前言
本文主要是以笔记的整理方式写的,
仅以分享的方式供你阅读,
如有不对的地方欢迎指点错误。
读完本文可以学到:
当你用 shell 命令执行 spark-submit 之后,
到你的代码开始正式运行的一些列知识和细节,
恩...粗略的,要看的更细,可以按照流程自己撸源码哈~~~~
SparkSubmit
- Spark-Submit脚本执行后,
会执行到org.apache.spark.deploy.SparkSubmit
所以我们从SparkSubmit类开始,
以下是org.apache.spark.deploy.SparkSubmit简单的时序图
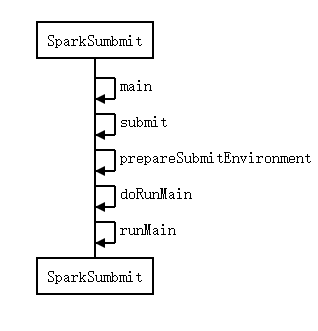
- main方法:
- 解析我们传入的参数
- 根据 action 执行相对应的功能
当然这里我们的 Action 是:SparkSubmitAction.SUBMIT
def main(args: Array[String]): Unit = {
val appArgs = new SparkSubmitArguments(args)
if (appArgs.verbose) {
// scalastyle:off println
printStream.println(appArgs)
// scalastyle:on println
}
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
- prepareSubmitEnvironment:
该方法主要是进行四个参数的解析:
···
private[deploy] def prepareSubmitEnvironment(args:
SparkSubmitArguments) : (Seq[String], Seq[String], Map[String, String], String) = { // Return values
val childArgs = new ArrayBuffer[String]()
val childClasspath = new ArrayBuffer[String]()
val sysProps = new HashMap[String, String]()
var childMainClass = ""
...
返回值
(childArgs, childClasspath, sysProps, childMainClass)
- childArgs: 主要就是一些参数的
- childClasspath:这个就是classPath,jvm运行的class路径
- sysProps:一些系统参数
- childMainClass:接下来将要运行的主类
- 如果是 Client模式,则该类就是我们自己编写的
- 如果是Cluster 模式,则根据集群的不同返回不同的类:
isStandaloneCluster:org.apache.spark.deploy.Client
isYarnCluster:org.apache.spark.deploy.yarn.Client
- runMain
- 加载 childClasspath下的 jars
- 设置系统参数 sysProps
- 运行 mainMethod,并传递参数
mainMethod.invoke(null, childArgs.toArray)
至此Sumbmit任务完成,接下来我们以 Standalone Client为列,
进行org.apache.spark.deploy.Client相关源码分析
ClientEendpoint
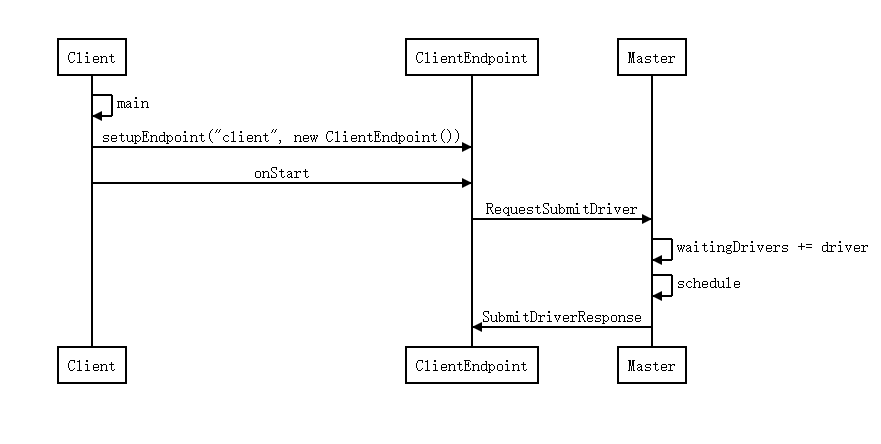
- 创建
ClientEendpoint,并将Master注册到ClientEendpoint -
ClientEendpoint的onstart方法被调起,
构建 DriverDescription,
并指定 Drive r的主类是org.apache.spark.deploy.worker.DriverWrapper
向 Master 申请RequestSubmitDriver(driverDescription) - Master 端收到请求后构建
DriverInfo并加入到队列:
waitingDrivers += driver
drivers.add(driver) - master开始调度
schedule(),并回复客户端申请成功的消息 - 在Master的 schedule() 里面开始准备启动Driver
这里主要是将整条线理清楚了,
没有纠结细节,
如果有兴趣你可以按照这个线自己去看下源码
那么接下来就是启动Driver的过程了
Master调度
注意查看源码里面写的注释,
千万不要略过,
要不然本文就没啥意思了~~~
private def schedule(): Unit = {
