生信人的20个R语言习题
1.安装一些R包:
数据包: ALL, CLL, pasilla, airway
软件包:limma,DESeq2,clusterProfiler
工具包:reshape2
绘图包:ggplot2
# 设置镜像
options(repos<- c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/") )
source("https://bioconductor.org/biocLite.R")
options("BioC_mirror"<- "https://mirrors.ustc.edu.cn/bioc/")
# 安装必须的包
install.packages("RSQLite")
#哎呀,出现错误,试一下这个
install.packages('RSQLite', dependencies=TRUE, repos='http://cran.rstudio.com/')
library(DESeq2)
library(reshape2)
2.了解ExpressionSet对象,比如CLL包里面就有data(sCLLex) ,找到它包含的元素,提取其表达矩阵(使用exprs函数),查看其大小
参考:http://www.bio-info-trainee.com/bioconductor_China/software/limma.html
参考:https://github.com/bioconductor-china/basic/blob/master/ExpressionSet.md
# 以下在小作业中级均提到过
# 参考 https://www.jianshu.com/p/e15ee2cd3174
library(CLL)
data(sCLLex)
sCLLex
exprSet <- exprs(sCLLex)
dim(exprSet)
##sCLLex是依赖于CLL这个package的一个对象
samples=sampleNames(sCLLex)
pdata=pData(sCLLex)
# 生成分组信息
group_list=as.character(pdata[,2])
dim(exprSet)
exprSet[1:5,1:5]
3.了解 str,head,help函数,作用于 第二步提取到的表达矩阵
# 看一下exprSet的结构
str(exprSet)
# 显示前六行(默认)
head(exprSet)
# 如何想看几行就看几行呢 10为例
head(exprSet,n=10)
# 万物皆可"help"&"?"
help()
4.安装并了解 hgu95av2.db 包,看看 ls("package:hgu95av2.db") 后 显示的那些变量
# BiocManager::install('hgu95av2.db')
library(hgu95av2.db)
# 如前
ls("package:hgu95av2.db")
5.理解 head(toTable(hgu95av2SYMBOL)) 的用法,找到 TP53 基因对应的探针ID
ids <- toTable(hgu95av2SYMBOL)
head(ids)
# 找到 TP53 基因对应的探针ID,也可直接去数据框搜
ID <- ids[ids$symbol%in%"TP53",][,1]
# 保存下数据,方便下次继续,避免从头开始。
save(ids,exprSet,pdata,file = 'input.Rdata')
6.理解探针与基因的对应关系,总共多少个基因,基因最多对应多少个探针,是哪些基因,是不是因为这些基因很长,所以在其上面设计多个探针呢?
# dim一下,发现11460行,2列
dim(ids)
# unique可见,总共8585个基因
length(unique(ids$symbol))
# 给多个基因排序,显示最靠后的6个,同样可以n=10
tail(sort(table(ids$symbol)))
# 查看各出现频数的分布,其中6555个基因只出现了一次
table(sort(table(ids$symbol)))
# 可视化
plot(table(sort(table(ids$symbol))))
7.第二步提取到的表达矩阵是12625个探针在22个样本的表达量矩阵,找到那些不在 hgu95av2.db 包收录的对应着SYMBOL的探针。
提示:有1165个探针是没有对应基因名字的。
# 查看多少%in%,多少!%in%,即分布。可知,11460个TRUE,1165个FALSE
table(rownames(exprSet) %in% ids$probe_id)
dim(exprSet)
8.过滤表达矩阵,删除那1165个没有对应基因名字的探针。
# 筛选
exprSet=exprSet[rownames(exprSet) %in% ids$probe_id,]
# 11460行
dim(exprSet)
9.整合表达矩阵,多个探针对应一个基因的情况下,只保留在所有样本里面平均表达量最大的那个探针。
提示,理解 tapply,by,aggregate,split 函数 , 首先对每个基因找到最大表达量的探针。
然后根据得到探针去过滤原始表达矩阵
ids=ids[match(rownames(exprSet),ids$probe_id),]
head(ids)
exprSet[1:5,1:5]
