风控体系:事前、事中、事后调控
整个风控体系包括几个环节:
事前:在风险发生之前就要通过对风险舆情的监控发现风险,比如在某些恶意的欺诈团伙即将发动欺诈攻击前就采取措施来提前防御,比如通过规则加紧,把模型阈值调高等方法。
事中:信贷借款申请,在线上注册激活的过程中,根据自动风险评估,包括申请欺诈,信用风险等来选择是否拒绝发放贷款。
事后:贷款发放以后的风险监控,如果借款人会出现与其他平台的新增申请,或者长距离的位置转移,或者手机号停机等信号,可作为贷后风险预警。
如何提前在网络中把骗子揪出?
最基础的技术:设备指纹

在介绍整个风控体系时我认为,对于网络行为或者线上借贷,最最基础或者最最重要的技术是设备指纹。为什么呢?从上图中我们可以看到,网络上的设备模拟或攻击,比如各种各样的自动机器人,实际上是对网络环境造成极大的干扰,在信贷中会导致信用风险的误判。这个是第一道。
网络设备最关键的地方是要实现对设备唯一性的保证,第二是抗攻击,抗篡改。网上有各种高手会进行模拟器修改,修改设备的信息和干扰设备的定位等以各种手段来干扰设备的唯一性认定。
所以对抗这样的情况的技术要点在于:抗攻击、抗干扰、抗篡改。另一方面能够识别出绝大部分的模拟器。
设备定位:基站和WiFi三角定位
接下来就是设备定位。
非GPS定位
值得注意的是,在模拟器或者智能设备系统里面它可以把GPS定位功能关掉。而如果通过将基站的三角计算或者WIFI的三角计算定位结合起来,定位的精度较高,且不受GPS关闭的影响。
这可以应用在信贷贷后管理,用来监测借款人的大范围位置偏移。
地址的模糊匹配

对于位置来讲还有一个重要方面是地址的模糊匹配。在信用卡或者线下放贷中,地址匹配是一个重要的风险审核因素,但是地址审批过程存在一个问题:平台与平台之间因为输入格式不同或者输入错误等问题造成难以匹配,那就需要模糊算法来进行两两匹配,以及数个地址之间进行比对,或者在存量库中搜索出历史中的风险或者相关性名单来进行比对。这其中涉及的技术包括模糊匹配算法和海量地址的管理和实时比对。
复杂网络
复杂网络有时候大家称之为知识图谱,但这中间有点区别:复杂网络更偏向于从图论的角度进行网络构建后进行实体结构算法分析,知识图谱更偏重于是在关联关系的展现。
