requests引子
概念:
requests是一个很实用的Python HTTP客户端库,我们在写爬虫的时候经常会用到
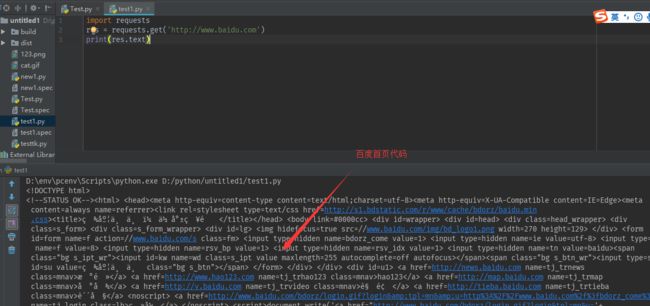
例:访问百度
res = requests.get('http://www.baidu.com')
print(res.text)
 1540136124988.png
1540136124988.png
1.requests请求方式
-
get
r = requests.get('https://api.github.com/events')
-
post
r = requests.post('http://httpbin.org/post', data = {'key':'value'})
-
put
r = requests.put('http://httpbin.org/put', data = {'key':'value'})
-
delete
r = requests.delete('http://httpbin.org/delete')
-
head
r = requests.head('http://httpbin.org/get')
-
option
r = requests.options('http://httpbin.org/get')
2.requests携带参数
-
params
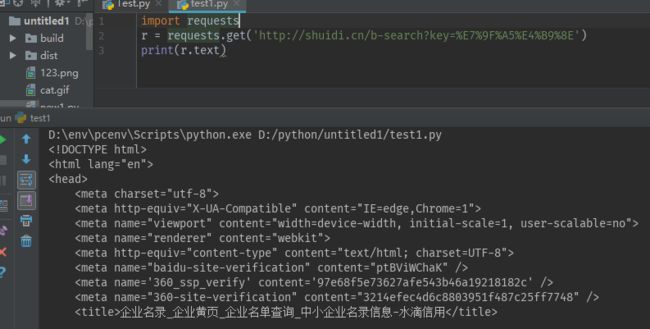
一般常用于get请求,用于 URL 的查询字符串,那么数据会以键/值对的形式置于 URL 中,跟在一个问号的后面, 使用&连接
-
例如:http://shuidi.cn/b-search?key=%E7%9F%A5%E4%B9%8E
第一种直接构建url:
 1540136921619.png
1540136921619.png
第二种params传递

-
data
-
通常,你想要发送一些编码为表单形式的数据——非常像一个 HTML 表单。要实现这个,只需简单地传递一个字典给 data 参数
payload = {'key1': 'value1', 'key2': 'value2'} r = requests.post("http://httpbin.org/post", data=payload) print(r.text){
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "/",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.19.1"
},
"json": null,
"origin": "183.220.26.60",
"url": "http://httpbin.org/post"
} -
很多时候你想要发送的数据并非编码为表单形式的。如果你传递一个
string而不是一个dict,那么数据会被直接发布出去。import requests url = 'https://api.github.com/some/endpoint' payload = {'some': 'data'} r = requests.post(url, json=payload) print(r.text){"message":"Not Found","documentation_url":"https://developer.github.com/v3"}
-
传递文件
url = 'http://httpbin.org/post' files = {'file': open('report.xls', 'rb')} r = requests.post(url, files=files) r.text{ ... "files": { "file": "" }, ... } -
data参数传入一个元组列表。在表单中多个元素使用同一 key 的时候,这种方式尤其有效:payload = (('key1', 'value1'), ('key1', 'value2')) r = requests.post('http://httpbin.org/post', data=payload) print(r.text){
"args": {},
"data": "",
"files": {},
"form": {
"key1": [
"value1",
"value2"
]
},
"headers": {
"Accept": "/",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.19.1"
},
"json": null,
"origin": "183.220.26.60",
"url": "http://httpbin.org/post"
}
-
-
headers
-
请求头
详细内容系转载:原文:https://blog.csdn.net/u012613251/article/details/82424691
Header 解释 示例
Accept 指定客户端能够接收的内容类型 Accept:text/plain,text/html
Accept-Charset 浏览器可以接受的字符编码集。 Accept-Charset:iso-8859-5
Accept-Encoding 指定浏览器可以支持的web服务器返回内容压缩编码类型。 Accept-Encoding:compress,gzip
Accept-Language 浏览器可接受的语言 Accept-Language:en,zh
Accept-Ranges 可以请求网页实体的一个或者多个子范围字段 Accept-Ranges:bytes
Authorization HTTP授权的授权证书 Authorization:Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
Cache-Control 指定请求和响应遵循的缓存机制 Cache-Control:no-cache
Connection 表示是否需要持久连接。(HTTP 1.1默认进行持久连接) Connection:close
Cookie HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 Cookie:$Version=1;Skin=new;
Content-Length 请求的内容长度 Content-Length:348
Content-Type 请求的与实体对应的MIME信息 Content-Type:application/x-www-form-urlencoded
Date 请求发送的日期和时间 Date:Tue,15 Nov 2010 08:12:31 GMT
Expect 请求的特定的服务器行为 Expect:100-continue
