首先,我们可以用一个生活中的例子去理解异步的相关概念。我们将一组算法封装成一个函数,这个函数的本质也可理解为一种行为,比如我们做蛋糕这一行为。行为有可能是有结果的,也有可能仅仅是执行一段逻辑,但没有结果。比如我们做出了蛋糕,蛋糕即是行为结果。有结果的行为,我们用Callable句柄加以描述;无结果的行为,我们用Runnable句柄加以描述。假如,我们不自己做蛋糕,而是委托给糕点师去做,这样我们便可以做些别的事情(比如去热杯牛奶)。那么我们把‘委托给糕点师’这个行为使用Future句柄去描述,它表示蛋糕会在‘未来’由糕点师做好,而不是现在。于是我便可以拿着这个句柄去热杯牛奶喝了,同时,我也能随时通过这个句柄询问糕点师:你做好了没有?
没事儿总去问糕点师你做好了没有,很是麻烦。最好当糕点师做好了之后,能主动告诉我们。在jdk8以前,我们只能自己封装,或者使用三方类库(比如Guava的ListenableFuture)。作为牛逼闪闪的JDK,怎能甘于寂寞?于是并发大师Doug Lea在JDK8中编写了CompletableFuture,使用他便能够提前跟糕点师打好招呼:你做完蛋糕告诉我一声,老纸好去吃早餐。
因此Callable、Runnable、Future、CompletableFuture之间的关系一目了然:
Callable,有结果的同步行为,比如做蛋糕,产生蛋糕
Runnable,无结果的同步行为,比如喝牛奶,仅仅就是喝
Future,异步封装Callable/Runnable,比如委托给师傅(其他线程)去做糕点
CompletableFuture,封装Future,使其拥有回调功能,比如让师傅主动告诉我蛋糕做好了
public static void main(String[] args) throws InterruptedException {
CompletableFuture
//委托师傅做蛋糕
.supplyAsync(()-> {
try {
System.out.println("师傅准备做蛋糕");
TimeUnit.SECONDS.sleep(1);
System.out.println("师傅做蛋糕做好了");
} catch (InterruptedException e) {
e.printStackTrace();
}
return "cake";
})
//做好了告诉我一声
.thenAccept(cake->{
System.out.println("我吃蛋糕:" + cake);
});
System.out.println("我先去喝杯牛奶");
Thread.currentThread().join();
}
创建CompletableFuture
创建CompletableFuture,其实就是我们将做蛋糕这个事情委托糕点师。我们怎么委托呢?其一是我们要指定‘做蛋糕’这个事情(Runnable,Supplier),其二是指定糕点师(ExecutorService或内部默认的ForkJoinPool)。除此之外,我们也可能委托多个事情,比如:做蛋糕、热牛奶等等,因此我们也可以将这些委托通过allOf或者anyOf进行组合。
// 直接创建
CompletableFuture c0 = new CompletableFuture();
// 直接创建一个已经做完的蛋糕
val c1 = CompletableFuture.completedFuture("cake");
// 无返回值异步任务,会采用内部forkjoin线程池
val c2 = CompletableFuture.runAsync(()->{});
// 无返回值异步任务,采用定制的线程池
val c3 = CompletableFuture.runAsync(()->{}, newSingleThreadExecutor());
// 返回值异步任务,采用定制的线程池
val c4 = CompletableFuture.supplyAsync(()-> "cake", newSingleThreadExecutor());
// 返回值异步任务,采用内部forkjoin线程池
val c5 = CompletableFuture.supplyAsync(()-> "cake");
// 只要有一个完成,则完成,有一个抛异常,则携带异常
CompletableFuture.anyOf(c1, c2, c3, c4, c5);
// 当所有的 future 完成时,新的 future 同时完成
// 当某个方法出现了异常时,新 future 会在所有 future 完成的时候完成,并且包含一个异常.
CompletableFuture.allOf(c1, c2, c3, c4, c5);
//不抛出中断异常,看着你做蛋糕
//阻塞
cf.join();
//有异常,看着你做蛋糕
//阻塞
cf.get();
//有异常,看着你做蛋糕一小时
//阻塞
cf.get(1, TimeUnit.HOURS);
//蛋糕做好了吗?做好了我直接吃你做的,做不好我吃我的
//非阻塞
cf.getNow("my cake");
// 我问糕点师:蛋糕是否不做了?
