写在前面
- 态度决定高度!让优秀成为一种习惯!
- 世界上没有什么事儿是加一次班解决不了的,如果有,就加两次!(- - -茂强)
什么是一个图
-
一个网络
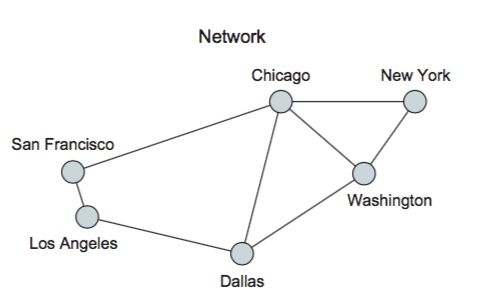 Network
Network -
一个树
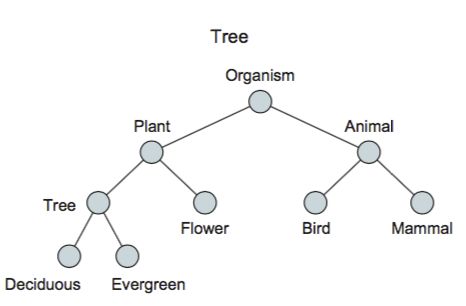 Tree
Tree -
一个RDBMS
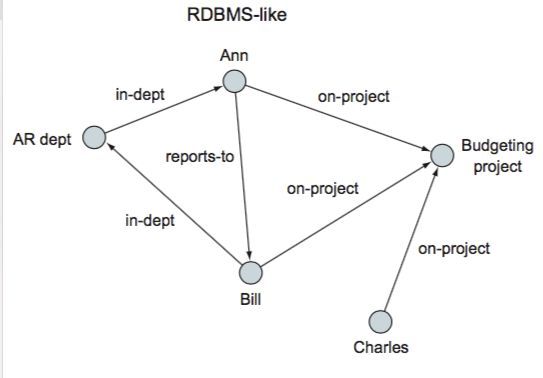 RDMBMS
RDMBMS -
一个稀疏矩阵
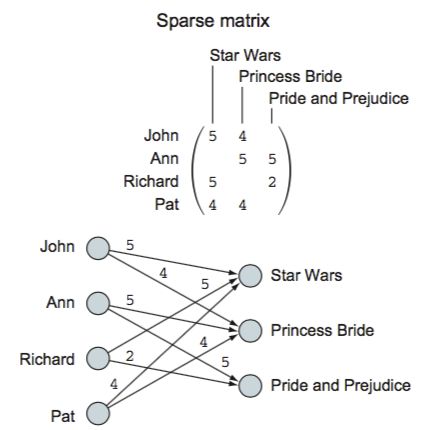 稀疏矩阵网络
稀疏矩阵网络 -
或者
 Kitchen sink
Kitchen sink
属性图
-
顶点
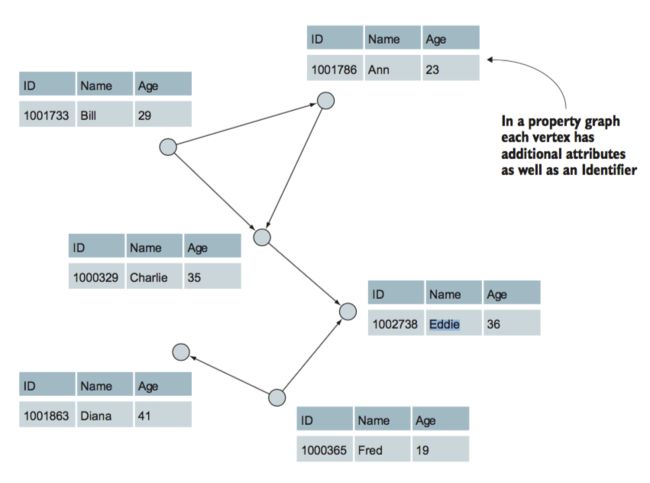 顶点
顶点 -
边
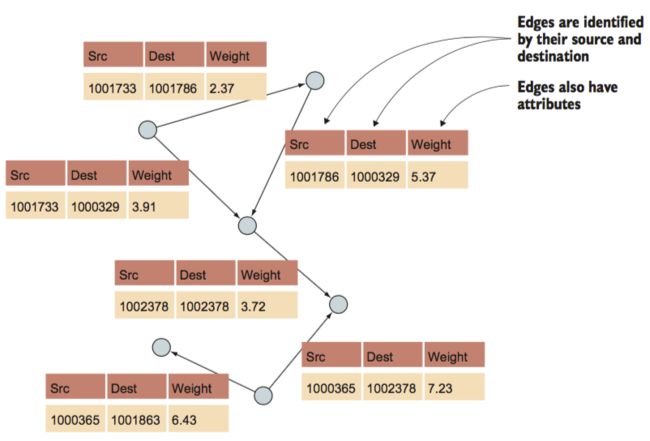 边
边
GRAPHX
graphx是一个图计算引擎,而不是一个图数据库,它可以处理像倒排索引,推荐系统,最短路径,群体检测等等
-
有向图与无向图
 有向图无向图
有向图无向图 -
有环图与无环图
两者的区别在于是否能够沿着方向构成一个闭环
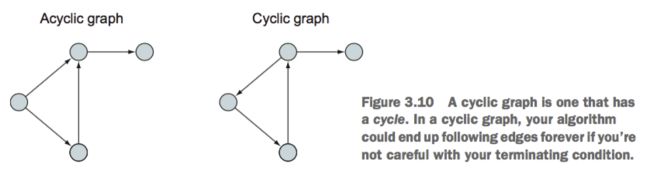 有环图无环图
有环图无环图 -
有标签图与无标签图
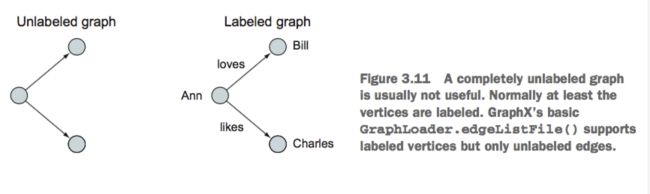 有标签无标签图
有标签无标签图 -
伪图与循环
从简单的图开始,当允许两个节点之间有多个边的时候,就是一个复合图,如果在某个节点上加个循环就成了伪图,GRAPHX中的图都是伪图
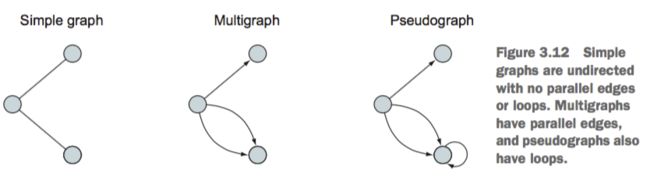 伪图与循环
伪图与循环 -
二部图/偶图
偶图有个特殊的结构,就是所有的顶点分为两个数据集,所有的边都是建立在这两个数据集之间的,在一个数据集中不会存在边
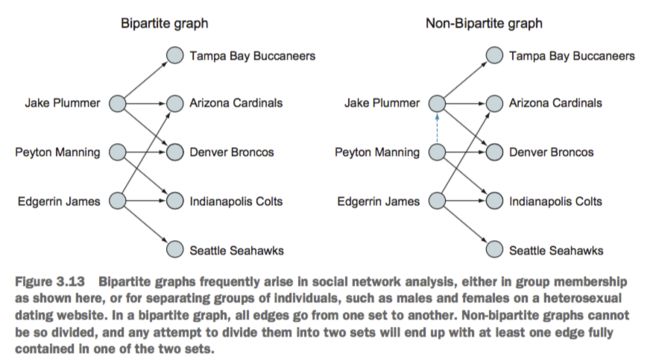 偶图
偶图 -
RDF(Resource Description Framework )图与属性图
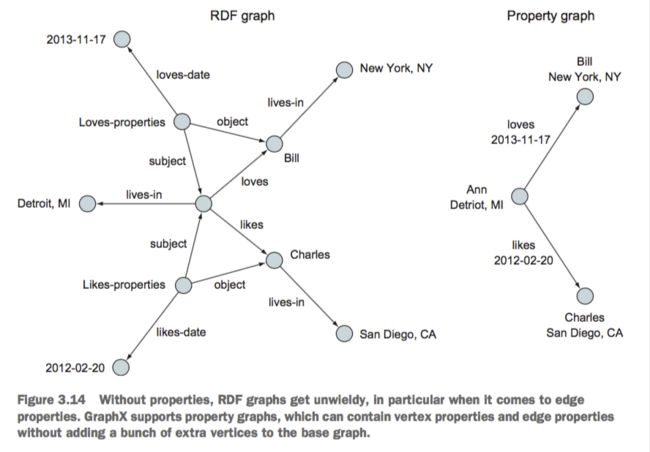 RDF图与属性图
RDF图与属性图 -
邻接矩阵
 邻接矩阵
邻接矩阵
SPARK GRAPHX
-
RDD
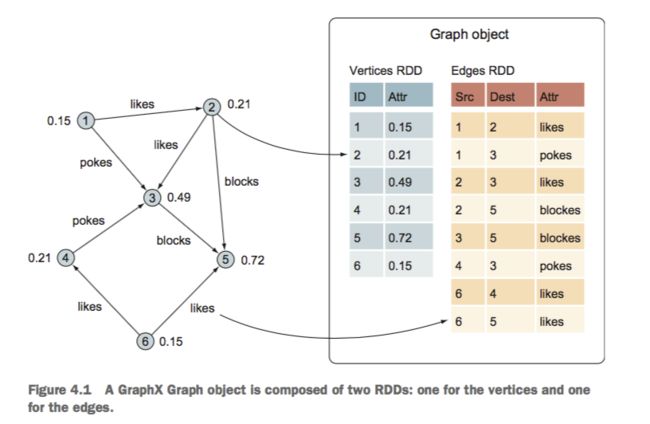 DATA IN GRAPHX
