写在前面:我是一条鱼,记忆只有7秒。
1.脚本处理要点
- 录制设置
- 乱码处理
- 帮助文档使用说明
- 参数化
- 关联
- 关联数组
- 事务
- 检查点
- 思考时间
- 集合点
2.录制设置
2.1创建脚本时的协议选择
方式一:已知被测系统采用的协议
如果已知被测系统的采用的协议,在新建脚本时,可以选择对应的协议。
路径:File->New Script and Solution 或者File->add->New Script.

方式二:未知被测系统的协议
如果不知道被测系统的协议,可以点击上图左小角的protocol advisor进行协议分析。
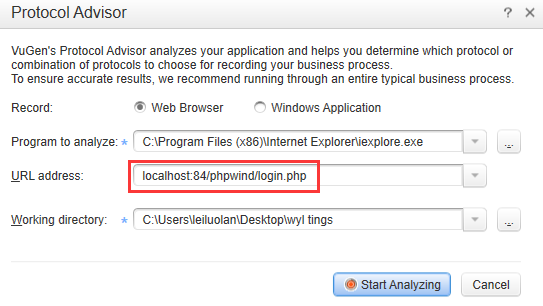
被测系统分为B/S系统和C/S系统,具体信息可以打开这个界面后按“F1”查看帮助文档。
特别注意:当选择web browser后,url address的地址中不要加【http://】。
如果loadrunner自带的协议分析工具不好用(比如我的lr12+win10 64,就根本打不开ie),那么就搜索其他协议分析工具进行分析。
TIPS:最快的方式是,问开发!!!他要不知道,就拖出去##算了。
2.2脚本录制设置
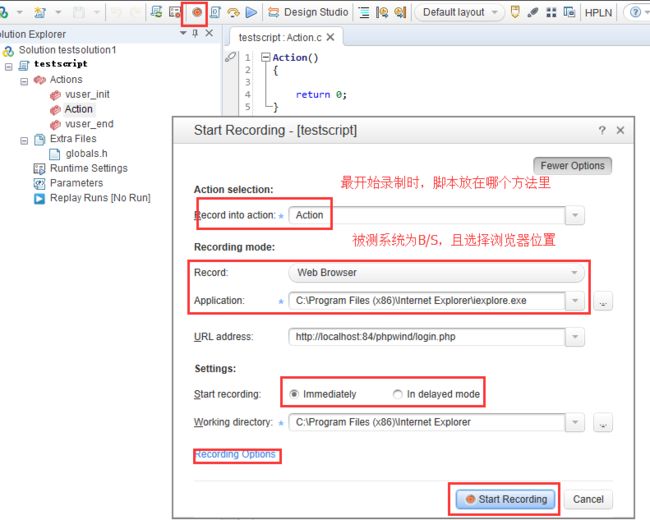
1.录制选项
Immediately和In delayed mode的区别在于:
Immediately:点击录制后就开始录制脚本;
In delayed mode:点击录制后,会先在浏览器中打开url地址,再次点击开始录制,才会录制操作脚本。
2. Recoding Options
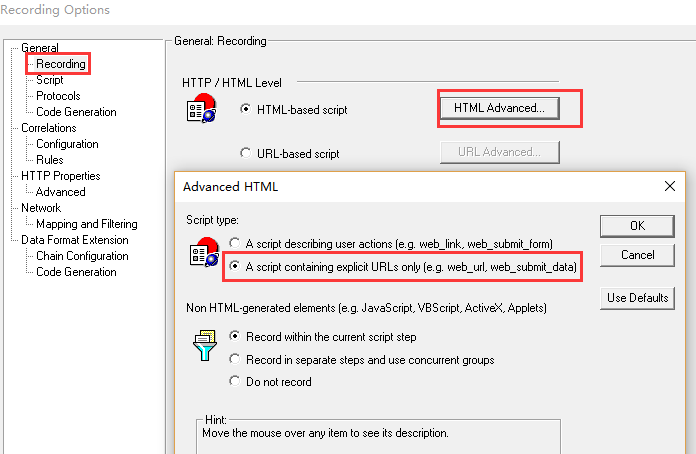
选择recording options对录制过程中的一些选项进行设置。
设置一:选择录制的函数为web_url()[相当于get请求]和web_submit_data()[相当于post请求]。
为什么要这么选择?