//非阻塞
cf.isCancelled();
//我问糕点师:蛋糕是否做糊了?
//非阻塞
cf.isCompletedExceptionally();
// 我问糕点师:蛋糕做完了吗?
//非阻塞
cf.isDone();
val makeCake = CompletableFuture.supplyAsync(()->{
System.out.println("糕点师做蛋糕");
return "cake";
});
makeCake.thenApplyAsync(cake->{
System.out.println("蛋糕做好了,我来做牛奶");
return "milk";
})
.thenAcceptAsync(milk->{
System.out.println("牛奶做好了");
System.out.println("我开始吃早饭");
})
.thenRunAsync(()->{
System.out.println("吃完早饭我去上班");
});
在java8以前,我们使用java的多线程编程,一般是通过Runnable中的run方法来完成,这种方式,有个很明显的缺点,就是,没有返回值,这时候,大家可能会去尝试使用Callable中的call方法,然后用Future返回结果,如下:
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor();
Future stringFuture = executor.submit(new Callable() {
@Override
public String call() throws Exception {
Thread.sleep(2000);
return "async thread";
}
});
Thread.sleep(1000);
System.out.println("main thread");
System.out.println(stringFuture.get());
}
通过观察控制台,我们发现先打印 main thread ,一秒后打印 async thread,似乎能满足我们的需求,但仔细想我们发现一个问题,当调用future的get()方法时,当前主线程是堵塞的,这好像并不是我们想看到的,另一种获取返回结果的方式是先轮询,可以调用isDone,等完成再获取,但这也不能让我们满意. 比如:很多个异步线程执行时间可能不一致,我的主线程业务不能一直等着,这时候我可能会想要只等最快的线程执行完或者最重要的那个任务执行完,亦或者我只等1秒钟,至于没返回结果的线程我就用默认值代替.
CompletableFuture让Future的功能和使用场景得到极大的完善和扩展,提供了函数式编程能力,使代码更加美观优雅,而且可以通过回调的方式计算处理结果,对异常处理也有了更好的处理手段.
CompletableFuture源码中有四个静态方法用来执行异步任务:
public static CompletableFuture supplyAsync(Supplier supplier){..}
public static CompletableFuture supplyAsync(Supplier supplier,Executor executor){..}
public static CompletableFuture runAsync(Runnable runnable){..}
public static CompletableFuture runAsync(Runnable runnable,
Executor executor){..}
如果有多线程的基础知识,我们很容易看出,run开头的两个方法,用于执行没有返回值的任务,因为它的入参是Runnable对象,而supply开头的方法显然是执行有返回值的任务了,至于方法的入参,如果没有传入Executor对象将会使用ForkJoinPool.commonPool() 作为它的线程池执行异步代码.在实际使用中,一般我们使用自己创建的线程池对象来作为参数传入使用,这样速度会快些.
执行异步任务的方式也很简单,只需要使用上述方法就可以了:
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
//....执行任务
return "hello";}, executor)
接下来看一下获取执行结果的几个方法
V get();
V get(long timeout,Timeout unit);
T getNow(T defaultValue);
T join();
上面两个方法是Future中的实现方式,get()会堵塞当前的线程,这就造成了一个问题,如果执行线程迟迟没有返回数据,get()会一直等待下去,因此,第二个get()方法可以设置等待的时间.
getNow()方法比较有意思,表示当有了返回结果时会返回结果,如果异步线程抛了异常会返回自己设置的默认值.
接下来以一些场景的实例来介绍一下CompletableFuture中其他一些常用的方法.
thenAccept()
public CompletionStage thenAccept(Consumer action);
public CompletionStage thenAcceptAsync(Consumer action);
public CompletionStage thenAcceptAsync(Consumer action,Executor executor);
功能:当前任务正常完成以后执行,当前任务的执行结果可以作为下一任务的输入参数,无返回值.