DATA IN GRAPHX
graphx中的Graph有两个RDD,一个是边RDD,一个是点RDD
其中UML如下
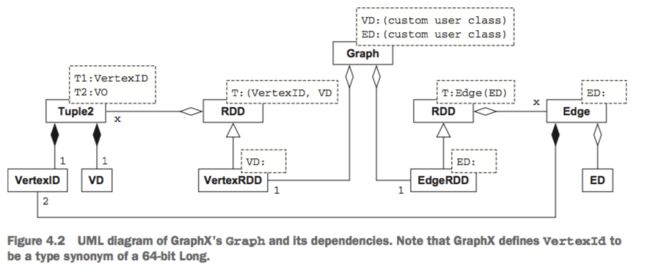 Graph UML
Graph UML -
理解三元组
其实就是由(点、边,点)的一个有效组合,由triplets()接口获取
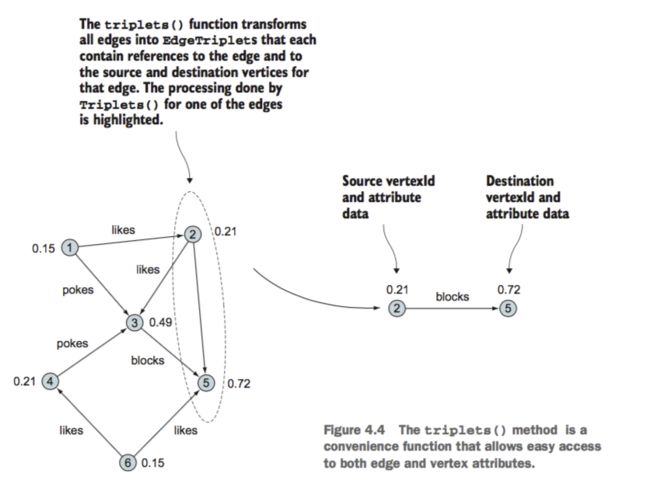 三元组
三元组
其中triplets()返回的结果是EdgeTriplet[VD,ED],EdgeTriplet[VD,ED]的属性接口有:
 属性接口
属性接口 理解aggregateMessages
首先看下源码:
def aggregateMessages[A: ClassTag](
sendMsg: EdgeContext[VD, ED, A] => Unit,
mergeMsg: (A, A) => A,
tripletFields: TripletFields = TripletFields.All): VertexRDD[A] = {
aggregateMessagesWithActiveSet(sendMsg, mergeMsg, tripletFields, None)
}
EdgeContext
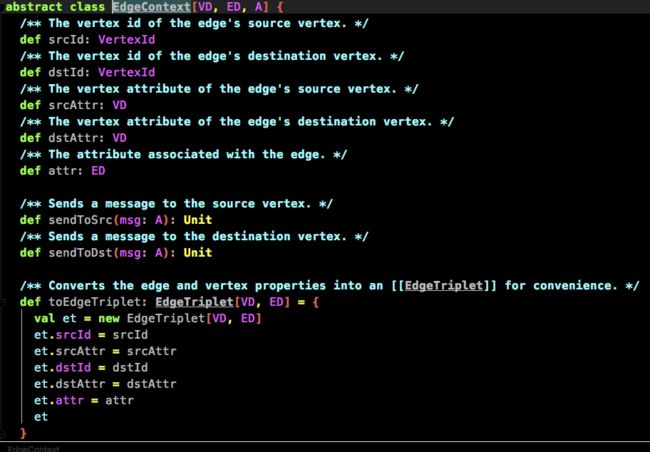
主要考虑

这两个方法
这两个方法一个吧triplets中数据发送到源节点
一个是把triplets中的数据发送到目的节点
这样就可以在源或者目的节点进行聚合操作了
看个例子:
graph.aggregateMessages[Int](_.sendToSrc(1), _ + _).foreach(println)
这个例子就是求出图的出度
sendToSrc(1)会针对每一个triplets向源节点发送1
如图

会向2节点发送一个1
_ + _ :表示针对每个节点做相加的聚合
比如下图5节点有4个triplets,采用sendToSrc方法后,它的聚合就是1+1 = 2
也就是它的出度

结果是
(4,1)
(3,1)
(5,3)
(2,1)
- Pregel
先看源码
def apply[VD: ClassTag, ED: ClassTag, A: ClassTag]
(graph: Graph[VD, ED],
initialMsg: A,
maxIterations: Int = Int.MaxValue,
