目前市面上有很多大数据框架,如批处理框架Hadoop,流处理框架Storm,以及混合处理型框架Flink和Spark,本文将针对以上几个主流框架进行阐述比较。
批处理框架介绍
批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。
大量数据的处理需要付出大量时间,因此批处理不适合对处理时间要求较高的场合。
Apache Hadoop
批处理模式
Hadoop的处理功能来自MapReduce引擎,采用了hadoop分布式文件系统HDFS。可以在普通的PC集群上提供可靠的文件存储,通过数据块进行多个副本备份来解决服务器宕机或者硬盘损坏的问题。
MapReduce,把并发、分布式(如机器间通信)和故障恢复等计算细节隐藏起来,在有足够量计算机集群的前提下,一般每台机器构成一个Maper或者Reducer。
MapReduce的处理技术符合使用键值对的map、shuffle、reduce算法要求。由Map和Reduce两个部分组成一个job,再由job组成DAG,其中把非常重要的Shuffle过程隐藏起来。基本处理过程包括:
从HDFS文件系统读取数据集
将数据集拆分成小块并分配给所有可用节点
针对每个节点上的数据子集进行计算
中间结果暂时保存在内存中,达到阈值会写到磁盘上
重新分配中间态结果并按照键进行分组
通过对每个节点计算的结果进行汇总和组合对每个键的值进行“Reducing”
将计算而来的最终结果重新写入 HDFS
map产生的中间结果暂时保存在内存中,该缓冲区的默认大小是100MB,可以通过参数io.sort.mb来调整其大小。当缓冲区中的数据使用率达到一定阀值后,将环形缓冲区中的部分数据写到磁盘上,生成一个临时的Linux本地数据的spill文件;然后在缓冲区的使用率再次达到阀值后,再次生成一个spill文件。直到数据处理完毕,在磁盘上会生成很多的临时文件。
由于这种方法严重依赖持久存储,每个任务需要多次执行读取和写入操作,因此速度相对较慢。但另一方面由于磁盘空间通常是服务器上最丰富的资源,这意味着MapReduce可以处理非常海量的数据集。同时也意味着相比其他类似技术,Hadoop的MapReduce通常可以在廉价硬件上运行,因为该技术并不需要将一切都存储在内存中。MapReduce具备极高的缩放潜力,生产环境中曾经出现过包含数万个节点的应用。
Hadoop的局限性
- 表层上只提供了Map和Reduce两个操作,处理逻辑隐藏在代码中,整体逻辑不够清晰
- 相对于Storm等流式框架,时延比较高,只适用于批数据处理,难以处理实时数据
结论
Apache Hadoop及其MapReduce处理引擎提供了一套久经考验的批处理模型,最适合处理对时间要求不高的非常大规模数据集。
流处理框架介绍
流处理系统会对随时进入系统的数据进行计算。相比批处理模式,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作。流处理主要针对副作用更少,更加功能性的处理(Functional processing)进行优化。
此类处理非常适合某些类型的工作负载。有实时处理需求的任务很适合使用流处理模式。分析服务器或应用程序错误日志,以及其他基于时间的衡量指标是最适合的类型,因为对这些领域的数据变化做出响应对于业务职能来说是极为关键的。流处理很适合用来处理必须对变动或峰值做出响应,并且关注一段时间内变化趋势的数据。
Apache Storm
流处理模式
Storm的流处理可对框架中名为Topology的DAG进行编排。这些拓扑描述了当数据片段进入系统后,需要对每个传入的片段执行的不同转换或步骤。
拓扑包含:
Stream:普通的数据流,这是一种会持续抵达系统的无边界数据。
Spout:位于拓扑边缘的数据流来源,例如可以是API或查询等,从这里可以产生待处理的数据。
Bolt:Bolt代表需要消耗流数据,对其应用操作,并将结果以流的形式进行输出的处理步骤。Bolt需要与每个Spout建立连接,随后相互连接以组成所有必要的处理。在拓扑的尾部,可以使用最终的Bolt输出作为相互连接的其他系统的输入。
默认情况下Storm提供了“至少一次”的处理保证,这意味着可以确保每条消息至少可以被处理一次,但某些情况下如果遇到失败可能会处理多次。Storm无法确保可以按照特定顺序处理消息。
总结
对于延迟需求很高的纯粹的流处理工作负载,Storm可能是最适合的技术。该技术可以保证每条消息都被处理,可配合多种编程语言使用。由于Storm无法进行批处理,如果需要这些能力可能还需要使用其他软件。如果对严格的一次处理保证有比较高的要求,此时可考虑使用Trident。不过这种情况下其他流处理框架也许更适合。