场景:执行任务A,同时异步执行任务B,待任务B正常返回之后,用B的返回值执行任务C,任务C无返回值
thenRun(..)
public CompletionStage thenRun(Runnable action);
public CompletionStage thenRunAsync(Runnable action);
public CompletionStage thenRunAsync(Runnable action,Executor executor);
功能:对不关心上一步的计算结果,执行下一个操作
场景:执行任务A,任务A执行完以后,执行任务B,任务B不接受任务A的返回值(不管A有没有返回值),也无返回值
CompletableFuture futureA = CompletableFuture.supplyAsync(() -> "任务A");
futureA.thenRun(() -> System.out.println("执行任务B"));
thenApply(..)
public CompletableFuture thenApply(Function fn)
public CompletableFuture thenApplyAsync(Function fn)
public CompletableFuture thenApplyAsync(Function fn, Executor executor)
功能:当前任务正常完成以后执行,当前任务的执行的结果会作为下一任务的输入参数,有返回值
场景:多个任务串联执行,下一个任务的执行依赖上一个任务的结果,每个任务都有输入和输出
实例1:异步执行任务A,当任务A完成时使用A的返回结果resultA作为入参进行任务B的处理,可实现任意多个任务的串联执行
CompletableFuture futureA = CompletableFuture.supplyAsync(() -> "hello");
CompletableFuture futureB = futureA.thenApply(s->s + " world");
CompletableFuture future3 = futureB.thenApply(String::toUpperCase);
System.out.println(future3.join());
上面的代码,我们当然可以先调用future.join()先得到任务A的返回值,然后再拿返回值做入参去执行任务B,而thenApply的存在就在于帮我简化了这一步,我们不必因为等待一个计算完成而一直阻塞着调用线程,而是告诉CompletableFuture你啥时候执行完就啥时候进行下一步. 就把多个任务串联起来了.
原理介绍
CompletableFuture之前FutureTask只是Future接口的一个基本实现,并且是作为一个Task对象存在的,FutureTask本身并不管理执行线程池相关的内容,我们生成一个FutureTask对象的动机是我们希望将我们的task包装成一个FutureTask对象,使得我们可以借助FutureTask的特性来控制我们的任务。Future是一个可以代表异步计算结果的对象,并且Future提供了一些方法来让调用者控制任务,比如可以取消任务的执行(当然可能取消会失败),或者设置超时时间来取得我们的任务的运行结果。
下面我们重点来学习CompletableFuture
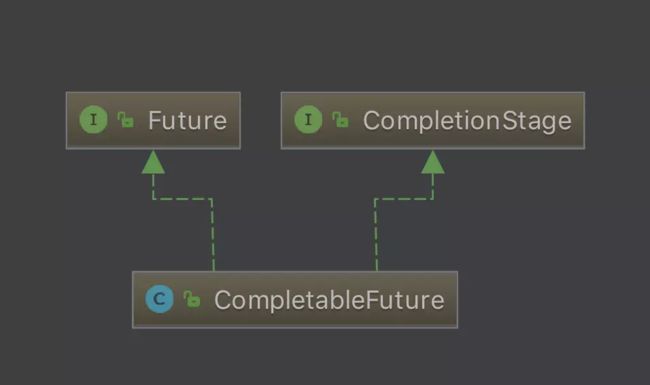
CompletableFuture同时实现了两个接口,分别为Future和CompletionStage,CompletionStage是CompletableFuture提供的一些非常丰富的接口,可以借助这些接口来实现非常复杂的异步计算工作.
先来分析一下CompletableFuture的get方法的实现细节,CompletableFuture实现了Future的所有接口,包括两个get方法,一个是不带参数的get方法,一个是可以设置等待时间的get方法,首先来看一下CompletableFuture中不带参数的get方法的具体实现:
public T get() throws InterruptedException, ExecutionException {
Object r;
return reportGet((r = result) == null ? waitingGet(true) : r);
}
result字段代表任务的执行结果,所以首先判断是否为null,为null则表示任务还没有执行结束,那么就会调用waitingGet方法来等待任务执行完成,如果result不为null,那么说明任务已经成功执行结束了,那么就调用reportGet来返回结果,下面先来看一下waitingGet方法的具体实现细节:
/**
* Returns raw result after waiting, or null if interruptible and
* interrupted.
*/
private Object waitingGet(boolean interruptible) {
Signaller q = null;
boolean queued = false;
int spins = -1;
Object r;
while ((r = result) == null) {
if (spins < 0)
spins = (Runtime.getRuntime().availableProcessors() > 1) ?