activeDirection: EdgeDirection = EdgeDirection.Either)
(vprog: (VertexId, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexId, A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
(1)graph:
输入的图
(2) initialMsg:
初始化消息,在第一次迭代的时候,这个初始消息会被用来初始化图中的每个节点,在pregel进行调用时,会首先在图上使用mapVertices来根据initialMsg的值更新每个节点的值,至于如何更新,则由vprog参数而定,vprog函数就接收了initialMsg消息做为参数来更新对应节点的值
(3) maxIterations:
最大迭代的次数
(4) activeDirection:
活跃方向,首先理解活跃消息与活跃顶点,活跃节点是指在某一轮迭代中pregel以sendMsg和mergeMsg为参数来调用graph的aggregateMessage方法后收到消息的节点,活跃消息就是这轮迭代中所有被成功收到的消息。这样一来,有的边的src节点是活跃节点,有的dst节点是活跃节点,而有的边两端节点都是活跃节点。如果activeDirection参数指定为“EdgeDirection.Out”,则在下一轮迭代时,只有接收消息的出边(src—>dst)才会执行sendMsg函数,也就是说,sendMsg回调函数会过滤掉”dst—>src”的edgeTriplet上下文参数
EdgeDirection.Out —sendMsg gets called if srcId received a message during the previous iteration, meaning this edge is considered an “out-edge” of srcId.
EdgeDirection.In—sendMsg gets called if dstId received a message during the previous iteration, meaning this edge is considered an “in-edge” of dstId.
EdgeDirection.Either—sendMsg gets called if either srcId or dstId received a message during the previous iteration.
