reddit是一个国外的论坛性质的东西,为了做chatbot,所以准备爬一些数据下来。
准备工作
—— scrapy框架的安装和熟悉
可参考网页:
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html
http://www.jianshu.com/p/7a146c848388
—— 网页结构分析
用firefox打开reddit,搜索chat
得到的网页为https://www.reddit.com/search?q=chat&type=sr&count=4&before=t5_2uul1
下图是搜索结果页面,然后有很多个分板块,来看看如何一步一步分析得到每一句对话。
注:下面查看xpath的方式都是用Firebug查看的,比较方便
1. 获取同一页上的不同板块
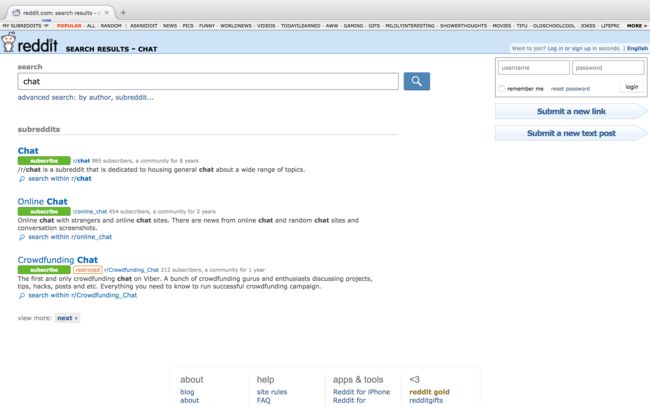
以第二个板块为例,它的链接网页为
https://www.reddit.com/r/online_chat/
它在html文件中的显示为
Online
Chat
它的xpath为
/html/body/div[5]/div[2]/div/div/div[2]/header/a
现在来看看第一个板块chat的xpath
/html/body/div[5]/div[2]/div/div/div[1]/header/a/
所以获取的方式为
pages = selector.xpath('/html/body/div[5]/div[2]/div/div/div/header/a/@href').extract()
2. 获取下一页
再来看下一页的网页为https://www.reddit.com/search?q=chat&type=sr&count=3&after=t5_3d7l3
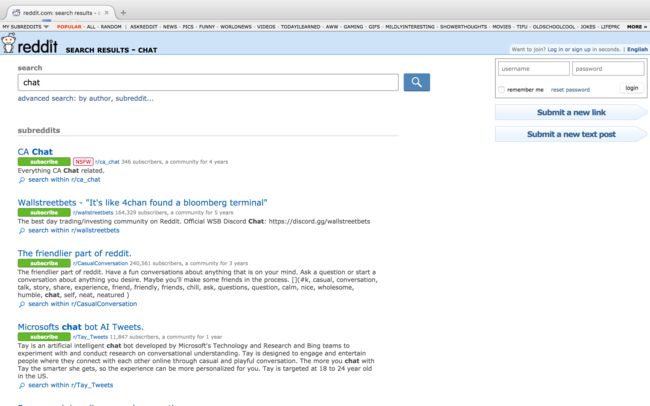
对比第一页的https://www.reddit.com/search?q=chat&type=sr&count=4&before=t5_2uul1
规律不是很明显,所以来看看第一页中的next按钮的html显示
view more:
next ›
xpath为
/html/body/div[5]/div[2]/div/footer/div/span/a
对比来看看第二页的next的xpath:
/html/body/div[5]/div[2]/div/footer/div/span/a[2]
为什么最后多了一个[2]是因为多了一个prev按钮,所以来看看
next ›
#下面是第一页的
next ›
找到共同点为都有rel="nofollow next",所以获取方式可以通过把第一页当作特殊情况或者通过这个共同点来获取。
如果采取第一种方案:
next_page = selector.xpath('/html/body/div[5]/div[2]/div/footer/div/span/a[2]/@href').extract()
如果采取第二种方案:
next_page = selector.xpath('/html/body/div[5]/div[2]/div/footer/div/span/a[@rel="nofollow next"]/@href').extract()
3. 获取板块里面的每个发言页面
看看第一个板块chat板块的结构
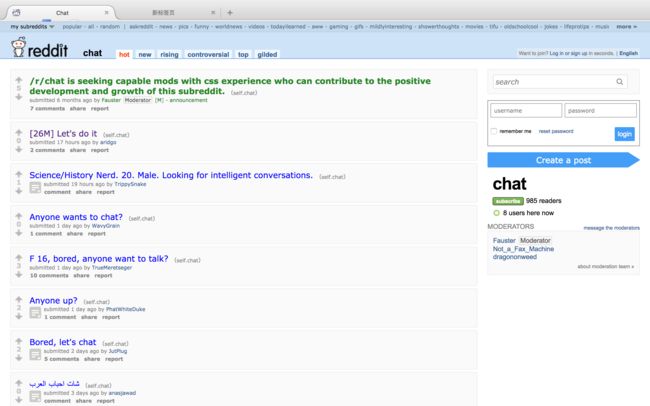
# 第一个发言的xpath
/html/body/div[5]/div/div[1]/div[2]/div/p[1]/a
链接到的网站为:
https://www.reddit.com/r/chat/comments/5q77js/rchat_is_seeking_capable_mods_with_css_experience/
# 第二个发言的xpath
/html/body/div[5]/div/div[3]/div[2]/div/p[1]/a