&&:因为这2个函数是不依赖于上下文的,有利于脚本的处理。
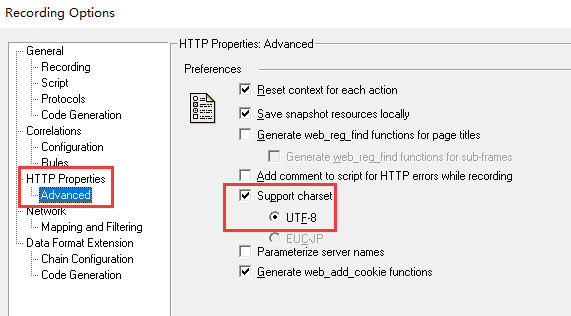
设置二:编码设置,预防录制乱码。
在没有进行设置时,录制时的编码是默认与操作系统一致的。通常操作系统为GB系列的编码。当默认的录制编码与被测系统的编码不一致时,录制后的脚本中,就会存在乱码。
Q:怎么查看被测系统的编码?
&&:打开被测系统,在浏览器中右键查看源文件:

在录制选项中,设置编码,如图:
2.3录制过程中的操作
录制过程中,当需要对脚本进行新建方法、添加事务、添加集合点、添加检查点等操作时,可以直接在录制界面,暂停后进行操作:
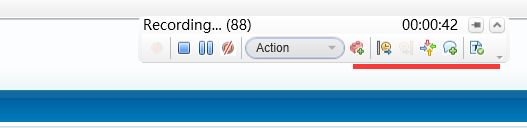
要了解详细的操作过程,可以将鼠标放在这个操作栏上,然后按“F1”查看帮助文档。
3.运行时设置
脚本录制完成后,可以对脚本进行编译和运行,查看脚本运行的结果是否符合预期。
3.1 runtime settings
路径:replay->runtime settings
快捷键:F4
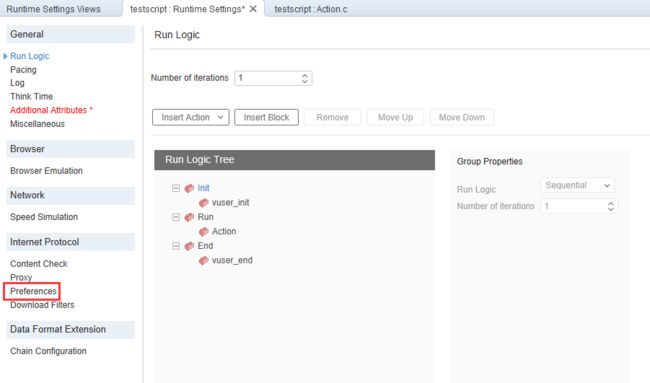
3.2 runtime settings中可以设置的内容
【将鼠标放在对应的选项上,会出现该选项具体的说明】
runtime settings中的设置进行保存后,可以作用于vugen、controller、性能中心等。
在该项设置中,可以设置如下内容:
- run logic:迭代次数、运行顺序、每个action的运行次数等。可以用insert block进行分块,设定每个模块的运行比例,可以实现30%的用户运行A模块、70%的用户运行B模块;
- pacing:可以设置每次迭代的步进时间。设置有效的步进时间有利于更加真实地模拟用户使用场景;
- think time:思考时间。可以设置运行时是否忽略思考时间(建议不要忽略)、思考时间的长短、还可以设置随机思考时间。
- log:可以设置日志的输出级别。如果在调试运行中,不想看到输出全部日志数据在控制台,可以设置出错时才输出日志。同时,可以设置脚本中用到的参数【parameter substitution】,在运行时,可以在控制台看到每次迭代用到的数据变化。
- additional attribute:目前不知道这个的使用场景。感觉可以使用这个属性在脚本中使用对应的值,比如用函数:lr_get_attrib_string()去获取参数名对应值,在脚本中进行应用,类似于jmeter中用户定义的变量。可以用于设定全局变量。具体用法可以参考loadrunner中lr_get_attrib_string()给出的示例进行理解。