if(F){
# 定义最大平均表达量的...
tmp = by(exprSet,ids$symbol,
function(x) rownames(x)[which.max(rowMeans(x))] )
probes = as.character(tmp)
dim(exprSet)
#筛选表达矩阵
exprSet=exprSet[rownames(exprSet) %in% probes ,]
# 看下筛选之后行情况,8585
dim(exprSet)
# 表达矩阵探针换为基因名
rownames(exprSet)=ids[match(rownames(exprSet),ids$probe_id),2]
exprSet[1:5,1:5]
}
# 两者一样吗,FALSE
identical(ids$probe_id,rownames(exprSet))
# match一下,再鉴定一遍,TRUE
ids=ids[match(rownames(exprSet),ids$probe_id),]
identical(ids$probe_id,rownames(exprSet))
#新建dat
dat=exprSet
#ids新建median这一列,列名为median,同时对dat这个矩阵按行操作,取每一行的中位数,将结果给到median这一列的每一行
ids$median=apply(dat,1,median)
#对ids$symbol按照ids$median中位数从大到小排列的顺序排序,将对应的行赋值为一个新的ids(跟随改变)
ids=ids[order(ids$symbol,ids$median,decreasing = T),]
#将symbol这一列取取出重复项,'!'为否,即取出不重复的项,去除重复的gene ,保留每个基因最大表达量结果
ids=ids[!duplicated(ids$symbol),]
dim(ids)
#新的ids取出probe_id这一列,将dat按照取出的这一列中的每一行组成一个新的dat
dat=dat[ids$probe_id,]
#把ids的symbol这一列中的每一行给dat作为dat的行名
rownames(dat)=ids$symbol
#保留每个基因ID第一次出现的信息
dat[1:4,1:4]
dim(dat)
10.把过滤后的表达矩阵更改行名为基因的symbol,因为这个时候探针和基因是一对一关系了。见上
#把ids的symbol这一列中的每一行给dat作为dat的行名
rownames(dat)=ids$symbol
#保留每个基因ID第一次出现的信息
dat[1:4,1:4]
dim(dat)
11.对第10步得到的表达矩阵进行探索,先画第一个样本的所有基因的表达量的boxplot,hist,density , 然后画所有样本的 这些图
参考:http://bio-info-trainee.com/tmp/basic_visualization_for_expression_matrix.html
理解ggplot2的绘图语法,数据和图形元素的映射关系
# 管道回来
exprSet=dat
#
exprSet['GAPDH',]
boxplot(exprSet[,1])
boxplot(exprSet['GAPDH',])
exprSet['ACTB',]
# 用reshape2包画
library(reshape2)
# 整理分组矩阵
exprSet_L=melt(exprSet)
colnames(exprSet_L)=c('probe','sample','value')
# 获得分组信息
group_list=as.character(pdata[,2])
exprSet_L$group=rep(group_list,each=nrow(exprSet))
head(exprSet_L)
### ggplot2画图
library(ggplot2)
p=ggplot(exprSet_L,
aes(x=sample,y=value,fill=group))+geom_boxplot()