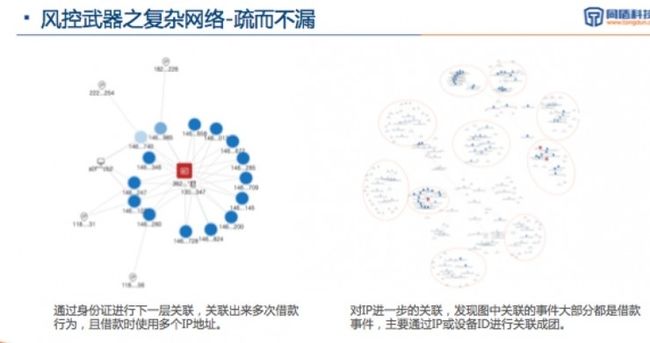
网络分析最重要的一点是具有足够的数据量,能够对大部分网络行为进行监控和扫描,同时形成相应的关联关系,这不仅是实体与实体之间、事件与事件的关系,并且体现出“小世界(7步之内都是一家人)”、“幂分布”等特征。
举个例子:团伙性欺诈嫌疑识别。有一个被拒绝的用户中,关联出来了一个失信的身份证和设备,而且发现其设备有较多的申请行为,那么,这个被关联出来的用户或将需要严格的人工审核,甚至可以直接拒绝。
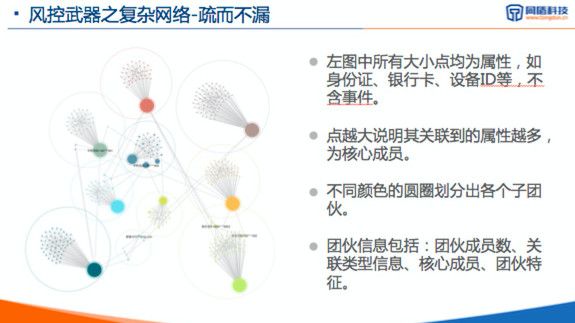
通过对借款事件的深入挖掘,我们可以关联出大量的借款事件。这个需要进行一些算法分团,可以把相关的联系人都分到一个地方,然后进行关联成团的团伙性分析,根据图论上的属性如团的密集程度和某些路径的关键程度等,比如介数,图直径等角度来估计风险。
数据抽样结果案例:骗子遁形
通过对内部大量数据的抽样分析,可以看到一些意思的现象:潜在的威胁者,出于恶意目的,他的行为会和正常的用户有所不同。这里面有几个例子可以分享:
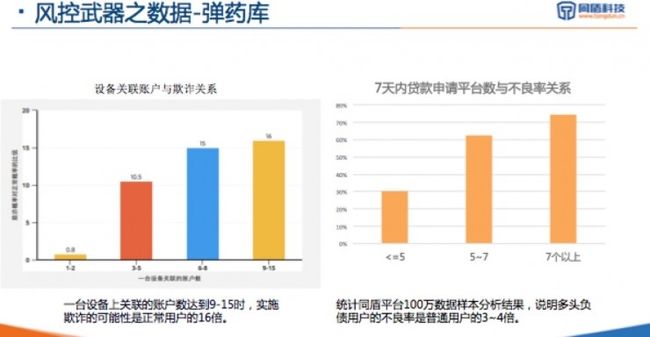
其中一个是设备与关联账户的数量与欺诈风险的关系。当然这不仅包括了信贷行业的欺诈,还包括账户层面的盗取账户、作弊、交易等欺诈风险。可以看到,当设备关联账户量大于3-5个时,其风险系数明显增高。此外,当关联数量大于五时,风险率也是明显偏高。
另外一个是对于多头负责与不良率的比较:7天内贷款平台数高于5时其风险也是明显偏高的。虽然这个数据还没有做进一步的清洗和交叉衍生新的变量,但也可以看出其中的风险相关程度。
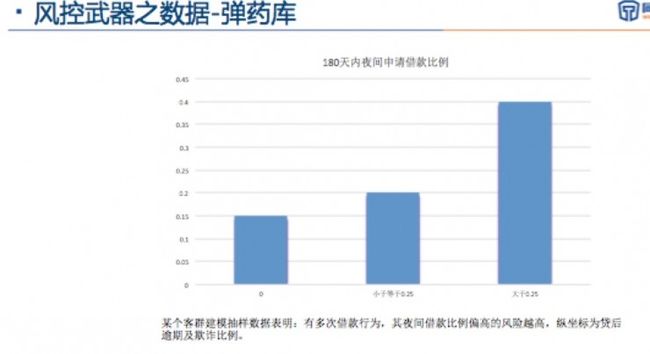
另外是某个特定客群的建模抽样分析。例如多次借款申请人如果180天内夜间申请借款的比例——就是有借款行为的同时,如果大于四分之一的借款申请是在夜间的,其风险明显增加。
数据都是客观的,取决于数据形成后对业务的分析和解读。
优秀的决策引擎是怎样的?