- miscellaneous:其他。这部分可以设置错误处理、每个用户使用进程或线程、事务的统计方式(直接影响响应时间等的统计)。
- browser emulation:可以设置请求头中的信息,如:浏览器信息、缓存机制等。
- Speed Simulation:带宽模拟。默认为最大带宽,可以根据被测系统用户使用的真实场景进行带宽的设定。
- content check:不知道这个的使用场景。查资料说明这个功能将会在脚本运行时自动帮你在页面上检查你的预期信息,听起来类似于检查点。具体使用方式为:添加应用、规则、检查文本等信息,不过还是不知道怎么用。
- proxy:代理。设置代理信息。
- preferences:这一项里能设置的内容比较多。主要包括:编码、http、ip、日志长度等相关信息,具体可以根据需要详细查看。
4.参数化操作
为什么要进行参数化?当然是为了模拟用户真实场景咯。
哪些数据需要进行参数化?在每次操作需要进行变化的数据。
哪些数据能够进行参数化?已经存储在数据库且不会进行变化的数据。
4.1参数化类型
- 用户名、密码:已经存在数据库的,需要预先获取存在对应的文件中进行获取;
- 日期
- 随机数
- 表格
- xml格式
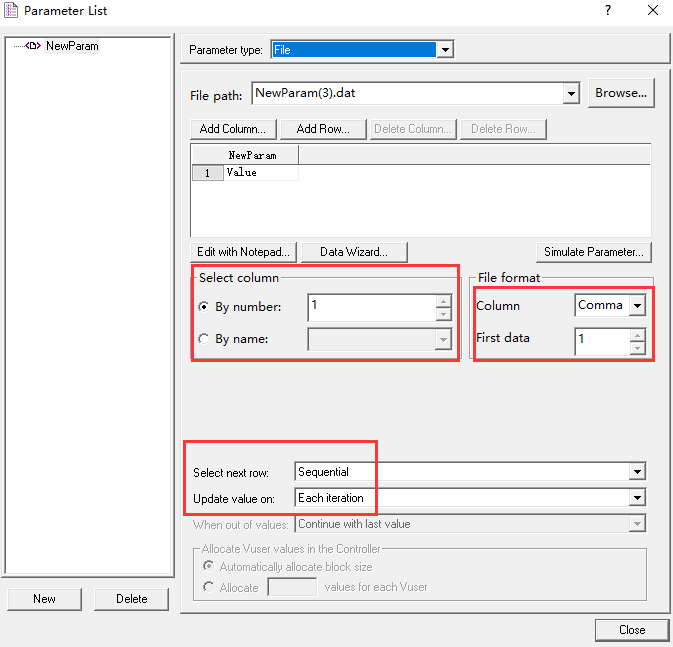
4.2参数化运行顺序
- 顺序
- 随机
- 唯一
- 参数联动(类似于表格格式了)
4.3参数化引用数据格式
{parameter}
调试时,可以采用lr_output_message(“{parameter}")输出参数。
5.关联
为什么要用关联?当请求中用到的数据来源于之前请求的响应数据时。
5.1关联的方式
方式一:录制时可以设置关联规则
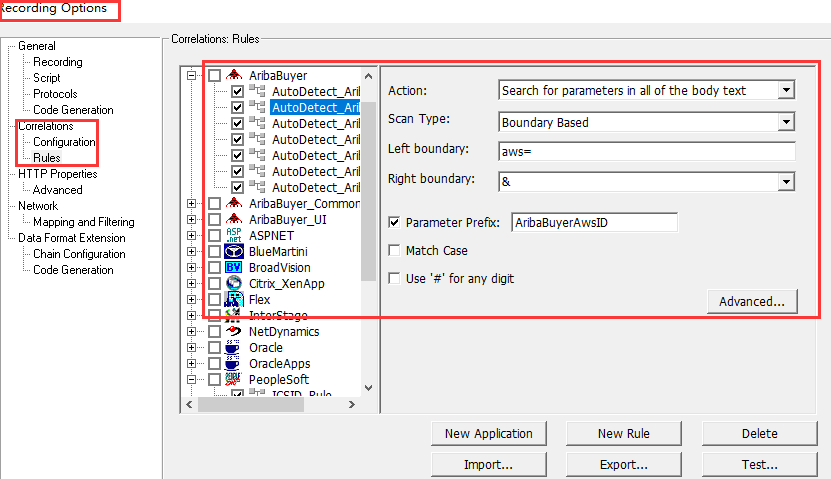
方式二:录制完成后,可以获取需要关联的数据
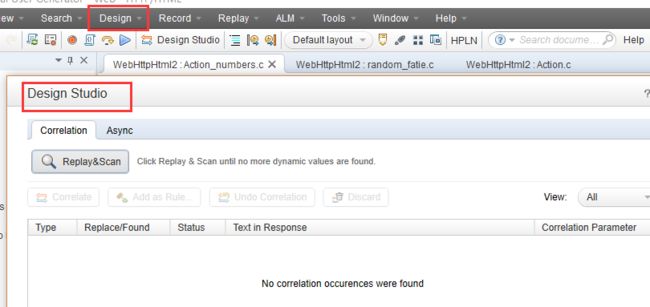
方式三:手动关联
手动查找需要关联的数据。
5.2关联函数
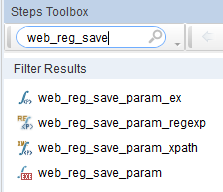
这4个函数的使用方法可以见帮助文档。
关联函数需要放在获取关联数据的请求之前。
关联数组:
在函数中增加ord=,示例如下:
web_reg_save_param("forum",
"LB=href=\"thread.php?fid=",
"RB=\" target=\"_blank\">",
"Ord=all",
LAST);
forum是一个数组,在引用的时候应该怎么操作呢?
