也看过其他讲vue diff过程的文章,但是感觉都只是讲了其中的一部分(对比方式),没有对其中细节的部分做详细的讲解,如
- 匹配成功后进行的
patchVnode是做了什么?为什么的有的紧接着要进行dom操作,有的没有? - 在diff的过程中,指针的具体如何移动?及哪些部分发生了变化?
-
insertedVnodeQueue又是何用?为何一直带着? - 然后也是困惑很久的,很多文章在移动这部分直接操作的oldChildren,然而oldChildren会发生移动么?那么到底是谁发生了移动呢?
这里并不会直接就开始讲diff,为了让大家能了解到diff的详细过程,所在开始核心部分之前,有些简单的概念和流程需要提前说明一下,当然最好是希望你已经对vue源码patch这部分有些了解。
几个概念
由于核心是说明diff的过程,所以会先把diff涉及到的核心概念简单说明一下,对于这些若仍有疑问可以在评论区留言:
1. vnode
简单的说就是真实 dom 的描述对象,这也是vue的特点之一 - virtual dom。由于原生的dom结构过于复杂,当需要获取并了解节点信息的时候,并不需要操作复杂的 dom,相应的vue 是先用其描述对象进行分析(diff 对比也就是vnode的对比),然后再反应到真实的 dom。
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
// strictly internal
raw: boolean; // contains raw HTML? (server only)
isStatic: boolean; // hoisted static node
isRootInsert: boolean; // necessary for enter transition check
isComment: boolean; // empty comment placeholder?
isCloned: boolean; // is a cloned node?
isOnce: boolean; // is a v-once node?
asyncFactory: Function | void; // async component factory function
asyncMeta: Object | void;
isAsyncPlaceholder: boolean;
ssrContext: Object | void;
functionalContext: Component | void; // real context vm for functional nodes
functionalOptions: ?ComponentOptions; // for SSR caching
functionalScopeId: ?string; // functioanl scope id support
constructor () {
...
}
}
需要注意的是后面会涉及到的几个属性:
-
children和parent通过这个建立其vnode之间的层级关系,对应的也就是真实dom的层级关系 -
text如果存在值,证明该vnode对应的就是一个文件节点,跟children是一个互斥的关系,不可能同时有值 -
tag表明当前vnode,对应真实 dom 的标签名,如‘div’、‘p’ -
elm就是当前vnode对应的真实的dom
2. patch
阅读源码中复杂函数的小技巧:看‘一头’‘一尾’。‘头’指的的入参,提炼出能看懂和能理解的参数(oldVnode、vnode、parentElm),‘尾’指的是函数的处理结果,这个返回的elm。所以可以根据‘头尾’总结下,patch完成之后,新的vnode上会对应生成elm,也就是真实的 dom,且是已经挂载到parentElm下的dom。简单的来说,如vue 实例初始化、数据更改导致的页面更新等,都需要经过patch方法来生成elm。
function patch (oldVnode, vnode, hydrating, removeOnly, parentElm, refElm) {
// ...
const insertedVnodeQueue = []
// ...
if (isUndef(oldVnode)) {
isInitialPatch = true
createElm(vnode, insertedVnodeQueue, parentElm, refElm)
}
// ...
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// patch existing root node
patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly)
}
// ...
return vnode.elm
}
patch 的过程(除去边界条件)主要会有三种 case:
不存在 oldVnode,则进行
createElm存在 oldVnode 和 vnode,但是
sameVnode返回 false, 则进行createElm存在 oldVnode 和 vnode,但是
sameVnode返回 true, 则进行patchVnode
3. sameVnode
上面提到了sameVnode,代码如下:
function sameVnode (a, b) {
return (
a.key === b.key && (
(
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
) || (
isTrue(a.isAsyncPlaceholder) &&
a.asyncFactory === b.asyncFactory &&
isUndef(b.asyncFactory.error)
)
)
)
}
简单的举个的case,比如之前是一个
标签了,则sameVnode会返回false(a.tag === b.tag 返回 false)。所以sameVnode表明的是,满足以上条件就是同一个元素,才可进行patchVnode。反过来理解就是,只要以上任意一个发生改变,则无需进行pathchVnode,直接根据vnode进行createElm即可。
注意,sameVnode 返回true,不能说明是同一个vnode,这里的相同是指当前的以上指标一致,他们的children可能发生了变化,仍需进行patchVnode进行更新。
patchVnode
由patch方法,我们知道patchVnode方法和createElm的方法最终的处理结果一样,就是生成或更新了当前vnode对应的dom。
经过上面的分析,总结下,就是当需要生成 dom,且前后vnode进行sameVnode为true的情况下,则进行patchVnode。
function patchVnode (oldVnode, vnode, insertedVnodeQueue, removeOnly) {
// ...