1 << 8 : 0; // Use brief spin-wait on multiprocessors
else if (spins > 0) {
if (ThreadLocalRandom.nextSecondarySeed() >= 0)
--spins;
}
else if (q == null)
q = new Signaller(interruptible, 0L, 0L);
else if (!queued)
queued = tryPushStack(q);
else if (interruptible && q.interruptControl < 0) {
q.thread = null;
cleanStack();
return null;
}
else if (q.thread != null && result == null) {
try {
ForkJoinPool.managedBlock(q);
} catch (InterruptedException ie) {
q.interruptControl = -1;
}
}
}
if (q != null) {
q.thread = null;
if (q.interruptControl < 0) {
if (interruptible)
r = null; // report interruption
else
Thread.currentThread().interrupt();
}
}
postComplete();
return r;
}
这个方法的实现时比较复杂的,方法中有几个地方需要特别注意,下面先来看一下spins是做什么的,根据注释,可以知道spins是用来在多核心环境下的自旋操作的,所谓自旋就是不断循环等待判断,从代码可以看出在多核心环境下,spins会被初始化为1 << 8,然后在自旋的过程中如果发现spins大于0,那么就通过一个关键方法ThreadLocalRandom.nextSecondarySeed()来进行spins的更新操作,如果ThreadLocalRandom.nextSecondarySeed()返回的结果大于0,那么spins就减1,否则不更新spins。ThreadLocalRandom.nextSecondarySeed()方法其实是一个类似于并发环境下的random,是线程安全的。
接下来还需要注意的一个点是Signaller,从Signaller的实现上可以发现,Signaller实现了ForkJoinPool.ManagedBlocker,下面是ForkJoinPool.ManagedBlocker的接口定义:
public static interface ManagedBlocker {
/**
* Possibly blocks the current thread, for example waiting for
* a lock or condition.
*
* @return {@code true} if no additional blocking is necessary
* (i.e., if isReleasable would return true)
* @throws InterruptedException if interrupted while waiting
* (the method is not required to do so, but is allowed to)
*/
boolean block() throws InterruptedException;
/**
* Returns {@code true} if blocking is unnecessary.
* @return {@code true} if blocking is unnecessary
*/
boolean isReleasable();
}
ForkJoinPool.ManagedBlocker的目的是为了保证ForkJoinPool的并行性,具体分析还需要更为深入的学习Fork/Join框架。继续回到waitingGet方法中,在自旋过程中会调用ForkJoinPool.managedBlock(ForkJoinPool.ManagedBlocker)来进行阻塞工作,实际的效果就是让线程等任务执行完成,CompletableFuture中与Fork/Join的交叉部分内容不再本文的描述范围,日后再进行分析总结。总得看起来,waitingGet实现的功能就是等待任务执行完成,执行完成返回结果并做一些收尾工作。
现在来看reportGet方法的实现细节,在判断任务执行完成之后,get方法会调用reportGet方法来获取结果:
/**
* Reports result using Future.get conventions.
*/
private static T reportGet(Object r)
throws InterruptedException, ExecutionException {
if (r == null) // by convention below, null means interrupted
throw new InterruptedException();
if (r instanceof AltResult) {
Throwable x, cause;
if ((x = ((AltResult)r).ex) == null)
return null;
if (x instanceof CancellationException)
throw (CancellationException)x;
if ((x instanceof CompletionException) &&
(cause = x.getCause()) != null)
x = cause;
throw new ExecutionException(x);
}
@SuppressWarnings("unchecked") T t = (T) r;
return t;
}
分析完了不带参数的get方法(阻塞等待)之后,现在来分析一下带超时参数的get方法的具体实现细节:
public T get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
Object r;
long nanos = unit.toNanos(timeout);
return reportGet((r = result) == null ? timedGet(nanos) : r);
}
和不带参数的get方法一样,还是会判断任务是否已经执行完成了,如果完成了会调用reportGet方法来返回最终的执行结果(或者抛出异常),否则,会调用timedGet来进行超时等待,timedGet会等待一段时间,然后抛出超时异常(或者执行结束返回正常结果),下面是timedGet方法的具体细节:
private Object timedGet(long nanos) throws TimeoutException {
if (Thread.interrupted())
return null;
if (nanos <= 0L)
throw new TimeoutException();
long d = System.nanoTime() + nanos;
Signaller q = new Signaller(true, nanos, d == 0L ? 1L : d); // avoid 0
boolean queued = false;
Object r;
// We intentionally don't spin here (as waitingGet does) because
// the call to nanoTime() above acts much like a spin.