print(p)
p=ggplot(exprSet_L,aes(x=sample,y=value,fill=group))+geom_violin()
print(p)
p=ggplot(exprSet_L,aes(value,fill=group))+geom_histogram(bins = 200)+facet_wrap(~sample, nrow = 4)
print(p)
p=ggplot(exprSet_L,aes(value,col=group))+geom_density()+facet_wrap(~sample, nrow = 4)
print(p)
p=ggplot(exprSet_L,aes(value,col=group))+geom_density()
print(p)
p=ggplot(exprSet_L,aes(x=sample,y=value,fill=group))+geom_boxplot()
p=p+stat_summary(fun.y="mean",geom="point",shape=23,size=3,fill="red")
p=p+theme_set(theme_set(theme_bw(base_size=20)))
p=p+theme(text=element_text(face='bold'),axis.text.x=element_text(angle=30,hjust=1),axis.title=element_blank())
print(p)
放最后一张图吧
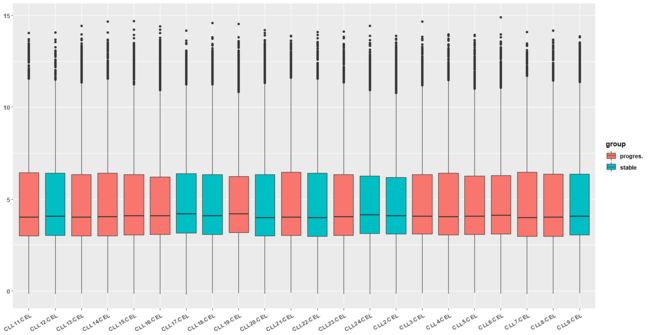
12.理解统计学指标mean,median,max,min,sd,var,mad并计算出每个基因在所有样本的这些统计学指标,最后按照mad值排序,取top 50 mad值的基因,得到列表。
# 异曲同工
g_mean <- tail(sort(apply(exprSet,1,mean)),50)
g_median <- tail(sort(apply(exprSet,1,median)),50)
g_max <- tail(sort(apply(exprSet,1,max)),50)
g_min <- tail(sort(apply(exprSet,1,min)),50)
g_sd <- tail(sort(apply(exprSet,1,sd)),50)
g_var <- tail(sort(apply(exprSet,1,var)),50)
g_mad <- tail(sort(apply(exprSet,1,mad)),50)
g_mad
names(g_mad)

13.根据第12步骤得到top 50 mad值的基因列表来取表达矩阵的子集,并且热图可视化子表达矩阵。试试看其它5种热图的包的不同效果。
# 热一下试试
library(pheatmap)
choose_gene=names(tail(sort(apply(exprSet,1,mad)),50))
choose_matrix=exprSet[choose_gene,]
choose_matrix=t(scale(t(choose_matrix)))
pheatmap(choose_matrix)
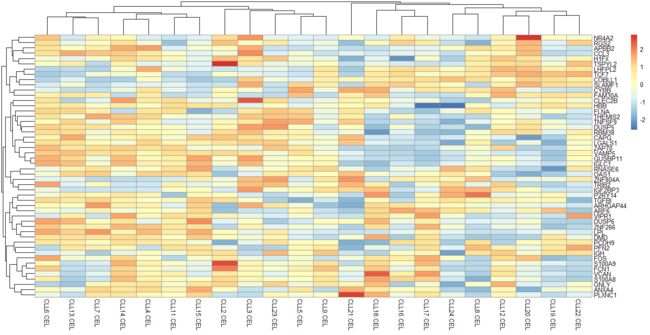
14.取不同统计学指标mean,median,max,mean,sd,var,mad的各top50基因列表,使用UpSetR包来看他们之间的overlap情况。
## UpSetR
# 看下说明书 https://cran.r-project.org/web/packages/UpSetR/README.html
library(UpSetR)
g_all <- unique(c(names(g_mean),names(g_median),names(g_max),names(g_min),
names(g_sd),names(g_var),names(g_mad) ))