From 发出请求的用户的Email From:[email protected]
Host 指定请求的服务器的域名和端口号 Host:www.zcmhi.com
If-Match 只有请求内容与实体相匹配才有效 If-Match:“737060cd8c284d8af7ad3082f209582d”
If-Modified-Since 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 If-Modified-Since:Sat,29 Oct 2010 19:43:31 GMT
If-None-Match 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 If-None-Match:“737060cd8c284d8af7ad3082f209582d”
If-Range 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag If-Range:“737060cd8c284d8af7ad3082f209582d”
If-Unmodified-Since 只在实体在指定时间之后未被修改才请求成功 If-Unmodified-Since:Sat,29 Oct 2010 19:43:31 GMT
Max-Forwards 限制信息通过代理和网关传送的时间 Max-Forwards:10
Pragma 用来包含实现特定的指令 Pragma:no-cache
Proxy-Authorization 连接到代理的授权证书 Proxy-Authorization:Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ==
Range 只请求实体的一部分,指定范围 Range:bytes=500-999
Referer 先前网页的地址,当前请求网页紧随其后,即来路 Referer:http:
TE 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 TE:trailers,deflate;q=0.5
Upgrade 向服务器指定某种传输协议以便服务器进行转换(如果支持) Upgrade:HTTP/2.0,SHTTP/1.3,IRC/6.9,RTA/x11
User-Agent User-Agent的内容包含发出请求的用户信息 User-Agent:Mozilla/5.0(Linux;X11)
Via 通知中间网关或代理服务器地址,通信协议 Via:1.0 fred,1.1 nowhere.com(Apache/1.1)-
使用请求头
url = 'https://api.github.com/some/endpoint' headers = {'user-agent': 'my-app/0.0.1'} r = requests.get(url, headers=headers)
-
-
响应头
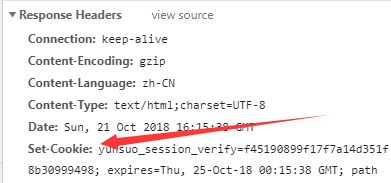
获取响应头
url = 'https://api.github.com/some/endpoint' headers = {'user-agent': 'my-app/0.0.1'} r = requests.get(url, headers=headers) print(r.headers)响应头里有一个参数Set-Cookie很重要,因为这是用来让浏览器设置cookie的,使用代码访问时需要使用这个cookie;
 1540138538764.png
1540138538764.pngLocation参数是302跳转后的网址
 1540138538764.png
1540138538764.png
-
-
proxies
代理就是你使用的是其他的ip地址去访问网址,用于爬虫被封ip后的应对方法
使用代理的方法可以选择一个IP用到死换,也可以选择用一段时间后就更换另外一批IP
proxies = { "http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080", } # http针对http网址生效, https针对https网址生效,如果没有,则是本地ip访问 r = requests.get("http://example.org", proxies=proxies) print(r.text) -
verify
-
Requests 可以为 HTTPS 请求验证 SSL 证书,就像 web 浏览器一样。SSL 验证默认是开启的,如果证书验证失败,Requests 会抛出 SSLError:
requests.get('https://github.com', verify=True) -
你可以为
verify传入 CA_BUNDLE 文件的路径,或者包含可信任 CA 证书文件的文件夹路径requests.get('https://github.com', verify='/path/to/certfile') -
忽略SSL证书验证时可设置为False
requests.get('https://kennethreitz.org', verify=False)
-
-
timeout
超时
为防止服务器不能及时响应,大部分发至外部服务器的请求都应该带着 timeout 参数。在默认情况下,除非显式指定了 timeout 值,requests 是不会自动进行超时处理的。如果没有 timeout,你的代码可能会挂起若干分钟甚至更长时间。
连接超时指的是在你的客户端实现到远端机器端口的连接时(对应的是
connect()_),Request 会等待的秒数。一个很好的实践方法是把连接超时设为比 3 的倍数略大的一个数值,因为 TCP 数据包重传窗口 (TCP packet retransmission window) 的默认大小是 3。一旦你的客户端连接到了服务器并且发送了 HTTP 请求,读取超时指的就是客户端等待服务器发送请求的时间。(特定地,它指的是客户端要等待服务器发送字节之间的时间。在 99.9% 的情况下这指的是服务器发送第一个字节之前的时间)。
# 延迟5s r = requests.get('https://github.com', timeout=5) # connect read r = requests.get('https://github.com', timeout=(3.05, 27)) # 永久超时 r = requests.get('https://github.com', timeout=None)
-
allow_redirects
-
可以选着禁止重定向的参数
r = requests.get('http://github.com', allow_redirects=False) print(r.status_code)