混合处理系统
Apache Flink
Apache Flink是一种可以处理批处理任务的流处理框架。该技术可将批处理数据视作具备有限边界的数据流,借此将批处理任务作为流处理的子集加以处理。Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
整体组件栈
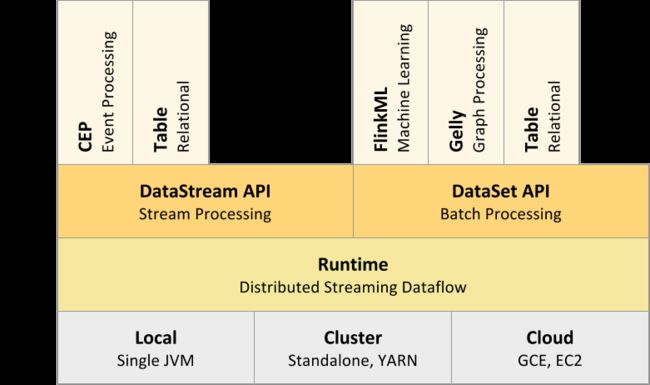
流处理模型
Flink的流处理模型在处理传入数据时会将每一项视作真正的数据流。Flink提供的DataStream API可用于处理无尽的数据流。Flink可配合使用的基本组件包括:
Stream是指在系统中流转的的无边界数据集
Operator是指针对数据流执行操作以产生其他数据流的功能
Source 是指数据流进入系统的入口点
Sink是指数据流离开Flink系统后进入到的位置,槽可以是数据库或到其他系统的连接器
Flink可以对批处理工作负载实现一定的优化。例如由于批处理操作可通过持久存储加以支持,Flink可以不对批处理工作负载创建快照。数据依然可以恢复,但常规处理操作可以执行得更快。
另一个优化是对批处理任务进行分解,这样即可在需要的时候调用不同阶段和组件。借此Flink可以与集群的其他用户更好地共存。对任务提前进行分析使得Flink可以查看需要执行的所有操作、数据集的大小,以及下游需要执行的操作步骤,借此实现进一步的优化。
基本架构
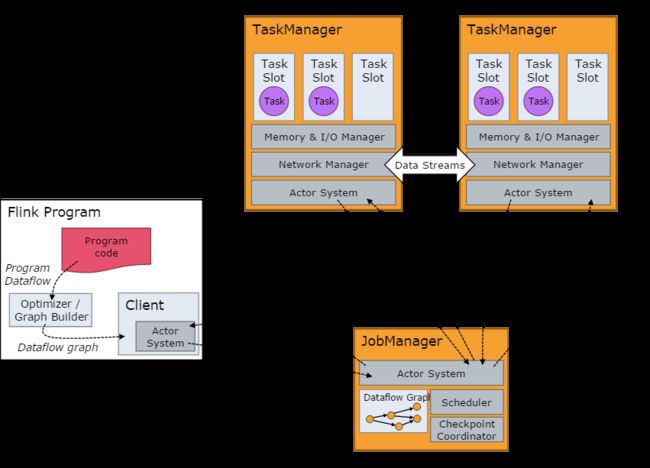
从上图可以分析出Flink运行时的整体状态。 Flink的Driver程序会将代码逻辑构建成一个Program Dataflow(区分source,operator,sink等等),在通过Graph Builder构建DAG的Dataflow graph, 构建job,划分出task 和subtask等等。 Client 将job 提交到JobManager. Client 通过Actor System和JobManager 进行消息通讯,接收JobManager返回的状态更新和任务执行统计结果。 JobMangaer 按照Dataflow的Task 和Subtask的划分,将任务调度分配到各个TaskManager中进行执行。TaskManager会将内存抽象成多个TaskSlot,用于执行Task任务。JobManagers与TaskManagers之间的任务管理,Checkpoints的触发,任务状态,心跳等等消息处理都是通过ActorSystem。
优势和局限
Flink目前是处理框架领域一个独特的技术。虽然Spark也可以执行批处理和流处理,但Spark的流处理采取的微批架构使其无法适用于很多用例。Flink流处理为先的方法可提供低延迟,高吞吐率,近乎逐项处理的能力。
在用户工具方面,Flink同样提供了基于Web的调度视图。对于分析类任务,Flink提供了类似SQL的查询,图形化处理,以及机器学习库,此外还支持内存计算。
Flink能很好地与其他组件配合使用。如果配合Hadoop使用,该技术可以很好地融入整个环境,在任何时候都只占用必要的资源。该技术可轻松地与YARN、HDFS和Kafka 集成。
总结
Flink提供了低延迟流处理,同时可支持传统的批处理任务。Flink也许最适合有极高流处理需求,并有少量批处理任务的组织。该技术可兼容原生Storm和Hadoop程序,可在YARN管理的集群上运行,因此可以很方便地进行评估。
Apache Spark
Apache Spark是一种包含流处理能力的下一代批处理框架。特色是提供了一个集群的分布式内存抽象RDD(Resilient Distributed DataSet),即弹性分布式数据集。Spark上有RDD的两种操作,actor和traformation。transformation包括map、flatMap等操作,actor是返回结果,如Reduce、count、collect等。
批处理模式
与MapReduce不同,Spark的数据处理工作全部在内存中进行,只在一开始将数据读入内存,以及将最终结果持久存储时需要与存储层交互。所有中间态的处理结果均存储在内存中。
Spark流结构如下图所示:

对比 Hadoop MapReduce 和 Spark 的 Shuffle 过程
如果熟悉 Hadoop MapReduce 中的 shuffle 过程,可能会按照 MapReduce 的思路去想象 Spark 的 shuffle 过程。然而,它们之间有一些区别和联系。