while ((r = result) == null) {
if (!queued)
queued = tryPushStack(q);
else if (q.interruptControl < 0 || q.nanos <= 0L) {
q.thread = null;
cleanStack();
if (q.interruptControl < 0)
return null;
throw new TimeoutException();
}
else if (q.thread != null && result == null) {
try {
ForkJoinPool.managedBlock(q);
} catch (InterruptedException ie) {
q.interruptControl = -1;
}
}
}
if (q.interruptControl < 0)
r = null;
q.thread = null;
postComplete();
return r;
}
在timedGet中不再使用spins来进行自旋,因为现在可以确定需要等待多少时间了。timedGet的逻辑和waitingGet的逻辑类似,毕竟都是在等待任务的执行结果。
除了两个get方法之前,CompletableFuture还提供了一个方法getNow,代表需要立刻返回不进行阻塞等待,下面是getNow的实现细节:
public T getNow(T valueIfAbsent) {
Object r;
return ((r = result) == null) ? valueIfAbsent : reportJoin(r);
}
getNow很简单,判断result是否为null,如果不为null则直接返回,否则返回参数中传递的默认值。
分析完了get部分的内容,下面开始分析CompletableFuture最为重要的一个部分,就是如何开始一个任务的执行。下文中将分析supplyAsync的具体执行流程,supplyAsync有两个版本,一个是不带Executor的,还有一个是指定Executor的,下面首先分析一下不指定Executor的supplyAsync版本的具体实现流程:
supplyAsync
supplyAsync(Supplier supplier)
public static CompletableFuture supplyAsync(Supplier supplier) {
return asyncSupplyStage(asyncPool, supplier); // asyncPool, ForkJoinPool.commonPool()或者ThreadPerTaskExecutor(实现了Executor接口,里面的内容是{new Thread(r).start();})
}
asyncSupplyStage(Executor e, Supplier f)
static CompletableFuture asyncSupplyStage(Executor e, Supplier f) {
if (f == null)
throw new NullPointerException();
CompletableFuture d = new CompletableFuture(); // 构建一个新的CompletableFuture, 以此构建AsyncSupply作为Executor的执行参数
e.execute(new AsyncSupply(d, f)); // AsyncSupply继承了ForkJoinTask, 实现了Runnable, AsynchronousCompletionTask接口
return d; // 返回d,立返
}
AsyncSupply
// CompletableFuture的静态内部类,作为一个ForkJoinTask
static final class AsyncSupply extends ForkJoinTask implements Runnable, AsynchronousCompletionTask {
CompletableFuture dep; // AsyncSupply作为一个依赖Task,dep作为这个Task的Future
Supplier fn; // fn作为这个Task的具体执行逻辑,函数式编程
AsyncSupply(CompletableFuture dep, Supplier fn) {
this.dep = dep;
this.fn = fn;
}
public final Void getRawResult() {
return null;
}
public final void setRawResult(Void v) {
}
public final boolean exec() {
run();
return true;
}
public void run() {
CompletableFuture d;
Supplier f;
if ((d = dep) != null && (f = fn) != null) { // 非空判断
dep = null;
fn = null;
if (d.result == null) { // 查看任务是否结束,如果已经结束(result != null),直接调用postComplete()方法
try {
d.completeValue(f.get()); // 等待任务结束,并设置结果
} catch (Throwable ex) {
d.completeThrowable(ex); // 异常
}
}
d.postComplete(); // 任务结束后,会执行所有依赖此任务的其他任务,这些任务以一个无锁并发栈的形式存在
}
}
}