EdgeDirection.Both —sendMsg gets called if both srcId and dstId received mes- sages during the previous iteration.
(5) vprog:
节点变换函数,在初始时,在每轮迭代后,pregel会根据上一轮使用的msg和这里的vprod函数在图上调用joinVertices方法变化每个收到消息的节点,注意这个函数除初始时外,都是仅在接收到消息的节点上运行,这一点可以从源码中看到,源码中用的是joinVertices(message)(vprog),因此,没有收到消息的节点在join之后就滤掉了
(6) sendMsg:
消息发送函数,该函数的运行参数是一个代表边的上下文,pregel在调用aggregateMessages时,会将EdgeContext转换成EdgeTriplet对象(ctx.toEdgeTriplet)来使用,用户需要通过Iterator[(VertexId,A)]指定发送哪些消息,发给那些节点,发送的内容是什么,因为在一条边上可以发送多个消息,有sendToDst和sendToSrc,所以这里是个Iterator,每一个元素是一个tuple,其中的vertexId表示要接收此消息的节点的id,它只能是该边上的srcId或dstId,而A就是要发送的内容,因此如果是需要由src发送一条消息A给dst,则有:Iterator((dstId,A)),如果什么消息也不发送,则可以返回一个空的Iterator:Iterator.empty
(7) mergeMsg:
邻居节点收到多条消息时的合并逻辑,注意它区别于vprog函数,mergeMsg仅能合并消息内容,但合并后并不会更新到节点中去,而vprog函数可以根据收到的消息(就是mergeMsg产生的结果)更新节点属性
-
(最小路径算法)
从图上可以看出最小路径算法Dijkstra的原理
a. 初始时,S只包含源点,即S={v},v的距离为0。U包含除v外的其他顶点,即:U={其余顶点},若v与U中顶点u有边,则
b. 从U中选取一个距离v最小的顶点k,把k,加入S中(该选定的距离就是v到k的最短路径长度)。
c. 以k为新考虑的中间点,修改U中各顶点的距离;若从源点v到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,修改后的距离值的顶点k的距离加上边上的权。
d. 重复步骤b和c直到所有顶点都包含在S中。
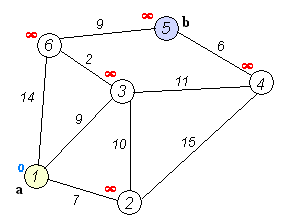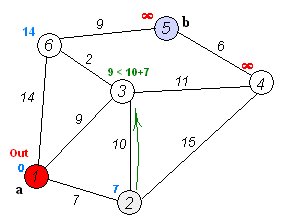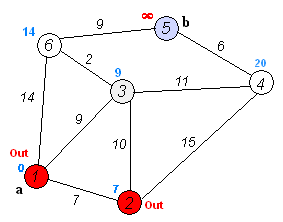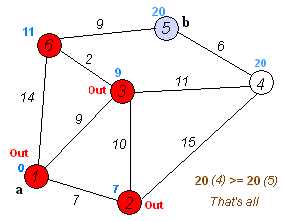 最小路径
最小路径 -
在GRAPHX中
GraphX 采用顶点切分方式进行分布式图分割
 边切分与顶点切分
边切分与顶点切分
GraphX 不是沿着边沿分割图形,而是沿着顶点分割图形,这可以减少通信和存储开销,在逻辑上,这对应于将边缘分配给机器并允许顶点跨越多台机器。分配边缘的确切方法取决于PartitionStrategy各种启发式的几种折衷。用户可以通过与Graph.partitionBy运算符重新分区图来选择不同的策略。默认分区策略是使用图形构建中提供的边的初始分区(使用边的 srcId 进行哈希分区,将边数据以多分区形式分布在集群),另外,顶点 RDD 中还拥有顶点到边 RDD 分区的路由信息——路由表.路由表存在顶点 RDD 的分区中,它记录分区内顶点跟所有边 RDD 分区的关系.在边 RDD 需要顶点数据时(如构造边三元组),顶点 RDD 会根据路由表把顶点数据发送至边 RDD 分区。
