论文链接:https://arxiv.org/pdf/1705.00108.pdf
从unlabeled text学习到的word embeddings已经成为一个NLP任务中的标准组成部分。然而,大多数情况下,recurrent network提取word-level的表示,这种表示包含了上下文信息,在少量标注的数据上训练。本文提出了一种半监督的方法,用来给双向语言模型添加pre-trained context embeddings,应用到序列标注问题上。在两个数据集上评估模型for NER and chunking(组块),都取得了很好的结果。
在NLP任务中,知道单词的意义很重要,知道它的上下文同样重要。
bidirectional RNN是在有标注的数据上训练的,本文提出一种半监督的方法,不需要额外标注数据。
使用一个neural language model(LM),在大量无标注的数据集上预训练,计算序列中每个位置的上下文encoding,并在有监督的序列标注任务中使用它。
本文的主要贡献是:
1. 将对上下文敏感的LM embeddings使用在有监督的序列标注上。将任务的F1值有提高。
2. 使用前向和后向LM embeddings可以提升performance,跟单前向LM相比。对领域特定的预训练是不必要的,通过使用LM trained in the news domain to scientific papers。
2. Language model augmented sequence taggers(TagLM)
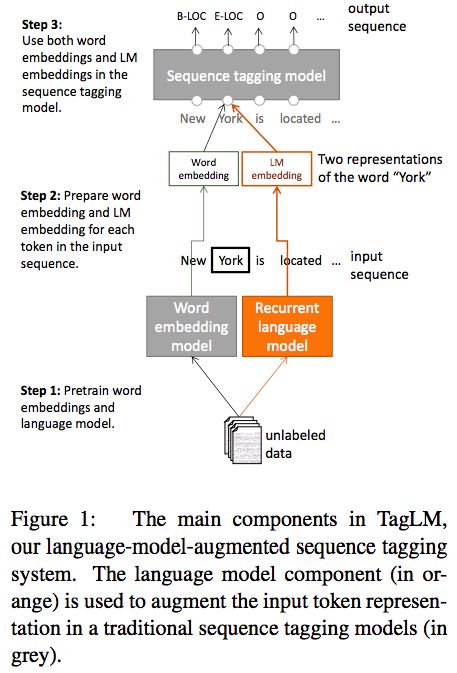
Baseline sequence tagging model:
一句tokens (t1, t2, ..., tN),首先构造一个representation,xk,对每个token会连接字符的representation ck 和 token embedding wk。
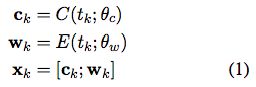
ck是通过CNN或RNN获取的morphological information(形态信息)
The token embeddings, wk, are obtained as a lookup E(., .),initialized using pre-trained word embeddings, and fine tuned during training
第一层----多层双向RNN:
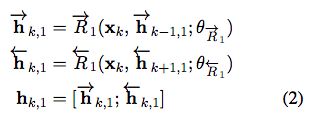
第二层----RNN:使用hk,1 输出hk,2
最后----第二层RNN的输出hk,L用于预测每个可能的标注的分数,using a single dense layer。
It is beneficial to model and decode each sentence jointly instead of independently predicting the label for each token
最后一层---with parameters for each label bigram, 计算句子的conditional random field(CRF) loss。在训练时使用前向-后向算法,使用Viterbi algorithm 找到最可能的标注序列
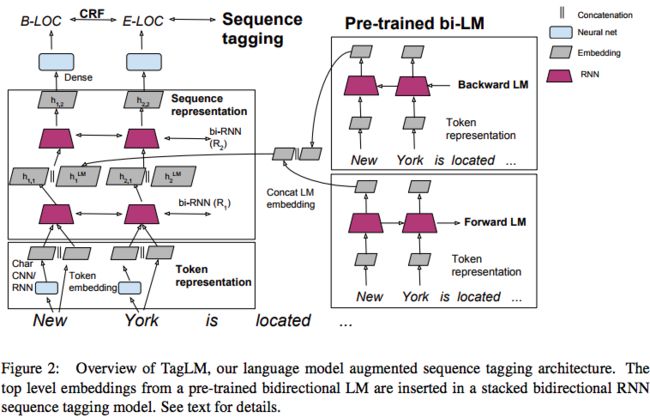
Bidirectional LM:
语言模型获取序列的概率(t1, t2, ..., tN)
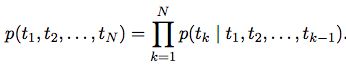
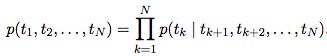
得到LM embedding:将前向和后向的embedding拼接 hkLM = [前向hkLM, 后向hkLM]
最终将LM和序列模型结合:
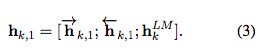
除了单纯连接之外,有另一种选择,可以增加非线性映射
另一种是增加一种attention-like机制
实验部分:对比了TagLM和没有额外标注数据的任务,对比了TagLM和有额外标注数据的任务
LM embedding添加的位置:1. input to the first RNN layer 2. output of the first RNN layer 3. output of the second RNN layer
结论:在序列标注模型中使用提前训练好的神经网络模型增加token representation,优于其他模型for NER