-
-
stream
-
获取来自服务器的原始套接字响应 需要设置的参数
r = requests.get('https://api.github.com/events', stream=True) print(r.raw) #print(r.raw.read(10)) # '\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03'
-
-
auth
-
身份验证, requests 简化了多种身份验证形式的使用,包括非常常见的 Basic Auth。
from requests.auth import HTTPBasicAuth auth = HTTPBasicAuth('[email protected]', 'not_a_real_password') r = requests.post(url=url, data=body, auth=auth) print(r.status_code) # 201 content = r.json() print(content[u'body']) #Sounds great! I'll get right on it.
-
-
cert
-
证书;可以指定一个本地证书用作客户端证书,可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组:
r = requests.get('https://kennethreitz.org', cert=('/path/client.cert', '/path/client.key')) print(r)
-
-
hooks
-
Requests有一个钩子系统,你可以用来操控部分请求过程,或信号事件处理。 你可以通过传递一个
{hook_name: callback_function}字典给hooks请求参数为每个请求分配一个钩子函数:若回调函数返回一个值,默认以该值替换传进来的数据。若函数未返回任何东西,也没有什么其他的影响。
def print_url(r, *args, **kwargs): print(r.url) hooks=dict(response=print_url) s = requests.get('http://httpbin.org', hooks=dict(response=print_url)) print(s) # http://httpbin.org/ #
-
3.requests解码方式
res.encoding = 'utf-8'
4.requests响应方式
-
res.text
文本
-
res.content
二进制(图片等)
-
res.headers
响应头
-
res.cookies.get_dict()
获取cookie
-
res.status_code()
状态码
-
res.json()
获取json数据
-
res.url
获取当前url
5.requests POST提交
- data 普通form_data数据提交
- file 文件提交
- json 普通pay_load数据提交
6.requests会话保持(Session)
会话对象让你能够跨请求保持某些参数。它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用
urllib3的 connection pooling 功能。所以如果你向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。session = requests.Session()
-
添加自带cookie:
requests.utils.add_dict_to_cookiejar(session.cookies,{"JESSION":"07et4ol1g7ttb0bnjmbiqjhp43"}) -
使用session登录的代码实例
- 专利汇 https://www.patenthub.cn/ 登录
import re import requests # 禁用安全请求警告 requests.packages.urllib3.disable_warnings() def login(username, password): """ 专利汇登录获取cookie, 使用session追踪cookie :param username: 用户名 :param password: 密码 :return: """ session = requests.Session() login_url = 'https://www.patenthub.cn/user/login.json' base_url = 'https://www.patenthub.cn/search/advanced.html' # 构建post参数, 通过谷歌抓包查看 data = { 'redirect_to': 'https://www.patenthub.cn/search/advanced.html', 'sso': '', 'account': username, 'password': password } # 构建请求头 headers = { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Host': 'www.patenthub.cn', 'Origin': 'https://www.patenthub.cn', 'Pragma': 'no-cache', 'Referer': 'https://www.patenthub.cn/user/login.html', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest' } # 使用session post登录 login_url res = session.post(login_url, headers=headers, data=data, verify=False) if res.status_code == 200: # 使用session 访问首页看是否访问成功 res = session.get(base_url, headers=headers) # 如果文档里含有用户名的前4个数字,则访问成功,返回cookie, 例:15928333211 ---文档里是 1592****3211 if re.findall(username[:3], res.text): cookies = session.cookies.get_dict() print(cookies) return cookies if __name__ == '__main__': login('13911111111', '123456')7.相关内容补充,日后再说