dat=data.frame(g_all=g_all,
g_mean=ifelse(g_all %in% names(g_mean) ,1,0),
g_median=ifelse(g_all %in% names(g_median) ,1,0),
g_max=ifelse(g_all %in% names(g_max) ,1,0),
g_min=ifelse(g_all %in% names(g_min) ,1,0),
g_sd=ifelse(g_all %in% names(g_sd) ,1,0),
g_var=ifelse(g_all %in% names(g_var) ,1,0),
g_mad=ifelse(g_all %in% names(g_mad) ,1,0)
)
upset(dat,nsets = 7)

15.在第二步的基础上面提取CLL包里面的data(sCLLex) 数据对象的样本的表型数据。
pdata=pData(sCLLex)
group_list=as.character(pdata[,2])
group_list
dim(exprSet)
exprSet[1:5,1:5]
16.对所有样本的表达矩阵进行聚类并且绘图,然后添加样本的临床表型数据信息(更改样本名)
## hclust
# 更改表达矩阵列名
colnames(exprSet)=paste(group_list,1:22,sep='')
# 定义nodePar
nodePar <- list(lab.cex = 0.6, pch = c(NA, 19),
cex = 0.7, col = "blue")
# 聚类
hc=hclust(dist(t(exprSet)))
par(mar=c(5,5,5,10))
# 绘图
plot(as.dendrogram(hc), nodePar = nodePar, horiz = TRUE)
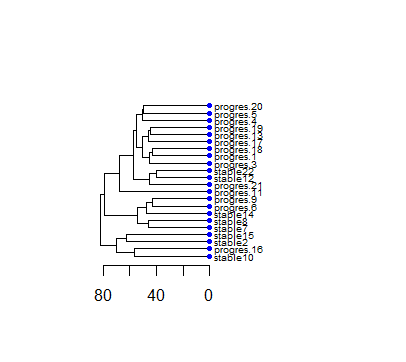
17.对所有样本的表达矩阵进行PCA分析并且绘图,同样要添加表型信息。
library(ggfortify)
# 互换行和列,dim一下
df=as.data.frame(t(exprSet))
dim(df)
# 不要view df,列太多,软件会崩掉;
df$group=group_list
autoplot(prcomp( df[,1:(ncol(df)-1)] ), data=df,colour = 'group')
#或者
#画主成分分析图需要加载这两个包
library("FactoMineR")
library("factoextra")
df=as.data.frame(t(exprSet))
dat.pca <- PCA(df, graph = FALSE)#现在dat最后一列是group_list,需要重新赋值给一个dat.pca,这个矩阵是不含有分组信息的
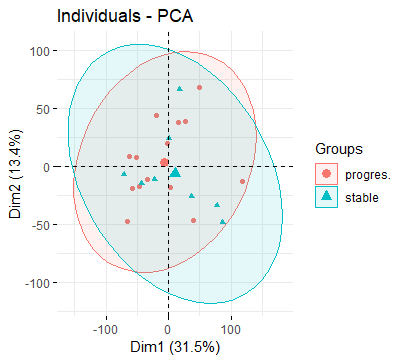
fviz_pca_ind(dat.pca,
geom.ind = "point", # show points only (nbut not "text")
col.ind = group_list, # color by groups
# palette = c("#00AFBB", "#E7B800"),
addEllipses = TRUE, # Concentration ellipses
legend.title = "Groups"
)
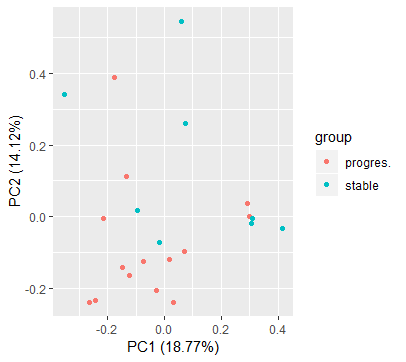
18.根据表达矩阵及样本分组信息进行批量T检验,得到检验结果表格
dat = exprSet
group_list=as.factor(group_list)
group1 = which(group_list == levels(group_list)[1])
group2 = which(group_list == levels(group_list)[2])
