github
doc
librosa paper
博客
名词解释
| 名称 | 含义 |
|---|---|
| sr(sample_rate) | 采样率,表示一秒采样多少个样本点 |
| hop_length | 步幅;帧移对应卷积中的stride;连续帧分割长度 |
| overlapping | 连续两帧的重叠部分 |
| n_fft | 窗口大小;n_fft = hop_length+overlapping |
| spectrum | 光谱,频谱 |
| spectrogram: | 光谱图;声谱图 |
| Chromagram | 色谱图 |
| Scaleogram | |
| magnitude spectrogram | |
| amplitude | 振幅 |
| logarithmic amplitude-frequency | 对数振幅频谱图 |
| mono | 单声道 |
| stereo | 立体声 |
| constant-Q transform (cqt) | |
| pitch | 音高 |
| timbral | 音色 |
cqt特征捕获音高,mfcc捕获音色
音频处理的流程
- 音频分帧
通过使用窗口函数将长短不一的音频分割成大小相同的音频片段。(默认采样率22050Hz)
一般有两种描述方式:
方式一:(帧描述方式)使用2048((20481000ms)/22050=93ms)个采样点,前后两个窗的重叠5123采样点。
方式二:(时间描述方式)使用 93ms 的帧长、23ms 的帧移(hop_length),以及周期性的 Hann 窗口对语音进行分帧。
例如:下面的图通过一个滑动窗口将一个音频分割成6个等成的音频片段。
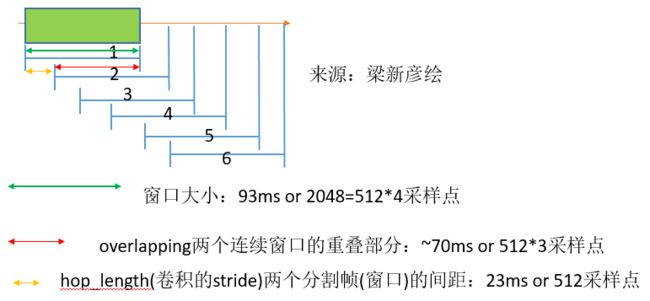 image.png
image.png
#这是一个窗口大小为window_size,连续窗口的重叠部分为window_size/2
def windows(audio, window_size):
start = 0
while start < len(audio):
#len(audio)是一个音频文件的总样本点数。
yield start, start + window_size #取出长度为window_size的样本点下标索引
start += (window_size / 2) #计算下一个分割片段的起始位置
- 计算每一帧mel声谱图。
signal = audio[0,2048] #(audio[0,2048] 表示图中的分割的1片段
#下面一行计算分割片段audio[0,2048]的64阶mel谱
#sr表示采样率,表示一秒采样多少个样本点。
#n_fft表示短时傅里叶变化用到的连续的样本点个数
#hop_length:连续两个傅里叶变化的重叠样本点个数
melspec = librosa.feature.melspectrogram(signal, sr=22050,
n_fft=2048,
hop_length=512,
n_mels = 64)
logspec = librosa.logamplitude(melspec)#计算log mel
输出:
#本代码计算将一个原始音频文件分割成等大小的片段,
#然后计算每一个片段的og mel_sepctrogram.
for (start,end) in windows(audio,window_size):
#(1)此处是为了是将大小不一样的音频文件用大小window_size,
#stride=window_size/2的窗口,分割为等大小的时间片段。
#(2)计算每一个分割片段的log mel_sepctrogram.
if(end<= len(audio)): #最后不够一个窗口的样本点舍去
signal = audio[start:end] #分割的音频帧(图中的1,2,3,4,5,6)
melspec = librosa.feature.melspectrogram(signal, n_mels = 64) #计算每个分割片段的mel谱
logspec = librosa.logamplitude(melspec)#计算log mel 谱
参考教材:
- Urban Sound Classification Part 1 Part 2
- Karol J. Piczak github
- 如何使用TensorFlow实现音频分类任务 教材
LibROSA
LibROSA is a python package for music and audio analysis. It provides the building blocks necessary to create music information retrieval systems.
这个过程对应计算信号s(t)的
short-time Fourier transform magnitude平方。窗口大小w. spectrogram(t,w) = |STFT(t,w)|**2。可以理解为谱是傅里叶变换的平方。
- 计算log mel-spectrogram
y 与 S只需提供一个。y是读入的音频文件,S是音频的谱
n_fft:STFT window size
hop_length : STFT hop length
melspec = melspectrogram(y=None, sr=22050, S=None, n_fft=2048, hop_length=512, power=2.0, **kwargs):
logspec = librosa.logamplitude(melspec)
def windows(data, window_size):
start = 0
while start < len(data):
yield start, start + window_size
start += (window_size / 2)
def extract_features(parent_dir,sub_dirs,file_ext="*.wav",bands = 60, frames = 41):
window_size = 512 * (frames - 1)
log_specgrams = []
labels = []
for l, sub_dir in enumerate(sub_dirs):
for fn in glob.glob(os.path.join(parent_dir, sub_dir, file_ext)):
sound_clip,s = librosa.load(fn)
label = fn.split('/')[2].split('-')[1]
for (start,end) in windows(sound_clip,window_size):
#(1)此处是为了是将大小不一样的音频文件用大小window_size,
#stride=window_size/2的窗口,分割为等大小的时间片段。
#(2)计算每一个分割片段的log mel_sepctrogram.
#或者,先分别计算大小不一的音频的log mel_spectrogram,在通过固定的窗口,
#切割等大小的频谱图。
if(len(sound_clip[start:end]) == window_size):
signal = sound_clip[start:end]
melspec = librosa.feature.melspectrogram(signal, n_mels = bands)
logspec = librosa.logamplitude(melspec)
logspec = logspec.T.flatten()[:, np.newaxis].T
log_specgrams.append(logspec)
labels.append(label)