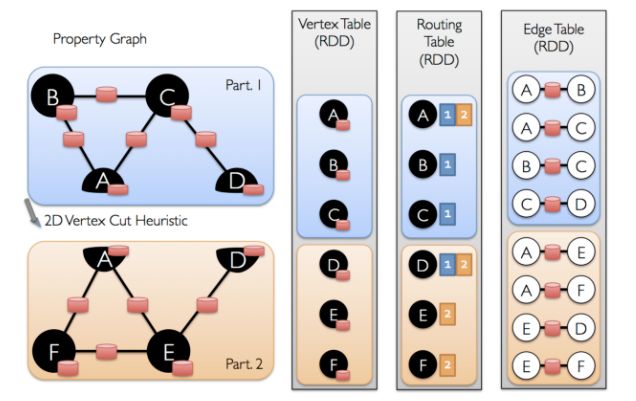 分区
分区
如下图按顶点分割方法将图分解后得到顶点 RDD、边 RDD 和路由表
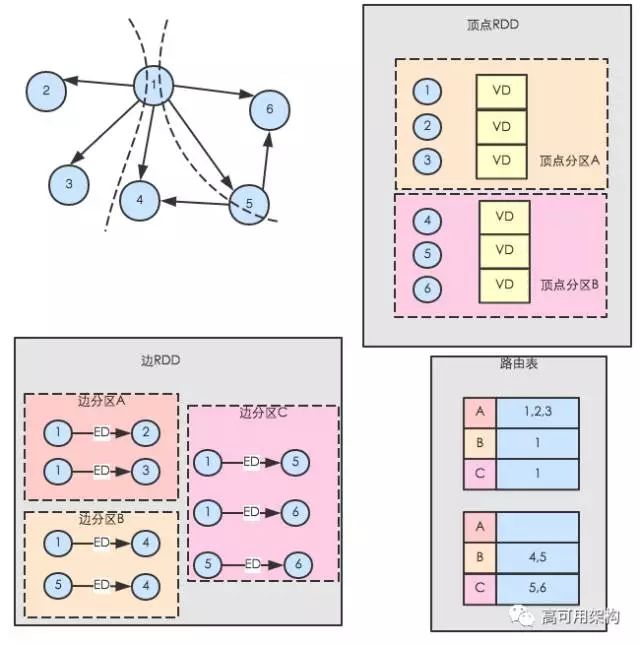 分区解释图
分区解释图
GraphX 会依据路由表,从顶点 RDD 中生成与边 RDD 分区相对应的重复顶点视图( ReplicatedVertexView),它的作用是作为中间 RDD,将顶点数据传送至边 RDD 分区。重复顶点视图按边 RDD 分区并携带顶点数据的 RDD,如图下图所示,重复顶点分区 A 中便携了带边 RDD 分区 A 中的所有的顶点,它与边 RDD 中的顶点是 co-partition(即分区个数相同,且分区方法相同),在图计算时, GraphX 将重复顶点视图和边 RDD 按分区进行拉链( zipPartition)操作,即将重复顶点视图和边 RDD 的分区一一对应地组合起来,从而将边与顶点数据连接起来,使边分区拥有顶点数据。在整个形成边三元组过程中,只有在顶点 RDD 形成的重复顶点视图中存在分区间数据移动,拉链操作不需要移动顶点数据和边数据.由于顶点数据一般比边数据要少的多,而且随着迭代次数的增加,需要更新的顶点数目也越来越少,重复顶点视图中携带的顶点数据也会相应减少,这样就可以大大减少集群中数据的移动量,加快执行速度。
 重复顶点视图
重复顶点视图
重复顶点视图有四种模式
(1)bothAttr: 计算中需要每条边的源顶点和目的顶点的数据
(2)srcAttrOnly:计算中只需要每条边的源顶点的数据
(3)destAttrOnly:计算中只需要每条边的目的顶点的数据
(4)noAttr:计算中不需要顶点的数据
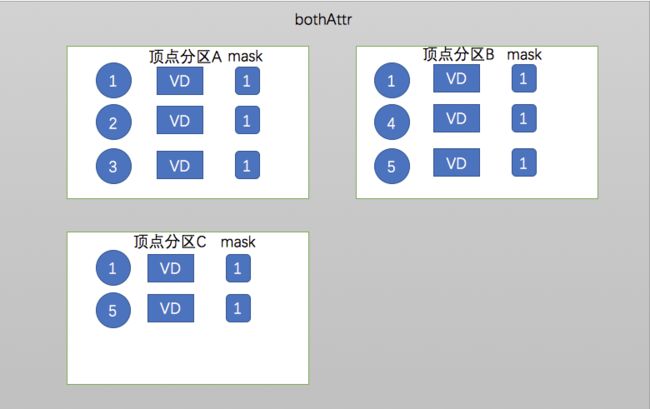 bothAttr
bothAttr
 srcAttrOnly
srcAttrOnly
 destAttrOnly
destAttrOnly
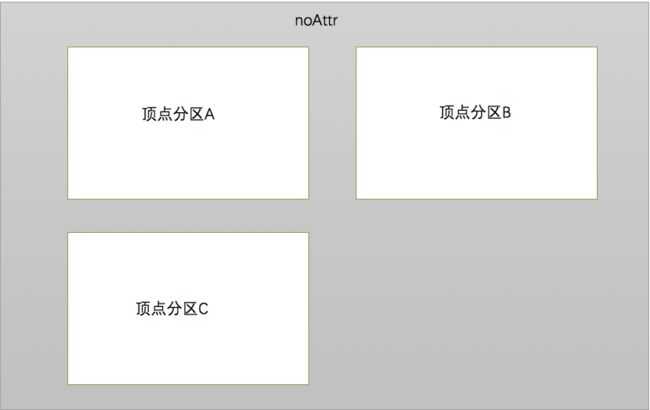 noAttr
noAttr
重复顶点视图创建之后就会被加载到内存,因为图计算过程中,他可能会被多次使用,如果程序不再使用重复顶点视图,那么就需要手动调用GraphImpl中的unpersistVertices,将其从内存中删除。
生成重复顶点视图时,在边RDD的每个分区中创建集合,存储该分区包含的源顶点和目的顶点的ID集合,该集合被称作本地顶点ID映射(local VertexId Map),在生成重复顶点视图时,若重复顶点视图时第一次被创建,则把本地顶点ID映射和发送给边RDD各分区的顶点数据组合起来,在每个分区中以分区的本地顶点ID映射为索引存储顶点数据,生成新的顶点分区,最后得到一个新的顶点RDD,若重复顶点视图不是第一次被创建,则使用之前重复顶点视图创建的顶点RDD预发送给边RDD各分区的丁带你更新数据进行连接(join)操作,更新顶点RDD中顶点的数据,生成新的顶点RDD。
GraphX 在顶点 RDD 和边 RDD 的分区中以数组形式存储顶点数据和边数据,目的是为了不损失元素访问性能。同时,GraphX 在分区里建立了众多索引结构,高效地实现快速访问顶点数据或边数据。在迭代过程中,图的结构不会发生变化,因而顶点 RDD、边 RDD 以及重复顶点视图中的索引结构全部可以重用,当由一个图生成另一个图时,只须更新顶点 RDD 和边 RDD 的数据存储数组,因此,索引结构的重用保持了GraphX 高性能,也是相对于原生 RDD 实现图模型性能能够大幅提高的主要原因。
-分区方式简介
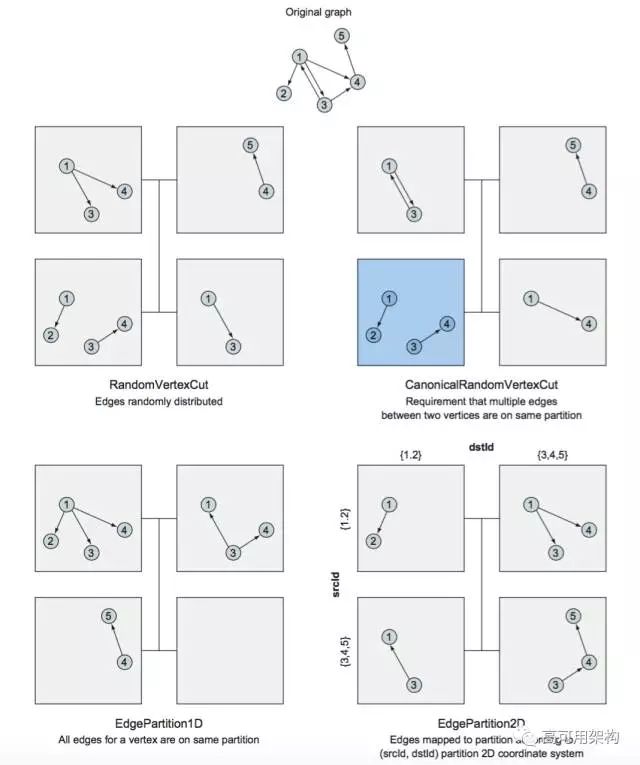
算法
- 最小路径算法
val sourceId: VertexId = 5L
val initialGraph = graph.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)