if (state != RecoveryState.ALIVE) { return }
// 将worker打乱,主要就是为了负载均衡
val shuffledWorkers = Random.shuffle(workers)
//筛选存活的 worker
for (worker <- shuffledWorkers if worker.state == WorkerState.ALIVE) {
// 遍历等待启动的Driver
for (driver <- waitingDrivers) {
//如果该worker内存和core都满足要求
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
// 启动Driver
launchDriver(worker, driver)
waitingDrivers -= driver
}
}
}
//实际上还会去启动Executor,
//但是我们目前不关注这里,略过
startExecutorsOnWorkers()
}
我们重点看下 launchDriver做了什么
private def launchDriver(worker: WorkerInfo, driver: DriverInfo) {
//将driver的信息记录下来
worker.addDriver(driver)
// driver现在知道他该在哪个worker启动了
driver.worker = Some(worker)
// 向worker节点发送 LaunchDriver
worker.endpoint.send(LaunchDriver(driver.id, driver.desc))
// 标记driver已经运行,实际是Driver可能还没启动呢!!!
driver.state = DriverState.RUNNING
}
launchDriver主要就是给 Worker 发送了启动 Driver 的消息
接下来就可以看看 Worker 端是怎么处理 LaunchDriver 这个消息的了。
Wroker调度
//节选代码,不要介意是 case 开头
case LaunchDriver(driverId, driverDesc) => {
logInfo(s"Asked to launch driver $driverId")
//new一个 DriverRunner
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),
self,
workerUri,
securityMgr)
//DriverRunner start
drivers(driverId) = driver
driver.start()
//记录下消耗的资源
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
}
重点看到 DriverRunner 的 Start 方法
new Thread("DriverRunner for " + driverId) {
override def run(){
...
//创建driver工作目录
val driverDir = createWorkingDirectory()
//下载一些jars
val localJarFilename = downloadUserJar(driverDir)
...
// 通过系统的指令创建 jvm进程,至此正式启动
launchDriver(builder, driverDir, driverDesc.supervise)
}
}.start()
driver的启动是通过一个 DriverRunner类开启一个线程异步启动的,
其过程没有什么特殊的地方,
至此 Driver 正式启动完成了。
接下来就是分析 Driver 主类的启动了
org.apache.spark.deploy.worker.DriverWrapper
而实际上,该类主要的作用就是会:
// Delegate to supplied main class
val clazz = Utils.classForName(mainClass)
val mainMethod = clazz.getMethod("main", classOf[Array[String]])
mainMethod.invoke(null, extraArgs.toArray[String])
调起我们自己写的主类方法,
至此,从我们敲下Spark-Submit之后,
终于执行到我们自己所写的代码了。
结言
Spark这部分源码流程比较简单清楚,
基本没有太多弯弯道道,
但是就算简单,那也是需要你自己去琢磨去看的,
否则你还是不能清楚的知道,
你的那个 spark-submit 敲下之后,
怎么就执行到你的代码了呢?
OK,就到这里了,
如果没有意外,
本人应该会继续更新一系列的Spark源码文章,
如果你有兴趣,不妨关注一下,
最后,求赞 ~~~~