文档数据库需要查询多次
列式数据库
列式数据库就是按照列来存储数据的数据库,与之对应的传统关系数据库被称为“行式数据库”,因为关系数据库是按照行来存储数据的。
关系数据库按照行式来存储数据,主要有以下几个优势:
1)业务同时读取多个列时效率高,因为这些列都是按行存储在一起的,一次磁盘操作就能够把一行数据中的各个列都读取到内存中。
2)能够一次性完成对一行中的多个列的写操作,保证了针对行数据写操作的原子性和一致性;否则如果采用列存储,可能会出现某次写操作,有的列成功了,有的列失败了,导致数据不一致。
特点:
行式存储的优势是在「特定的业务场景」下才能体现。
1)节省I/O
典型的场景就是海量数据进行统计。
例如,计算某个城市体重超重的人员数据,实际上只需要读取每个人的体重这一列并进行统计即可,而行式存储即使最终只使用一列,也会将所有行数据都读取出来。如果单行 用户信息有1KB,其中体重只有4个字节,行式存储还是会将整行1KB数据全部读取到内存中,这是明显的浪费。而如果采用列式存储,每个用户只需要读取4字节的体重数据即 可,I/O将大大减少。
2)更高的存储压缩比,能够节省更多的存储空间如果不存在这样的业务场景(场景发生变化),行式存储优势也将不复存在,甚至成为劣势。
典型的场景是需要频繁地更新多个列。
因为列式存储将不同列存储在磁盘上不连续的空间,导致更新多个列时磁盘是随机
写操作;
而行式存储时同一行多个列都存储在连续的空间,一次磁盘写操作就可以完成,列式存储的随机写效率要远远低于行式存储的写效率。
此外,列式存储高压缩率在更新场景下也会成为劣势,因为更新时需要将存储数据解压后更新,然后再压缩,最后写入磁盘。基于优缺点,一般将列式存储应用在「离线的大数据分析」和「统计场景」中,因为这种场景主要是针对部分列单列进行操作,且数据写入后就无须再更新删除。
全文搜索引擎
传统的关系型数据库通过索引来达到快速查询的目的。
在全文搜索的业务场景下,索引也无能为力,主要体现在:
1)全文搜索的条件可以随意排列组合,如果通过索引来满足,则索引的数量会非常多。
2)全文搜索的模糊匹配方式,索引无法满足,只能用like查询,而like查询是整表扫描,效率非常低。
可以看出关系数据库在支撑「全文搜索」时的不足
1.全文搜索基本原理
全文搜索引擎的技术原理被称为“倒排索引”(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,其基本原理是建立单词到文档的索引。
之所以被称为“倒排”索引,是和“正排“索引相对的。
“正排索引”的基本原理是建立文档到单词的索引。
案例:假设一个技术文章的网站,收集了各种技术文章,用户可以在网站浏览或者搜索文章。
正排索引示例:

正排索引适用于根据文档名称来查询文档内容。
例如,用户在网站上单击了“面向对象葵花宝典是什么”,网站根据文章标题查询文章的内容展示给用户。
倒排索引示例:
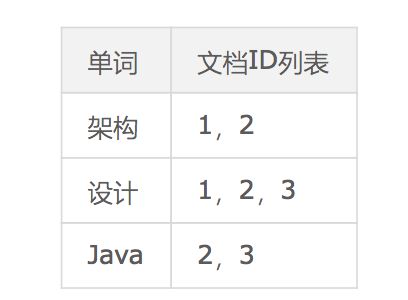
倒排索引适用于根据关键词来查询文档内容。
例如,用户只是想看“设计”相关的文章,网站需要将文章内容中包含“设计”一词的文章都搜索出来展示给用户。
2.全文搜索的使用方式
全文搜索引擎的索引对象是单词和文档,而关系数据库的索引对象是键和行,两者的术语差异很大,不能简单地等同起来。
因此,为了让全文搜索引擎支持关系型数据的全文搜索,需要做一些转换操作,即将关系型数据转换为文档数据。
目前常用的转换方式是将关系型数据按照对象的形式转换为JSON文档,然后将JSON文档输入全文搜索引擎进行索引。
案例:以程序员的基本信息表为例,看看如何转换。
{
"id": 1,
"姓名": "多隆",
"性别": "男",
"地点": "北京",
"单位": "猫厂",
"爱好": "写代码,旅游,马拉松", "语言": "Java、C++、PHP", "自我介绍": "技术专家,简单,为人热情"
}
全文搜索引擎能够基于JSON文档建立全文索引,然后快速进行全文搜索。
以Elasticsearch为例,其索引基本原理如下:
1)Elastcisearch是分布式的文档存储方式。它能存储和检索复杂的数据结构——序列化成为JSON文档——以实时的方式。
2)在Elasticsearch中,每个字段的所有数据都是默认被索引的。即每个字段都有为了快速检索设置的专用倒排索引。而且,不像其他多数的数据库,它能在相同的查询中 使用所有倒排索引,并以惊人的速度返回结果。
Elastcisearch官网:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/data-in-data-out.html
总结:
No SQL并非银弹,如ACID方面就无法跟关系型数据库相比,实际运用中,需要根据业务场景来分析。
比较好的做法是,No SQL+关系型数据库结合使用,取长补短。
如我们之前的做法是将商品/订单/库存等相关基本信息放在关系型数据库中(如MySQL,业务操作上支持事务,保证逻辑正确性),
缓存可以用Redis(减少DB压力),
搜索可以用Elasticsearch(提升搜索性能,可通过定时任务定期将DB中的信息刷到ES中)。