val sssp = initialGraph.pregel(
Double.PositiveInfinity,
activeDirection = EdgeDirection.Out
)(
(vertexId, vertexValue, msg) =>
math.min(vertexValue, msg),//vprog,作用是处理到达顶点的参数,取较小的那个作为顶点的值
triplet => { //sendMsg,计算权重,如果邻居节点的属性加上边上的距离小于该节点的属性,说明从源节点比从邻居节点到该顶点的距离更小,更新值
if (triplet.srcAttr + triplet.attr < triplet.dstAttr) {
Iterator((triplet.dstId, triplet.srcAttr + triplet.attr))
} else {
Iterator.empty
}
},
(a, b) => math.min(a, b) //mergeMsg,合并到达顶点的所有信息
)
println(sssp.vertices.collect.mkString("\n"))
以上代码是求节点ID为5的所有可到达节点的最短路径
算法详解:首先initialGraph就先遍历所有的节点吧我们设置的目标节点设置的属性值设置成0.0其他的所有节点设置成正无穷,pregel中的Double.PositiveInfinity是初始化参数,在pregel执行的过程中的第一次迭代时,会初始化所有的节点属性值,会根据下边的vprog = (vertexId, vertexValue, msg) => math.min(vertexValue, msg),//(vprog,作用是处理到达顶点的参数,取较小的那个作为顶点的值)去处理所有的节点,所以,初始化后除了5节点的属性值为0.0外,其他的都是正无穷。activeDirection = EdgeDirection.Out限定所有的有效方向是出边,triplet限定了只有在每次迭代中满足triplet.srcAttr + triplet.attr < triplet.dstAttr条件的才会更新当前节点值,最后(a, b) => math.min(a, b)方法合并了迭代到当前所有接受到消息的顶点的属性值,也就是说找到源顶点到可达顶点中的路径最小的那个可达顶点。不断的迭代下去,最后扫描完整个图,最终得出到所有可达顶点最短路径。
- 找出目标节点所有的2跳节点
val friends = Pregel(
graph.mapVertices((vid,value) => if(vid ==2) 2 else -1),//初始化信息,源节点为2,其他节点为-1
-1,
2,
EdgeDirection.Either
)(
vprog = (vid,attr,msg) =>math.max(attr, msg),//顶点操作,到来的属性和原属性比较,较大的作为该节点的属性
edge => {
if (edge.srcAttr <= 0) {
if (edge.dstAttr <= 0) {
Iterator.empty//都小于0,说明从源节点还没有传递到这里
}else {
Iterator((edge.srcId,edge.dstAttr - 1))//目的节点大于0,将目的节点属性减一赋值给源节点
}
}else {
if(edge.dstAttr <= 0) {
Iterator((edge.dstId,edge.srcAttr -1))//源节点大于0,将源节点属性减一赋值给目的节点
}else {
Iterator.empty//都大于0,说明在二跳节点以内,不操作
}
}
},
(a,b) => math.max(a, b)//当有多个属性传递到一个节点,取大的,因为大的离源节点更近