dat1 = dat[, group1]
dat2 = dat[, group2]
dat = cbind(dat1, dat2)
pvals = apply(exprSet, 1, function(x){
t.test(as.numeric(x)~group_list)$p.value
})
p.adj = p.adjust(pvals, method = "BH")
avg_1 = rowMeans(dat1)
avg_2 = rowMeans(dat2)
log2FC = avg_2-avg_1
DEG_t.test = cbind(avg_1, avg_2, log2FC, pvals, p.adj)
DEG_t.test=DEG_t.test[order(DEG_t.test[,4]),]
DEG_t.test=as.data.frame(DEG_t.test)
# 查看t检验结果表格,包含log2FC、pvals和p.adj等,通常认为t<0.05即有统计学意义
head(DEG_t.test)

19.使用limma包对表达矩阵及样本分组信息进行差异分析,得到差异分析表格,重点看logFC和P值,画个火山图(就是logFC和-log10(P值)的散点图)。
中级作业已经涉及。
参考 https://www.jianshu.com/p/e15ee2cd3174
# DEG by limma
suppressMessages(library(limma))
design <- model.matrix(~0+factor(group_list))
colnames(design)=levels(factor(group_list))
rownames(design)=colnames(exprSet)
design
## 下面的 contrast.matrix 矩阵非常重要,制定了谁比谁这个规则
contrast.matrix<-makeContrasts(paste0(unique(group_list),collapse = "-"),levels = design)
contrast.matrix
##这个矩阵声明,我们要把progres.组跟stable进行差异分析比较
##step1
fit <- lmFit(exprSet,design)
##step2
fit2 <- contrasts.fit(fit, contrast.matrix) ##这一步很重要,大家可以自行看看效果
fit2 <- eBayes(fit2) ## default no trend !!!
##eBayes() with trend=TRUE
##step3
tempOutput = topTable(fit2, coef=1, n=Inf)
nrDEG = na.omit(tempOutput)
#write.csv(nrDEG2,"limma_notrend.results.csv",quote = F)
head(nrDEG)

## volcano plot
DEG=nrDEG
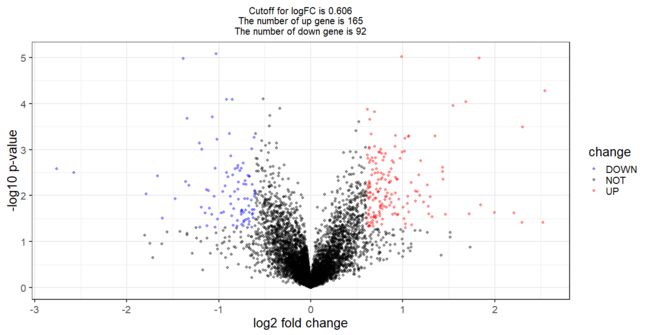
logFC_cutoff <- with(DEG,mean(abs( logFC)) + 2*sd(abs( logFC)) )
DEG$change = as.factor(ifelse(DEG$P.Value < 0.05 & abs(DEG$logFC) > logFC_cutoff,
ifelse(DEG$logFC > logFC_cutoff ,'UP','DOWN'),'NOT')
)
this_tile <- paste0('Cutoff for logFC is ',round(logFC_cutoff,3),
'\nThe number of up gene is ',nrow(DEG[DEG$change =='UP',]) ,
'\nThe number of down gene is ',nrow(DEG[DEG$change =='DOWN',])
)
this_tile