一个优秀的决策引擎包括以下几点:
灵活可配——不但可以配规则,还可以配规则的字段和权重。业务友好就不用说了。
快速部署——配置好的规则模型可以实时生效,当然如果涉及一般规则修改时,可以做一个灰度部署。
决策流——它可以把不同的规则和模型串到一起,形成一个决策流,实现贷前、贷中、贷后的全流程监控。它要可以实现对数据的按需调用,比如把成本低的数据放到前面,逐步把成本较高的数据放到后面。因为有些决策在前面成本较低的数据下已经可以形成,就不必调用高成本的数据。
AB测试和冠军挑战——对于规则修改、调优时尤其重要。两套规则跑所有的数据,最终来比较规则的效果。另一种是分流——10%跑新规则,90%跑老规则,随着时间的推移来根据测试结果的有效性。
支持模型的部署——线性回归、决策树等简单模型容易将其变成规则来部署,但支持向量机、深度学习等对模型支持的功能有更高的要求。
信用评估
那经过以上的手段,我们基本可以具有一个很强的力度来排除信用风险,那么以下便是信用评估阶段。
评分卡模型
评分卡分为申请、行为、催收评分卡。申请评分卡用于贷前审核;行为评分卡作为贷中贷后监控,例如调额,提前预知逾期风险。它可以通过历史的数据和个人属性等角度来预测违约的概率。信用评分主要用于信用评分过程中的分段,高分段可以通过,低分段可以直接拒绝。
因为行业不同,客群与业务不同,评分卡的标准也有所不同。对于有历史表现的客户,我们可以将双方的XY变量拿出来,进行一个模型共建,做定制化的评分。

构建一个评分卡模型,目前传统的方法是银行体系中使用的:数据清洗、变量衍生、变量选择然后进行逻辑回归这样一个建模方式。
那么机器学习和传统方法最主要的区别是变量选取过程的不同——如果还是基于传统的变量选取方法,那通过机器学习训练出来的模型,其实还是传统的模型,其模型虽然一个非线性模型,但是其背后体现不出机器学习的优势。
核心技术与挑战
在目前围绕大数据、大数据决策为核心的风控技术体系中,整体的数据量达到一定水平,存在的挑战将会是数据的稀疏化。随着风控业务覆盖的行业越来越多,平台间的数据稀疏问题就越明显。(雷锋网(公众号:雷锋网)注:“稀疏数据”即矩阵中含零元素特别多,这意味着无益于增加数据信息量的无用元素很多,对于数据从存储,处理到建模都有挑战。)
此外,其实对于大数据来说,即便具有数据和大数据决策,如果没有一个很稳定的落地平台也是一个空中楼阁。大数据应用要做到完整,还需要符合以下要求的平台:一是容纳量,能够容纳特别多的数据;一个是响应:任何决策都能实时响应;一个是并发,在大量数据并发时也能保持调用。此外,安全性自不待言。
问答:
问:深度学习是怎么用于风险控制的呢?
董骝焕:深度学习本身个框架,是结合非监督学习和监督学习的神经网络训练和部署的框架,只要有目标,有数据就可以衍生特征,就可以做目标训练,可以当成一般机器学习去用。当然深度学习有些优势,比如无监督的特征选取方式,另外训练的过程中虽然计算量比较大,但也是可以接受的。
概括地说你可以认为深度学习是模型的一种。因为深度学习有些特殊的优势,比如特征选取的自动产生,即无监督方式。 另外,它可以实现稀疏数据结构的特征生成,而且可以通过正则化的方式来控制特征的生成,这对于具有大量数据,同时维度特别多,而且稀疏化的情况时就特别有用。
问:有一个问题,有没有一种可能,对于用户画像,判断的维度越多,得到的一些结论是冲突的。这个情况如果存在,是怎么协调,看权重么?
董骝焕:如果传统的方法,这些维度,比如几千个维度经过模型变量的筛选,有些变量是值越高越正面,有些是值越低越正面,就是WOE是不同的方向,这种情况下可以通过建模的方式来进行权重的训练,来做一个协调。
问:根据最新关于互联网金融平台法规的实施,从数据平台的角度分析下,大数据是否会取代以后的人工审核?您对互金风控未来的发展趋势认为是什么样的?
董骝焕:确实取决于不同信贷产品。比如小微的信贷产品,其立足点也许是经营性的评估,甚至包括现场的实际调研——水、电、煤,以及税务调查。而对于一些小额分散的信贷产品,比如信用卡代偿,这些由于量太大金额又很小,人工审核的话成本会太高。当然还有一些中间层面的,比如几千到几万元的借贷,这种情况当前更多还是互相并存的方式。
至于“未来互联网审核取代人工审核”这个命题,我认为更多取决于线上个人身份认证问题的解决。也就是说,目前线上没有真正能完全规避伪冒的风险,包括活体认证和手持拍照等措施,尤其是大金额,走线上途径还是有一定风险的,因此需要从信贷流程的各个维度来控制。
对于未来的风控我认为是往风险经营走,2个方向:一个是个人定制化,让每个人都有不同的风险识别,以及对应的信贷产品。另外是最优化的授信,实现平台的某个目标的最大化,比如收入最大化、利润最大化,此外还有市场占有最大化——对于低风险人群的容忍,这当然取决于一个平台的风险偏好,但这个风险偏好最大的基础是对风险的准确识别,这样相应的风险优化才是有效的。