final void postComplete() {
CompletableFuture f = this; // 当前CompletableFuture
Completion h; // 无锁并发栈,(Completion next), 保存的是依靠当前的CompletableFuture一串任务,完成即触发(回调)
while ((h = f.stack) != null || (f != this && (h = (f = this).stack) != null)) { // 当f的stack为空时,使f重新指向当前的CompletableFuture,继续后面的结点
CompletableFuture d;
Completion t;
if (f.casStack(h, t = h.next)) { // 从头遍历stack,并更新头元素
if (t != null) {
if (f != this) { // 如果f不是当前CompletableFuture,则将它的头结点压入到当前CompletableFuture的stack中,使树形结构变成链表结构,避免递归层次过深
pushStack(h);
continue; // 继续下一个结点,批量压入到当前栈中
}
h.next = null; // 如果是当前CompletableFuture, 解除头节点与栈的联系
}
f = (d = h.tryFire(NESTED)) == null ? this : d; // 调用头节点的tryFire()方法,该方法可看作Completion的钩子方法,执行完逻辑后,会向后传播的
}
}
}
每个CompletableFuture持有一个Completion栈stack, 每个Completion持有一个CompletableFuture -> dep, 如此递归循环下去,是层次很深的树形结构,所以想办法将其变成链表结构。
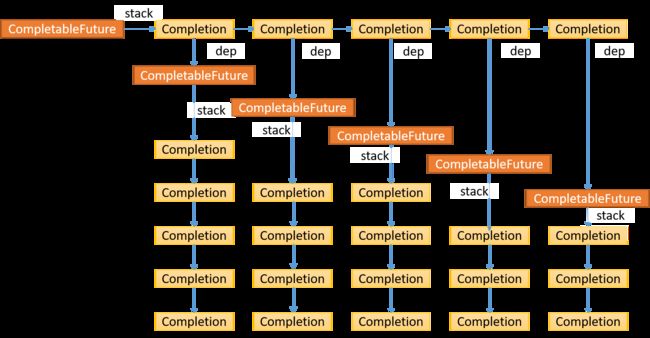
首先取出头结点,下图中灰色Completion结点,它会返回一个CompletableFuture, 同样也拥有一个stack,策略是遍历这个CompletableFuture的stack的每个结点,依次压入到当前CompletableFuture的stack中,关系如下箭头所示,灰色结点指的是处理过的结点。
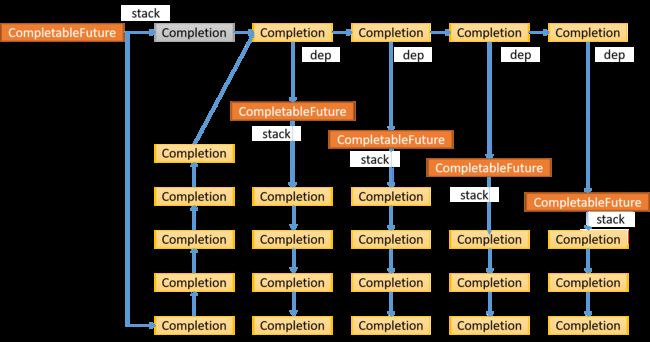
第一个Completion结点返回的CompletableFuture, 将拥有的stack里面的所有结点都压入了当前CompletableFuture的stack里面
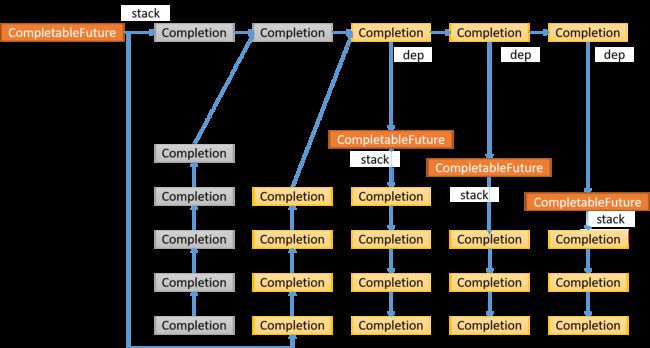
后续的Completion结点返回的CompletableFuture, 将拥有的stack里面的所有结点都压入了当前CompletableFuture的stack里面,重新构成了一个链表结构,后续也按照前面的逻辑操作,如此反复,便会遍历完所有的CompletableFuture, 这些CompletableFuture(叶子结点)的stack为空,也是结束条件。
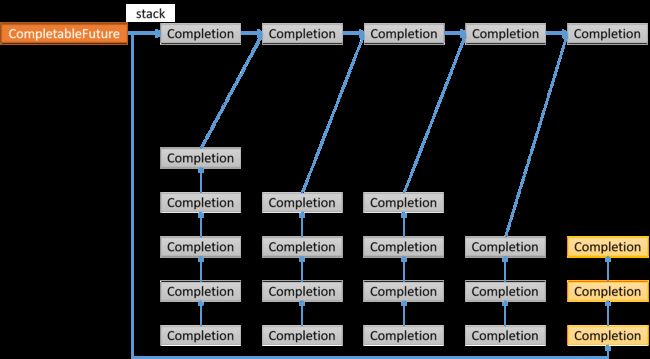
Completion
abstract static class Completion extends ForkJoinTask implements Runnable, AsynchronousCompletionTask {
volatile Completion next; // 无锁并发栈
/**
* 钩子方法,有三种模式,postComplete()方法里面使用的是NESTED模式,避免过深的递归调用 SYNC, ASYNC, or NESTED
*/
abstract CompletableFuture tryFire(int mode); // run()和exec()都调用了这个钩子方法
/** cleanStack()方法里有用到 */
abstract boolean isLive();
public final void run() {
tryFire(ASYNC);
}
public final boolean exec() {
tryFire(ASYNC);
return true;
}
public final Void getRawResult() {
return null;
}
public final void setRawResult(Void v) {
}
}
继承了ForkJoinTask, 实现了Runnable, AsynchronousCompletionTask接口,它有诸多子类,如下图
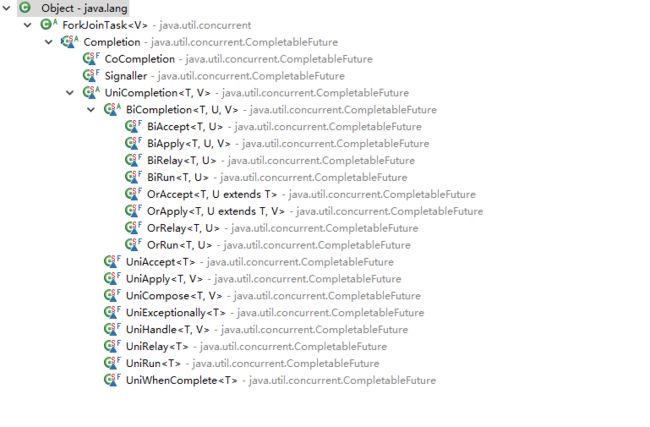
先看一个子类UniCompletion
abstract static class UniCompletion extends Completion {
Executor executor; // 执行器
CompletableFuture dep; // 依赖的任务
CompletableFuture src; // 被依赖的任务
UniCompletion(Executor executor, CompletableFuture dep,
CompletableFuture src) {
this.executor = executor; this.dep = dep; this.src = src;
}
final boolean claim() { // 如果当前任务可以被执行,返回true,否则,返回false; 保证任务只被执行一次
Executor e = executor;