const elm = vnode.elm = oldVnode.elm
// ...
const oldCh = oldVnode.children
const ch = vnode.children
// ...
if (isUndef(vnode.text)) {
if (isDef(oldCh) && isDef(ch)) {
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 具体是何种情况下会走到这个逻辑???
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
nodeOps.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
nodeOps.setTextContent(elm, vnode.text)
}
// ...
}
以上是patchVnode的部分代码,展示出来的这部分逻辑,也是patchVnode的核心处理逻辑。
以上代码,充斥大量的if else,大家可以思考几个问题?
- 根据以上代码分析,对于一个vnode,可分成三种vnode: 文本vnode、存在chilren的vnode、不存在children的vnode。对于oldVnode和vnode交叉组合的话,应该会有9种 case,那么以上的代码有全部覆盖所有 case 么?
- 那比如,具体哪些
case会进入到removeVnodes的逻辑?
这其实也是我在阅读的时候思考的问题,最终我采用了以下的方式(对着代码绘制表格)来解决这种复杂的if else逻辑的解读:
| oldVnode.text | oldCh | !oldCh | |
|---|---|---|---|
| vnode.text | setTextContent | setTextContent | setTextContent |
| ch | addVnodes | updateChildren | addVnodes |
| !ch | setTextContent | removeVnodes | setTextContent |
对应着表格,然后对应着代码,相信你能找到答案。
updateChildren
经过上面的分析,只有在oldCh和ch都存在的情况下才会执行updateChildren,此时入参是oldCh和ch,所以可以知道的是,updateChildren进行的是同层级下的children的更新比较,也就是‘传说中的’diff了。
开始分析之前,可以思考下:若现在js来操作原生dom的一个
- 列表,当然这个列表也是用原生的js来实现的,现在如果其中的数据顺序发生了变化,第一条要排到末尾或具体的某个位置,或者有新增数据、删除数据等,该如何操作。
let listData = [
'测试数据1',
'测试数据2',
'测试数据3',
'测试数据4',
'测试数据5',
]
let ulElm = document.createElement('ul');
let liStr = '';
for(let i = 0; i < listData.length; i++){
liStr += `${listData[i]} `
}
ulElm.append(liStr)
document.body.innerHTML = ''
document.body.append(ulElm)
这个时候由于变化的不确定性,不希望在业务代码逻辑中维护繁琐的insertBefore、appendChild、removeChild、replaceChild,立马能想到的粗暴的解决方式是,我们拿到最新的listData,把上面面创建的流程再走一遍。
然而vue采取的是diff算法,简单的说就是:
- 还是和上面一样,依然先获取到最新的
listData - 然后新的 data 进行
_render操作,得到新的vnode - 对比前后vnode,也就是patch过程
- 对于同一层级的节点,会进行
updateChildren操作(diff),进行最小的变动
diff
updateChildren代码如下:
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
// removeOnly is a special flag used only by
// to ensure removed elements stay in correct relative positions
// during leaving transitions
const canMove = !removeOnly
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) { // New element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
} else {
vnodeToMove = oldCh[idxInOld]
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && !vnodeToMove) {
warn(
'It seems there are duplicate keys that is causing an update error. ' +
'Make sure each v-for item has a unique key.'