&&:用loadrunner的自带函数获取数组的随机值:lr_save_string(lr_paramarr_random("forum"), "forumid");
6.事务
- 统计一个请求或者一批请求的响应时间;
- 统计事务的成功率;
- 在要统计的请求前后添加事务的开始函数和结束函数:lr_start_transaction()
7.检查点
检查点用于判断事务是否成功。因为事务自带的判断是通过判断响应的状态码,只有4XX、5XX才会被判断为失败,这样不一定符合业务逻辑,因此需要用到检查点。
检查点函数:
web_reg_find(),该函数放在要检查的请求之前。
检查点的用途:
- 判断事务是否成功:
- 判断当前页面返回的值为A还是B,如果为A则执行A场景、为B则执行B场景,可用于脚本开发的场景设计;
- 检查点的示例,可以查看该函数的帮助文档,非常清晰明确。
8.思考时间
推荐设置随机思考时间,并且不要太长,可以在runtime settings中进行设置。
9.集合点
9.1集合点的使用场景
适应场景:并发测试,属于性能测试的一种。
负载测试、压力测试、容量测试
- 并发测试:主要关注大用户量并发时,所有用户都在发同一种请求。
- 压力测试:并发测试可以看做压力测试的一个子集,当压力测试时,指标出现异常却不能分析出是哪个模块出现异常时,可以采用并发测试对某个模块进行测试,去定位问题。压力测试是为了让系统处于极限,在这类测试中可以忽略思考时间。
- 负载测试:评估性能指标时采用,比如:100个用户时,系统是什么样的状态,1000个用户时,系统是什么样的状态。因此,这类测试最需要接近于用户的真实使用测试。
- 稳定性测试:长时间标准用户数对系统进行测试。比如:采用最佳用户数对系统进行长时间进行测试。
- 最佳用户数的考量,需要系统的各项指标进行考量评估最佳用户数;
- 最大用户数:系统的某一项性能指标出现极限,则在当前状态下为最大用户数,该数据由负载测试获取。
- 容量测试:模拟系统长时间运行后的性能状态,比如:关系型数据库。
9.2集合点的设置
在脚本中插入了集合点后,可以在controller中进行设置。
路径为:scenario->rendezvous.可以启用或者禁用,启用可以设置集合点策略。
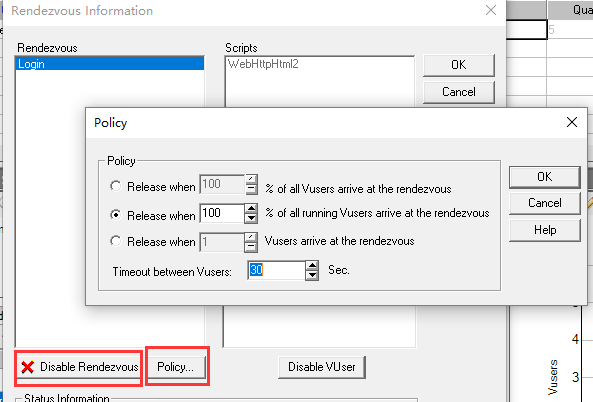
在脚本中,应该先有集合点,再有事务,否则集合点处的等待时间也会统计到事务中,不符合时间场景。因此顺序为:集合点、事务起点、事务、事务终点。另一方面,当设置了集合点后,其实就不太符合用户真实场景了,因此在执行有集合点的场景时,应该主要关注有集合点的这个请求是否会给服务器造成异常或者瓶颈。
写在后面:忘得太快,下一篇要给自己备注一个采用了以上场景的脚本。