第一个发言在html中的显示:
第二个发言在html中的显示:
共同点就是data-event-action="title"
所以获取方式为:
talks_page = selector.xpath('/html/body/div[5]//div[@data-event-action="title"]/@href').extract()
因为reddit不同板块的结构可能不同,所以的话再看一个板块,第二个板块的第一个发言的xpath为
/html/body/div[5]/div/div[1]/div[2]/div[1]/p[1]/a
可见满足我们的提取方式。
4. 获取板块里面的下一页
/html/body/div[5]/div/div[53]/span/span/a
# html中显示
next ›
# 第二页的next按钮
/html/body/div[5]/div/div[51]/span/span[3]/a
获取方式为:
next_page = selector.xpath('/html/body/div[5]/div//a[@rel="nofollow next"]/@href').extract()
5. 获取每一个发言页面的对话
先看看发言页面长什么样子
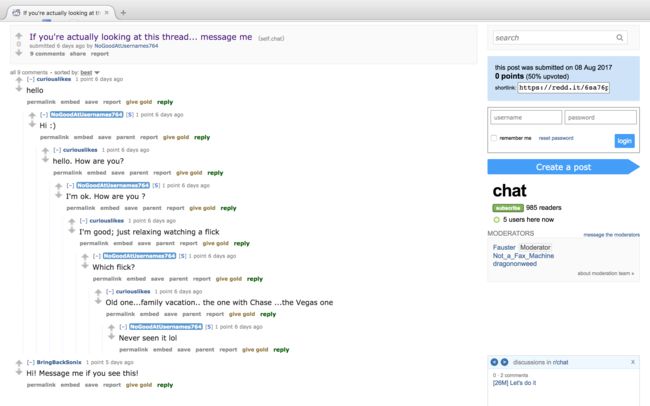
最外圈的xpath为:/html/body/div[5]/div[2]/div[3]
第一个人的评论然后往下依次为:
对应图中的hello
/html/body/div[5]/div[2]/div[3]/+div[1]/+div[2]/form/div/div/p
对应图中的Hi :)
/html/body/div[5]/div[2]/div[3]/+div[1]/+div[3]/div/div[1]/+div[2]/form/div/div/p
对应图中的hello. How are you?
/html/body/div[5]/div[2]/div[3]/+div[1]/+div[3]/div/div[1]/+div[3]/div/div[1]/+div[2]/form/div/div/p
然后下面的第二个人发起的评论为
/html/body/div[5]/div[2]/div[3]/+div[3]/+div[2]/form/div/div/p
可以按照构造规律从外往里提取文本,但是这样比较麻烦,来看看在html中的显示:
hello
发现class="usertext-body may-blank-within md-container "这个都是存在的,算是一个共同点。
然后在html中观察每一个人发起的评论区域的html显示中都会有data-type="comment"。
所以便有一种提取方法:
-
提取每个人发起的对话区域:
comment_zone = selector.xpath('//div[@data-type="comment"]') -
用循环提取每一句对话
for conversation in comment_zone: talk = conversation.xpath('//div[@class="usertext-body may-blank-within md-container "]/div/p/text()').extract()
但是在每一轮对话中,就像下面这种,有针对一句话的两个人的不同回答,那怎么办?
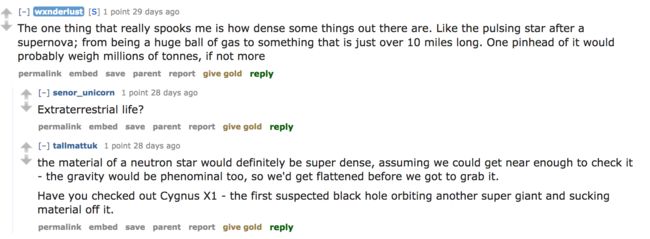
这时候可以给scrappy定义的item多加一点属性,除了对话本身,还得加一点id之类的标示,每个人发起的回复有一个id,然后后期再处理。
也可以在写py文件时就处理,为后面省一点时,处理逻辑可以是递归。
不过这里因为数量也够大了,所以这种情况就直接忽略或者跳过就好了,省去一些麻烦。
编写爬虫代码
框架使用scrapy
略
开始爬取
略
注:上面的代码中可能有细节错误,主要提供一个爬虫的框架和思想介绍,不关注细节