)
}
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue)
oldCh[idxInOld] = undefined
canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
// same key but different element. treat as new element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
之前分析了,oldCh和ch表示的是同层级的vnode的列表,也就是两个数组
开始之前定义了一系列的变量,分别如下:
-
oldStartIdx开始指针,指向oldCh中待处理部分的头部,对应的vnode也就是oldStartVnode -
oldEndIdx结束指针,指向oldCh中待处理部分的尾部,对应的vnode也就是oldEndVnode -
newStartIdx开始指针,指向ch中待处理部分的头部,对应的vnode也就是newStartVnode -
newEndIdx结束指针,指向ch中待处理部分的尾部,对应的vnode也就是newEndVnode -
oldKeyToIdx是一个map,其中key就是常在for循环中写的v-bind:key的值,value 对应的就是当前vnode,也就是可以通过唯一的key,在map中找到对应的vnode
updateChildren使用的是while循环来更新dom的,其中的退出条件就是!(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx),换种理解方式:oldStartIdx > oldEndIdx || newStartIdx > newEndIdx,什么意思呢,就是只要有一个发生了‘交叉’(下面的例子会出现交叉)就退出循环。
举个栗子
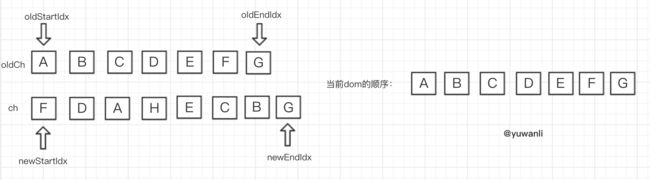
原有的oldCh的顺序是 A 、B、C、D、E、F、G,更新后成ch的顺序 F、D、A、H、E、C、B、G。
图解说明
为了更好理解后续的round,开始之前先看下相关符合标记的说明
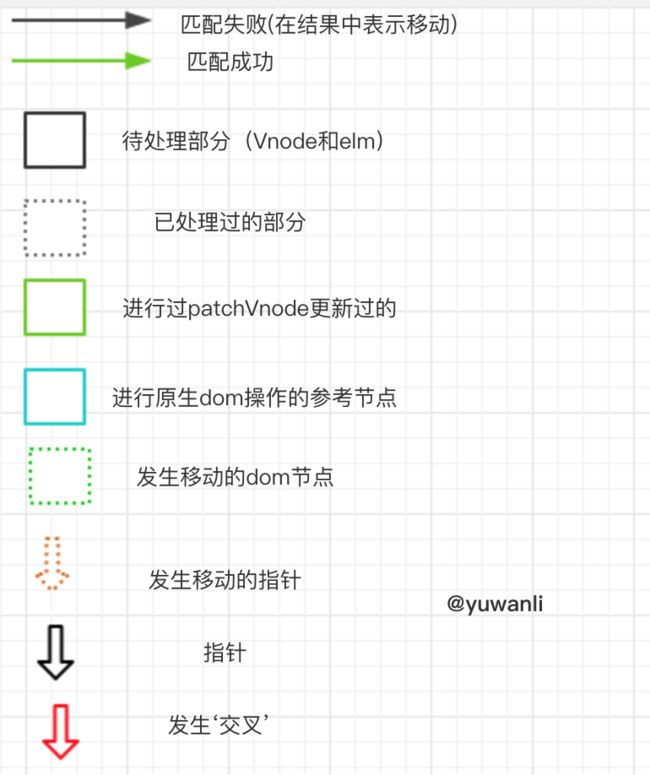
diff的过程
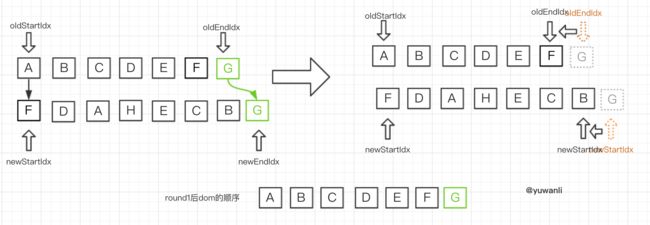
round1:
对比顺序:A-F -> G-G,匹配成功,然后:
- 对G进行
patchVnode的操作,更新oldEndVnodeG和newEndVnodeG的elm - 指针移动,两个尾部指针向左移动,即
oldEndIdx--newEndIdx--
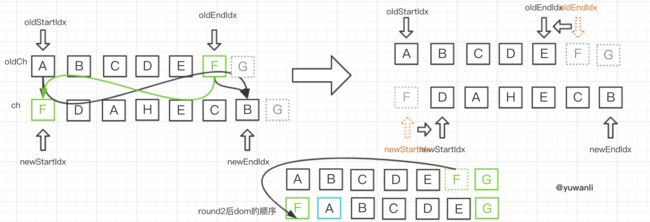
round2:
对比顺序:A-F -> F-B -> A-B -> F-F,匹配成功,然后:
- 对F进行
patchVnode的操作,更新oldEndVnodeF和newEndVnodeF的elm - 指针移动,移动指针,即
oldEndIdx--newStartIdx++ - 找到
oldStartVnode在dom中所在的位置A,然后在其前面插入更新过的F的elm
round3:
对比顺序:A-D -> E-B -> A-B -> E-D,仍未成功,取D的key,在oldKeyToIdx中查找,找到对应的D,查找成功,然后:
- 将D取出赋值到
vnodeToMove - 对D进行
patchVnode的操作,更新vnodeToMoveD和newStartVnodeD的elm - 指针移动,移动指针,即
newStartIdx++ - 将oldCh中对应D的vnode置
undefined - 在dom中找到
oldStartVnodeA的elm对应的节点,然后在其前面插入更新过的D的elm

round4:
对比顺序:A-A,对比成功,然后:
- 对A进行
patchVnode的操作,更新oldStartVnodeA和newStartVnodeA的elm - 指针移动,两个尾部指针向左移动,即
oldStartIdx++newStartIdx++
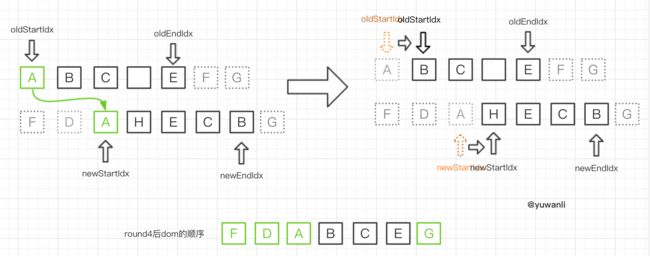
round5:
对比顺序:B-H -> E-B -> B-B ,对比成功,然后:
- 对B进行
patchVnode的操作,更新oldStartVnodeB和newStartVnodeB的elm - 指针移动,即
oldStartIdx++newEndIdx-- - 在dom中找到
oldEndVnodeE的elm的nextSibling节点(即G的elm),然后在其前面插入更新过的B的elm
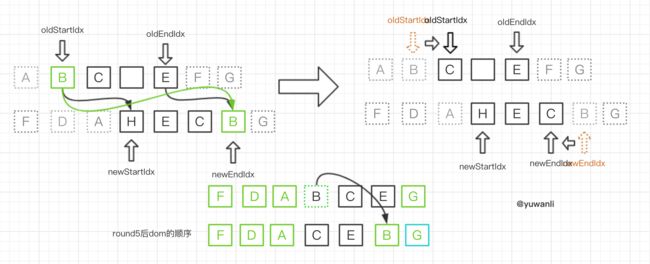
round6:
对比顺序:C-H -> E-C -> C-C ,对比成功,然后(同round5):
- 对C进行
patchVnode的操作,更新oldStartVnodeC和newStartVnodeC的elm - 指针移动,即
oldStartIdx++newEndIdx-- - 在dom中找到
oldEndVnodeE的elm的nextSibling节点(即刚刚插入的B的elm),然后在其前面插入更新过的C的elm
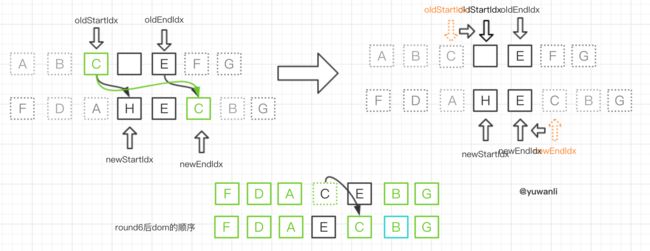
round7:
获取oldStartVnode失败(因为round3的步骤4),然后:
- 指针移动,即
oldStartIdx++
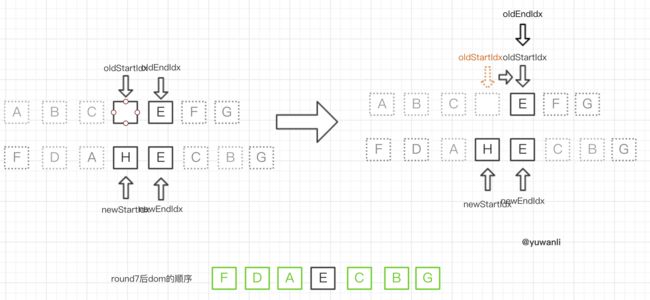
round8:
对比顺序:E-H、E-E,匹配成功,然后(同round1):
- 对E进行
patchVnode的操作,更新oldEndVnodeE和newEndVnodeE的elm - 指针移动,两个尾部指针向左移动,即
oldEndIdx--newEndIdx--

last
round8之后oldCh提前发生了‘交叉’,退出循环。

last:
- 找到
newEndIdx+1对应的元素A - 待处理的部分(即
newStartIdx-newEndIdx中的vnode)则为新增的部分,无需patch,直接进行createElm - 所有的这些待处理的部分,都会插到步骤1中dom中A的elm所在位置的后面
需要注意的点:
- oldCh和ch在过程中他们的位置并不会发生变化
- 真正进行操作的是进入
updateChildren传入的parentElm,即父vnode的elm - while每一次的循环体,我称之为回和,也就是round
- 多次提到
patchVnode,往前看patchVnode的部分,其处理的结果就是oldVnode.elm和vnode.elm得到了更新 - 有多次的原生的dom的操作,