).subgraph(vpred =(vid,v) =>v >= 0)
friends.vertices.collect.foreach(println(_))
算法详解:首先,把目标节点的属性值置为2,初始化其他的所有的节点的属性值为-1,第一次迭代消息(-1)初始化就是根据vprog = (vid, attr, msg) => math.max(attr, msg)再过滤一遍节点,在剩下的迭代过程中,edge中的条件限定只扫描:
(1)如果源小于0,目标也小于0,则不发消息
(2)如果源小于0,目标大于0,则目标值-1赋给源节点
(3)如果源大于0,目标值也大于0,则不发消息
(4)如果源大于0,目标值小于0,则把源-1赋给目标节点
也就是说只会在有正负差距的的节点之间才会有消息传递
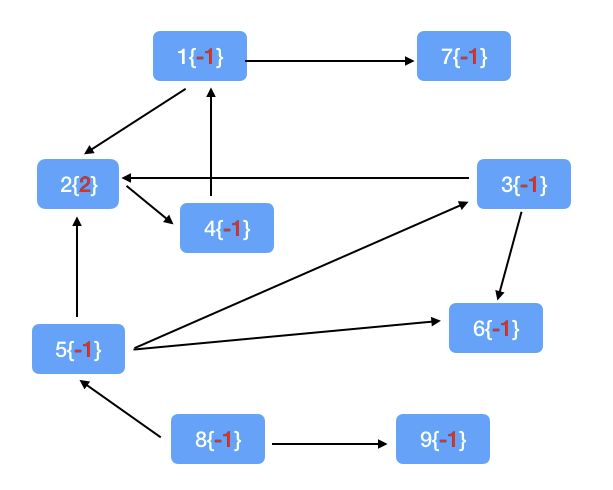

算法
- pageRank
该算法就不过多介绍了,直接上代码,基于graphx的实现,想了解具体算法的请百度或者google一大堆
这里首先假设了你已经加载了一个图
graph.pageRank(0.001,0.15)
.vertices //列出所有点
.sortBy(_._2, false) //根据pagerank降序排序
.take(20) //取出前20个
.foreach(println)
很简单,解释下参数:0.001是个容忍度,是在对下边公式进行迭代过程中退出迭代的条件,0.15也是默认的初始跳转概率,也就是公式中的resetProb
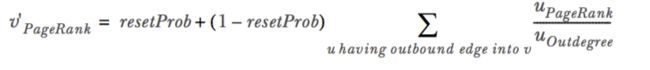
- 个性化pageRank
该算法主要用于推荐中,比如社交网络中,对于某个人来说,你想给他再推荐一个人,当然这个被推荐的这个人肯定是那个某人感兴趣的。或者对于用户商品的推荐中,用户商品两个实体可以形成一个图,我们就可以根据具体的某个用户来给他推荐一些商品
graph.personalizedPageRank(34175, 0.001) //某人是34175
.vertices
.filter(_._1 != 34175)
.reduce((a,b) => if (a._2 > b._2) a else b) //找出那个34175感兴趣的人
- 三角环统计
三角环统计应用场景:大规模的社区发现,通过该算法可以做群体性检测,社交网络中就是那种组团的、关系复杂的,互相有一腿情况比较多的。也就是说,在某个用户下边,这个人拥有越多的三角形环,那么这个人就拥有越多的连接,这样就可以检测一些小团体,小派系等,同时也可以支持一些推荐,确认一些造谣生事者(能够根据图去找到谣言的散播者),只要是跟大规模小团体检测方面该算法都可以很好的支持
graph.triangleCount()
.vertices
.sortBy(_._2, false)
.take(20)
.foreach(println)
找出拥有三角形环关系的最多的顶点
- 最短路径算法
最酸路径算法的原理上面已经说过了,现在利用graphx内置的方式实现
ShortestPaths.run(diseaseSymptom,Array(19328L))
.vertices
.filter(!_._2.isEmpty)
.foreach(println)
其中19328L是自定义的起始点
(266,Map(19328 -> 15))
(282,Map(19328 -> 12))
(770,Map(19328 -> 9))
(1730,Map(19328 -> 11))
(2170,Map(19328 -> 6))
(1530,Map(19328 -> 13))
(1346,Map(19328 -> 14))
(378,Map(19328 -> 3))
(1378,Map(19328 -> 11))
(970,Map(19328 -> 10))
...