if (compareAndSetForkJoinTaskTag((short)0, (short)1)) {
if (e == null)
return true;
executor = null; // 设置为不可用
e.execute(this);
}
return false;
}
final boolean isLive() { return dep != null; }
}
claim()方法保证任务只被执行一次。
whenComplete
whenComplete()/whenCompleteAsync()
public CompletableFuture whenComplete(BiConsumer action) {
return uniWhenCompleteStage(null, action);
}
public CompletableFuture whenCompleteAsync(BiConsumer action) {
return uniWhenCompleteStage(asyncPool, action);
}
xxx和xxxAsync方法的区别是,有没有asyncPool作为入参,有的话,任务直接入参,不检查任务是否完成。uniWhenCompleteStage方法有说明。
uniWhenCompleteStage(Executor e, BiConsumer f)
private CompletableFuture uniWhenCompleteStage(Executor e, BiConsumer f) {
if (f == null)
throw new NullPointerException();
CompletableFuture d = new CompletableFuture(); // 构建future
if (e != null || !d.uniWhenComplete(this, f, null)) { // 如果线程池不为空,直接构建任务入栈,并调用tryFire()方法;否则,调用uniWhenComplete()方法,检查依赖的那个任务是否完成,没有完成返回false,
// 完成了返回true, 以及后续一些操作。
UniWhenComplete c = new UniWhenComplete(e, d, this, f); // UniWhenComplete继承了UniCompletion
push(c);
c.tryFire(SYNC); // 先调一下钩子方法,检查一下任务是否结束
}
return d;
}
uniWhenComplete(CompletableFuture
final boolean uniWhenComplete(CompletableFuture a, BiConsumer f, UniWhenComplete c) {
Object r;
T t;
Throwable x = null;
if (a == null || (r = a.result) == null || f == null) // 被依赖的任务还未完成
return false;
if (result == null) { // 被依赖的任务完成了
try {
if (c != null && !c.claim()) // 判断任务是否能被执行
return false;
if (r instanceof AltResult) { // 判断异常,AltResult类型很简单,里面只有一个属性Throwable ex;
x = ((AltResult) r).ex;
t = null;
} else {
@SuppressWarnings("unchecked")
T tr = (T) r; // 正常的结果
t = tr;
}
f.accept(t, x); // 执行任务
if (x == null) {
internalComplete(r); // 任务的结果设置为被依赖任务的结果
return true;
}
} catch (Throwable ex) {
if (x == null)
x = ex; // 记录异常
}
completeThrowable(x, r); // 设置异常和结果
}
return true;
}
push()
final void push(UniCompletion c) {
if (c != null) {
while (result == null && !tryPushStack(c))
lazySetNext(c, null); // 失败重置c的next域
}
}
final boolean tryPushStack(Completion c) {
Completion h = stack;
lazySetNext(c, h);
return UNSAFE.compareAndSwapObject(this, STACK, h, c);
}
static void lazySetNext(Completion c, Completion next) {
UNSAFE.putOrderedObject(c, NEXT, next);
}
再回顾下supplyAsync方法:
public static CompletableFuture supplyAsync(Supplier supplier) {
return asyncSupplyStage(asyncPool, supplier);
}
static CompletableFuture asyncSupplyStage(Executor e,
Supplier f) {
if (f == null) throw new NullPointerException();
CompletableFuture d = new CompletableFuture();
