参考网站:http://zh.gluon.ai/
从0开始的线性回归
虽然强大的深度学习框架可以减少很多重复性工作,但如果你过于依赖它提供的便利抽象,那么你可能不会很容易的理解到底深度学习是如何工作的。所以我们的第一个教程是如何只利用ndarray和autograd来实现一个线性回归的训练。
线性回归
给定一个数据点集合X和对应的目标值y,线性模型的目标是找一根线,其由向量w和位移b组成,来最好的近似每个样本X[i]和y[i]。用数学符号来表示就是我们将学w和b来预测,
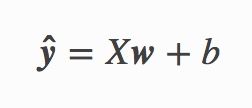
并最小化所有数据点上的平方误差
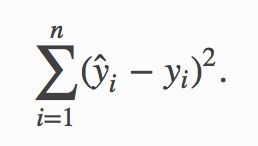
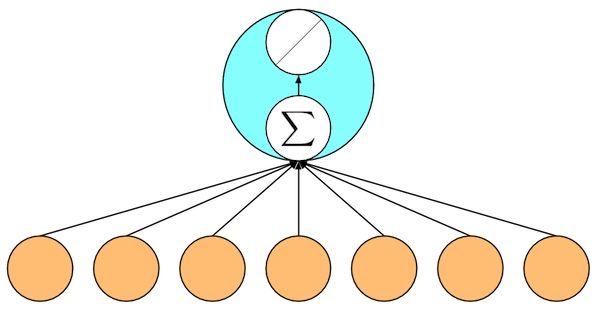
你可能会对我们把古老的线性回归作为深度学习的一个样例表示很奇怪。实际上线性模型是最简单但也可能是最有用的神经网络。一个神经网络就是一个由节点(神经元)和有向边组成的集合。我们一般把一些节点组成层,每一层使用下一层的节点作为输入,并输出给上面层使用。为了计算一个节点值,我们将输入节点值做加权和,然后再加上一个激活函数。对于线性回归而言,它是一个两层神经网络,其中第一层是(下图橙色点)输入,每个节点对应输入数据点的一个维度,第二层是单输出节点(下图绿色点),它使用身份函数(f(x)=x)作为激活函数。
创建数据集
这里我们使用一个人工数据集来把事情弄简单些,因为这样我们将知道真实的模型是什么样的。具体来首我们使用如下方法来生成数据
y[i] = 2 * X[i][0] - 3.4 * X[i][1] + 4.2 + noise
这里噪音服从均值0和方差为0.1的正态分布。
from mxnet import ndarray as nd
from mxnet import autograd
num_inputs = 2
num_examples = 1000
true_w = [2, 3.4]
true_b = 4.2
X = nd.random_normal(shape=(num_examples, num_inputs))
y = true_w[0] * X[:, 0] - true_w[1] * X[:, 1] + true_b
y += .01 * nd.random_normal(shape=y.shape)
注意到X的每一行是一个长度为2的向量,而y的每一行是一个长度为1的向量(标量)。
print(X[0], y[0])
[ 2.21220636 1.16307867]
[ 4.6620779]
数据读取
当我们开始训练神经网络的时候,我们需要不断的读取数据块。这里我们定义一个函数它每次返回batch_size个随机的样本和对应的目标。我们通过python的yield来构造一个迭代器。
import random
batch_size = 10
def data_iter():
# 产生一个随机索引
idx = list(range(num_examples))
random.shuffle(idx)
for i in range(0, num_examples, batch_size):
j = nd.array(idx[i:min(i+batch_size,num_examples)])
yield nd.take(X, j), nd.take(y, j)
下面代码读取第一个随机数据块
for data, label in data_iter():
print(data, label)
break
[[ 0.24021588 -0.53960389]
[ 0.01106104 0.36940244]
[-0.21115878 -0.64478874]
[-0.73600543 1.56812 ]
[-0.73192883 -0.50927299]
[-0.48362762 0.27216455]
[-0.60159451 0.29670078]
[-0.88538933 0.09512273]
[ 0.19420861 -0.91510016]
[ 0.00955429 -0.35396427]]
[ 6.49492311 2.97613215 5.98414278 -2.6195066 4.46368217 2.31007123
1.97259736 2.08594513 7.70643806 5.41053724]
初始化模型参数
下面我们随机初始化模型参数
w = nd.random_normal(shape=(num_inputs, 1))
b = nd.zeros((1,))
params = [w, b]
之后训练时我们需要对这些参数求导来更新它们的值,所以我们需要创建它们的梯度。
for param in params:
param.attach_grad()
定义模型
线性模型就是将输入和模型做乘法再加上偏移:
def net(X):
return nd.dot(X, w) + b
损失函数
我们使用常见的平方误差来衡量预测的目标和真实目标之间的差距。
def square_loss(yhat, y):
# 注意这里我们把y变形成yhat的形状来避免自动广播
return (yhat - y.reshape(yhat.shape)) ** 2
优化
虽然线性回归有显试解,但绝大部分模型并没有。所以我们这里通过随机梯度下降来求解。每一步,我们将模型参数沿着梯度的反方向走特定距离,这个距离一般叫学习率。(我们会之后一直使用这个函数,我们将其保存在utils.py。)
def SGD(params, lr):
for param in params:
param[:] = param - lr * param.grad
训练
现在我们可以开始训练了。训练通常需要迭代数据数次,一次迭代里,我们每次随机读取固定数个数据点,计算梯度并更新模型参数。
epochs = 5
learning_rate = .001
for e in range(epochs):
total_loss = 0
for data, label in data_iter():
with autograd.record():
output = net(data)
loss = square_loss(output, label)
loss.backward()
SGD(params, learning_rate)
total_loss += nd.sum(loss).asscalar()
print("Epoch %d, average loss: %f" % (e, total_loss/num_examples))