结果如上,(266,Map(19328 -> 15))表示19328到266的最短路径为15
-
独立群体检测:
独立群体检测就是发现那些不合群的成分,如下图:
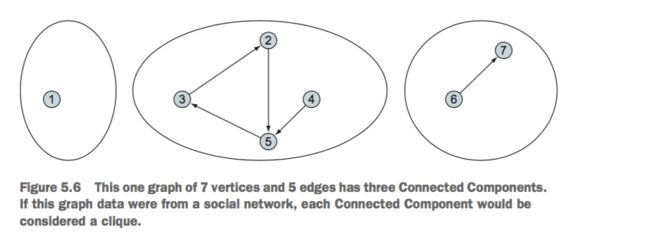 独立成分
独立成分
val g = Graph(sc.makeRDD((1L to 7L).map((_,""))),
sc.makeRDD(Array(Edge(2L,5L,""), Edge(5L,3L,""), Edge(3L,2L,""),
Edge(4L,5L,""), Edge(6L,7L,""))))
g.connectedComponents
.vertices
.map(_.swap)
.groupByKey()
.map(_._2)
.foreach(println)
输出结果:
CompactBuffer(6, 7)
CompactBuffer(4, 2, 3, 5)
CompactBuffer(1)
-
强连接网络
所谓的强连接网络就是:在这个网络中无论你从哪个顶点开始,其他所有顶点都是可达的,就如下图:
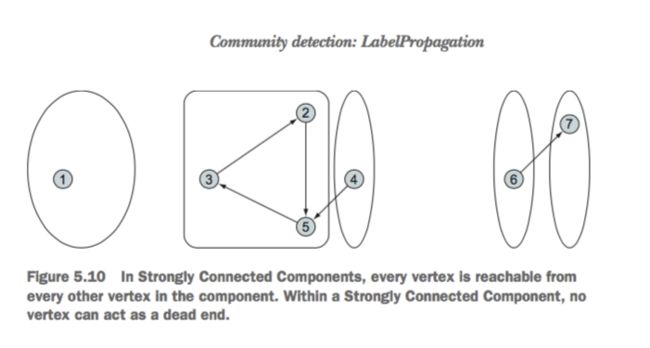 强连接网络
强连接网络
g.stronglyConnectedComponents(3)
.vertices.map(_.swap)
.groupByKey()
.map(_._2)
.foreach(println)
其中3是最大迭代次数,在上边图中,迭代三次刚好,也可以设置的大一点,不过结果都是一样的
-
标签传播算法(LPA)
主要是用于团体检测,LPA能够以接近线性复杂度去检测一个大规模图中的团体结构,主要思想是给所有顶点中的密集连接组打上一个唯一标签,这些拥有相同标签的组就是所谓的团体
该算法常常是不收敛的,如下图
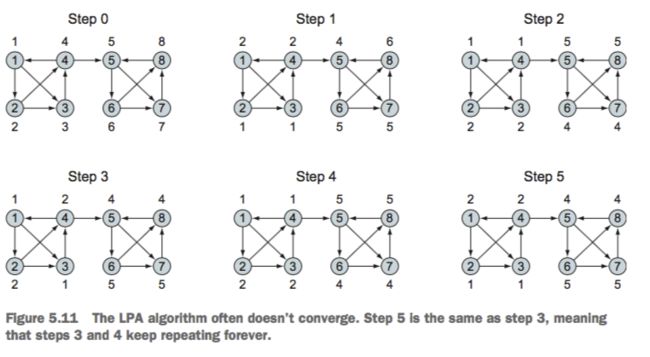 标签传播算法
标签传播算法
该算法也可以用于半监督学习(大部分没有标签,小部分有标签),给那些没有标签的通过标签传播算法进行打标签。也可以应用于风控,对于通过已有风险评估的人,通过社交网络去评估何其有关系的人的风险
-
Dijkstra算法的实现
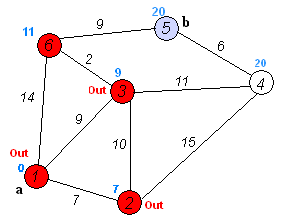 算法图
算法图
就拿这个图为例
算法步骤就是:
(1)首先初始化图,把起始目标节点属性值设置成0,其他的节点设置成正无穷,同时把节点状态全部设置成未激活状态
(2)然后进入迭代操作,迭代的次数为所有顶点的个数,进入迭代过程:找到当前的节点(就是每次迭代过程中红色的点),每次迭代都会生成一个新的图,主要是因为RDD是不可变的,如果想更新一个RDD就必须生成一个新的RDD然后把两个RDD再join起来,所以接下来就是生成新图的过程,针对刚才找到的当前节点,我们向它的目的指向顶点发送消息,消息就是当前节点的属性值加上指向边上的权重,然后再合并目的节点的属性值,取其中最小的属性值,其实就是选择当前节点的目的一个最优目的节点作为下一轮迭代的当前节点。在当前节点中,发送消以及合并目的节点的属性值以后就会生成一个新的图,为了更新初始图,我们这里只能outerJoinVertices,把两个图join起来,这样不停的迭代,直到所有顶点都是激活的
def dijkstra[VD](g:Graph[VD,Double], origin:VertexId) = {
//初始化起始节点的属性值
var g2 = g.mapVertices(
(vid,vd) => (false, if (vid == origin) 0 else Double.MaxValue))
for (i <- 1L to g.vertices.count-1) {
val currentVertexId =
g2.vertices.filter(!_._2._1)
.fold((0L,(false,Double.MaxValue)))((a,b) =>
if (a._2._2 < b._2._2) a else b)
._1
val newDistances = g2.aggregateMessages[Double](
ctx => if (ctx.srcId == currentVertexId)
ctx.sendToDst(ctx.srcAttr._2 + ctx.attr),
(a,b) => math.min(a,b))
g2 = g2.outerJoinVertices(newDistances)((vid, vd, newSum) =>
(vd._1 || vid == currentVertexId,
math.min(vd._2, newSum.getOrElse(Double.MaxValue))))
}
g.outerJoinVertices(g2.vertices)((vid, vd, dist) =>
(vd, dist.getOrElse((false,Double.MaxValue))._2))
}
待续-------