insertBefore,重点是要先找到插入的地方
总结
每一个round(以上例子中涉及到的)做的事情如下(优先级从上至下):
- 无
oldStartVnode则移动(参照round6) - 对比头部,成功则更新并移动(参照round4)
- 对比尾部,成功则更新并移动(参照round1)
- 头尾对比,成功则更新并移动(参照round5)
- 尾头对比,成功则更新并移动(参照round2)
- 在
oldKeyToIdx中根据newStartVnode的可以进行查找,成功则更新并移动(参照round3)
(更新并移动:patchVnode更新对应vnode的elm,并移动指针)
关于插入的问题,为何有的紧接着进行的dom操作,有的没有?何时在oldStartVnode的elm前插,何时在oldEndVnode的elm的nextSibling前插?
这里只要记住,oldCh和ch都是参照物,其中,ch是我们的目标顺序,而oldCh是我们用来了解当前dom顺序的参照,也就是开篇提到的vnode的介绍。所以整个diff过程,就是对比oldCh和ch,确认当前round,oldCh如何移动更靠近ch,由于oldCh中待处理的部分仍在dom中,所以可以根据oldCh中的oldStartVnode的elm和 oldEndVnode的elm的位置,来确定匹配成功的元素该如何插入。
- ‘头头’匹配成功的时候,证明当前
oldStartVnode位置正是现在的位置,无需移动,进行patchVnode更新即可 - ‘尾尾’匹配成功同‘头头’匹配成功,也无需移动
- 若‘尾头匹配成功’,即
oldEndVnode与newSatrtVnode匹配成功,这里注意成功的是newSatrtVnode,所以是在待处理dom的头部前插。如round2,当前待处理的部分,也就是oldCh中黑块的部分,头部也就是oldStartVnode。也就是在oldStartVnode的elm前面插入newSatrtVnode的elm。 - 同理,若‘头尾匹配成功’,即
oldStartVnode与newEndVnode匹配成功,这里注意成功的是newEndVnode,所以是在待处理dom的尾部插入(就是尾部元素的下一个元素前插)。如round5,当前待处理的部分,也就是oldCh中黑块的部分,尾部也就是oldEndVnode。也就是先找到oldEndVnode的elm的nextSibling前面插入newEndVnode的elm。
(这里有提到‘待处理块’,具体大家可以看示意图,注意oldCh中的待处理块部分和dom中待处理的部分)
以上已经包含updateChildren中大部分的内容了,当然还有部分没有涉及到的就不一一说明的,具体的大家可以对着源码,找个实例走整个的流程即可。
最后还有一个问题没回答,insertedVnodeQueue有何用?为啥一直带着?
这部分涉及到组件的patch的过程,这里可以简单说下:组件的$mount函数之后之后并不会立即触发组件实例的mounted钩子,而是把当前实例push到insertedVnodeQueue中,然后在patch的倒数第二行,会执行invokeInsertHook,也就是触发所有组件实例的insert的钩子,而组件的insert钩子函数中才会触发组件实例的mounted钩子。比方说,在patch的过程中,patch了多个组件vnode,他们都进行了$mount即生成dom,但没有立即触发$mounted,而是等整个patch完成,再逐一触发。