Epoch 0, average loss: 7.941256
Epoch 1, average loss: 0.100285
Epoch 2, average loss: 0.001379
Epoch 3, average loss: 0.000120
Epoch 4, average loss: 0.000103
训练完成后我们可以比较学到的参数和真实参数
true_w, w
([2, 3.4],
[[ 1.99963176]
[-3.40014362]])
true_b, b
(4.2,
[ 4.19964504])
结论
我们现在看到仅仅使用NDArray和autograd我们可以很容易的实现一个模型。有兴趣的话,可以尝试用不同的学习率查看误差下降速度(收敛率)。
使用Gluon的线性回归
前面我们仅仅使用了ndarray和autograd来实现线性回归,现在我们仍然实现同样的模型,但是使用高层抽象包gluon。
创建数据集
我们生成同样的数据集
from mxnet import ndarray as nd
from mxnet import autograd
from mxnet import gluon
num_inputs = 2
num_examples = 1000
true_w = [2, 3.4]
true_b = 4.2
X = nd.random_normal(shape=(num_examples, num_inputs))
y = true_w[0] * X[:, 0] - true_w[1] * X[:, 1] + true_b
y += .01 * nd.random_normal(shape=y.shape)
数据读取
但这里使用data模块来读取数据。
batch_size = 10
dataset = gluon.data.ArrayDataset(X, y)
data_iter = gluon.data.DataLoader(dataset, batch_size, shuffle=True)
读取跟前面一致:
for data, label in data_iter:
print(data, label)
break
[[ 1.66524243 -0.790555 ]
[ 2.73936391 0.73395604]
[-0.82552391 0.60547197]
[ 0.18361944 -1.8479687 ]
[-1.11130977 -0.30177692]
[-0.23753072 -0.68533319]
[ 0.02715491 -0.26509324]
[-1.07131875 0.9324615 ]
[ 0.6325348 -0.19508815]
[ 0.82890278 -0.25843123]]
[ 10.22668362 7.193501 0.48110276 10.85089588 3.0170579
6.05681705 5.15688562 -1.11165142 6.12516403 6.74039841]
定义模型
当我们手写模型的时候,我们需要先声明模型参数,然后再使用它们来构建模型。但gluon提供大量提前定制好的层,使得我们只需要主要关注使用哪些层来构建模型。例如线性模型就是使用的对应Dense层。
虽然我们之后会介绍如何构造任意结构的神经网络,构建模型最简单的办法是利用Sequential来所有层串起来。首先我们定义一个空的模型:
net = gluon.nn.Sequential()
然后我们加入一个Dense层,它唯一必须要定义的参数就是输出节点的个数,在线性模型里面是1.
net.add(gluon.nn.Dense(1))
(注意这里我们并没有定义说这个层的输入节点是多少,这个在之后真正给数据的时候系统会自动赋值。我们之后会详细介绍这个特性是如何工作的。)
初始化模型参数
在使用net前我们必须要初始化模型权重,这里我们使用默认随机初始化方法(之后我们会介绍更多的初始化方法)。
net.initialize()
损失函数
gluon提供了平方误差函数:
square_loss = gluon.loss.L2Loss()
优化
同样我们无需手动实现随机梯度下降,我们可以用创建一个Trainer的实例,并且将模型参数传递给它就行。
trainer = gluon.Trainer(
net.collect_params(), 'sgd', {'learning_rate': 0.1})
训练
这里的训练跟前面没有太多区别,唯一的就是我们不再是调用SGD,而是trainer.step来更新模型。
epochs = 5
batch_size = 10
learning_rate = .01
for e in range(epochs):
total_loss = 0
for data, label in data_iter:
with autograd.record():
output = net(data)
loss = square_loss(output, label)
loss.backward()
trainer.step(batch_size)
total_loss += nd.sum(loss).asscalar()
print("Epoch %d, average loss: %f" % (e, total_loss/num_examples))
Epoch 0, average loss: 0.905177
Epoch 1, average loss: 0.000052
Epoch 2, average loss: 0.000052
Epoch 3, average loss: 0.000052
Epoch 4, average loss: 0.000052
比较学到的和真实模型。我们先从net拿到需要的层,然后访问其权重和位移。
dense = net[0]
true_w, dense.weight.data()
([2, 3.4],
[[ 2.00046849 -3.40106511]])
true_b, dense.bias.data()
(4.2,
[ 4.20045042])
结论
可以看到gluon可以帮助我们更快更干净的实现模型。在训练的时候,为什么我们用了比前面要大10倍的学习率呢?运行 help(trainer.step)可以知道,学习率的数值一般设置为1/batch_size。我们如何能拿到weight的梯度呢?运行 help(dense.weight)可知,dense.weight.grad()能查看梯度。善用help命令,能让我们更好的理解我们的程序。
下一Part我们将讨论如何解决逻辑回归的问题。