head(DEG)
g = ggplot(data=DEG, aes(x=logFC, y=-log10(P.Value), color=change)) +
geom_point(alpha=0.4, size=1.75) +
theme_set(theme_set(theme_bw(base_size=20)))+
xlab("log2 fold change") + ylab("-log10 p-value") +
ggtitle( this_tile ) + theme(plot.title = element_text(size=15,hjust = 0.5))+
scale_colour_manual(values = c('blue','black','red')) ## corresponding to the levels(res$change)
print(g)
20.对T检验结果的P值和limma包差异分析的P值画散点图,看看哪些基因相差很大。
### different P values
head(nrDEG)
head(DEG_t.test)
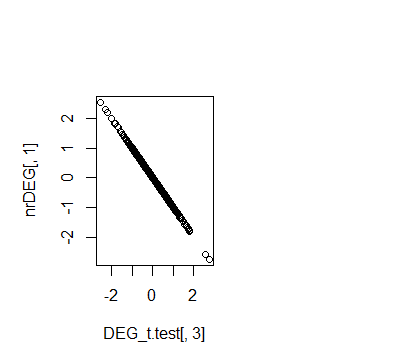
# 将limma生成的nrDEG与t检验合并
DEG_t.test=DEG_t.test[rownames(nrDEG),]
## 可以看到logFC是相反的
plot(DEG_t.test[,3],nrDEG[,1])
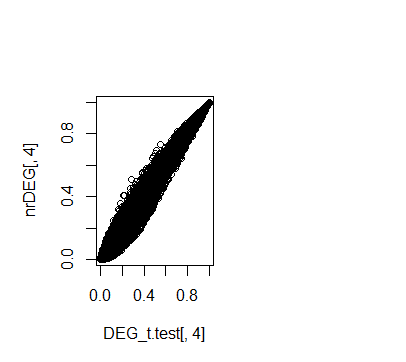
# 可以看到使用limma包和t.test本身的p值差异尚可接受
plot(DEG_t.test[,4],nrDEG[,4])
plot(-log10(DEG_t.test[,4]),-log10(nrDEG[,4]))
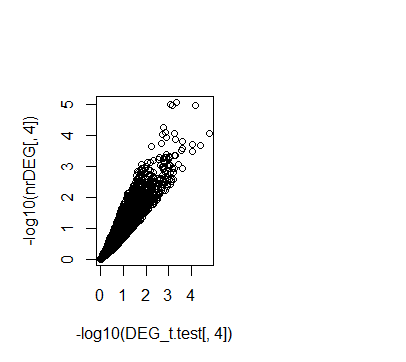
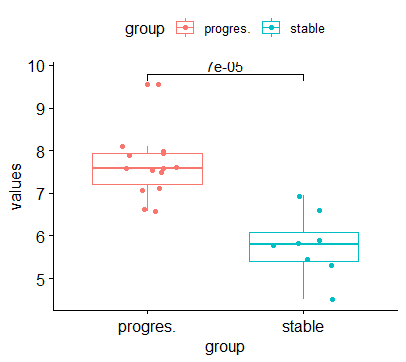
# 找3个基因看一下
exprSet['GAPDH',]
exprSet['ACTB',]
exprSet['DLEU1',]
library(ggplot2)
library(ggpubr)
my_comparisons <- list(
c("stable", "progres.")
)
dat=data.frame(group=group_list,
sampleID= names(exprSet['DLEU1',]),
values= as.numeric(exprSet['DLEU1',]))
ggboxplot(
dat, x = "group", y = "values",
color = "group",
add = "jitter"
)+
stat_compare_means(comparisons = my_comparisons, method = "t.test")
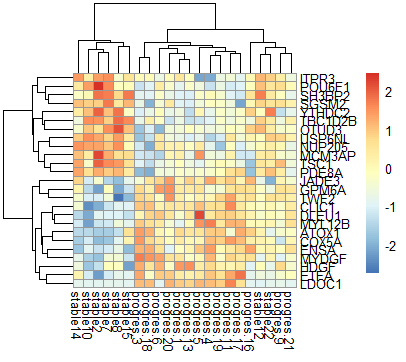
## heatmap
library(pheatmap)
choose_gene=head(rownames(nrDEG),25)
choose_matrix=exprSet[choose_gene,]
choose_matrix=t(scale(t(choose_matrix)))
pheatmap(choose_matrix)
后面几个题目会用函数就行,搞清楚根据不同的数据如何修改。
参考来源:生信技能树
友情链接:
课程分享
生信技能树全球公益巡讲
(https://mp.weixin.qq.com/s/E9ykuIbc-2Ja9HOY0bn_6g)
B站公益74小时生信工程师教学视频合辑
(https://mp.weixin.qq.com/s/IyFK7l_WBAiUgqQi8O7Hxw)
招学徒:
(https://mp.weixin.qq.com/s/KgbilzXnFjbKKunuw7NVfw)
欢迎关注公众号:青岛生信菜鸟团