e.execute(new AsyncSupply(d, f));
return d;
}
可以看到supplyAsync会调用asyncSupplyStage,并且指定一个默认的asyncPool来执行任务,CompletableFuture是管理执行任务的线程池的,这一点是和FutureTask的区别,FutureTask只是一个可以被执行的task,而CompletableFuture本身就管理者线程池,可以由CompletableFuture本身来管理任务的执行。这个默认的线程池是什么?
private static final boolean useCommonPool =
(ForkJoinPool.getCommonPoolParallelism() > 1);
/**
* Default executor -- ForkJoinPool.commonPool() unless it cannot
* support parallelism.
*/
private static final Executor asyncPool = useCommonPool ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
首先会做一个判断,如果条件满足就使用ForkJoinPool的commonPool作为默认的Executor,否则会使用一个ThreadPerTaskExecutor来作为CompletableFuture来做默认的Executor。
接着看asyncSupplyStage,我们提交的任务会被包装成一个AsyncSupply对象,然后交给CompletableFuture发现的Executor来执行,那AsyncSupply是什么呢?
static final class AsyncSupply extends ForkJoinTask
implements Runnable, AsynchronousCompletionTask {
CompletableFuture dep; Supplier fn;
AsyncSupply(CompletableFuture dep, Supplier fn) {
this.dep = dep; this.fn = fn;
}
public final Void getRawResult() { return null; }
public final void setRawResult(Void v) {}
public final boolean exec() { run(); return true; }
public void run() {
CompletableFuture d; Supplier f;
if ((d = dep) != null && (f = fn) != null) {
dep = null; fn = null;
if (d.result == null) {
try {
d.completeValue(f.get());
} catch (Throwable ex) {
d.completeThrowable(ex);
}
}
d.postComplete();
}
}
}
观察到AsyncSupply实现了Runnable,而Executor会执行Runnable的run方法来获得结构,所以主要看AsyncSupply的run方法的具体细节,可以看到,run方法中会试图去获取任务的结果,如果不抛出异常,那么会调用CompletableFuture的completeValue方法,否则会调用CompletableFuture的completeThrowable方法,最后会调用CompletableFuture的postComplete方法来做一些收尾工作,主要来看前两个方法的细节,首先是completeValue方法:
/** Completes with a non-exceptional result, unless already completed. */
final boolean completeValue(T t) {
return UNSAFE.compareAndSwapObject(this, RESULT, null,
(t == null) ? NIL : t);
}
completeValue方法会调用UNSAFE.compareAndSwapObject来讲任务的结果设置到CompletableFuture的result字段中去。如果在执行任务的时候抛出异常,会调用completeThrowable方法,下面是completeThrowable方法的细节:
/** Completes with an exceptional result, unless already completed. */
final boolean completeThrowable(Throwable x) {
return UNSAFE.compareAndSwapObject(this, RESULT, null,
encodeThrowable(x));
}
指定Executor的supplyAsync方法和没有指定Executor参数的supplyAsync方法的唯一区别就是执行任务的Executor.这里不多讲。
到这里,可以知道Executor实际执行的代码到底是什么了,回到asyncSupplyStage方法,接着就会执行Executor.execute方法来执行任务,需要注意的是,asyncSupplyStage方法返回的是一个CompletableFuture,并且立刻返回的,具体的任务处理逻辑是有Executor来执行的,当任务处理完成的时候,Executor中负责处理的线程会将任务的执行结果设置到CompletableFuture的result字段中去。