从 high-level 的角度来看,两者并没有大的差别。 都是将 mapper(Spark 里是 ShuffleMapTask)的输出进行 partition,不同的 partition 送到不同的 reducer(Spark 里 reducer 可能是下一个 stage 里的 ShuffleMapTask,也可能是 ResultTask)。Reducer 以内存作缓冲区,边 shuffle 边 aggregate 数据,等到数据 aggregate 好以后进行 reduce() (Spark 里可能是后续的一系列操作)。
从 low-level 的角度来看,两者差别不小。 Hadoop MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先 sort。这样的好处在于 combine/reduce() 可以处理大规模的数据,因为其输入数据可以通过外排得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。目前的 Spark 默认选择的是 hash-based,通常使用 HashMap 来对 shuffle 来的数据进行 aggregate,不会对数据进行提前排序。如果用户需要经过排序的数据,那么需要自己调用类似 sortByKey() 的操作;如果你是Spark 1.1的用户,可以将spark.shuffle.manager设置为sort,则会对数据进行排序。在Spark 1.2中,sort将作为默认的Shuffle实现。
从实现角度来看,两者也有不少差别。 Hadoop MapReduce 将处理流程划分出明显的几个阶段:map(), spill, merge, shuffle, sort, reduce() 等。每个阶段各司其职,可以按照过程式的编程思想来逐一实现每个阶段的功能。在 Spark 中,没有这样功能明确的阶段,只有不同的 stage 和一系列的 transformation(),所以 spill, merge, aggregate 等操作需要蕴含在 transformation() 中。
如果我们将 map 端划分数据、持久化数据的过程称为 shuffle write,而将 reducer 读入数据、aggregate 数据的过程称为 shuffle read。那么在 Spark 中,问题就变为怎么在 job 的逻辑或者物理执行图中加入 shuffle write 和 shuffle read 的处理逻辑?以及两个处理逻辑应该怎么高效实现?
优势和局限
使用Spark而非Hadoop MapReduce的主要原因是速度。在内存计算策略和先进的DAG调度等机制的帮助下,Spark可以用更快速度处理相同的数据集。
Spark的另一个重要优势在于多样性。该产品可作为独立集群部署,或与现有Hadoop集群集成。该产品可运行批处理和流处理,运行一个集群即可处理不同类型的任务。
为流处理系统采用批处理的方法,需要对进入系统的数据进行缓冲。缓冲机制使得该技术可以处理非常大量的传入数据,提高整体吞吐率,但等待缓冲区清空也会导致延迟增高。这意味着Spark Streaming可能不适合处理对延迟有较高要求的工作负载。
Spark生态系统中还包括很多附加库,介绍如下:
Spark Streaming:
Spark Streaming基于微批量方式的计算和处理,可以用于处理实时的流数据。它使用DStream,一个弹性分布式数据集(RDD)系列,来处理实时数据。Spark SQL:
Spark SQL可以通过JDBC API查询Spark数据集,而且还可以用传统的BI和可视化工具在Spark数据上执行类似SQL的查询。用户还可以用Spark SQL对不同格式的数据(如JSON等)执行ETL,将其转化,然后被给予特定的查询。Spark MLlib:
MLlib是一个可扩展的Spark机器学习库,由通用的学习算法和工具组成,包括线性回归、聚类、梯度下降等Spark GraphX:
GraphX是用于图计算和并行图计算的新的(alpha)Spark API。通过引入弹性分布式属性图(Resilient Distributed Property Graph),一种顶点和边都带有属性的有向多重图,扩展了Spark RDD。
总结
Spark是多样化工作负载处理任务的最佳选择。Spark批处理能力以更高内存占用为代价提供了无与伦比的速度优势。对于重视吞吐率而非延迟的工作负载,则比较适合使用Spark Streaming作为流处理解决方案
总结
大数据系统可针对性地使用多种处理框架
对于仅需要批处理的工作负载,如果对时间不敏感,比其他解决方案实现成本更低的Hadoop将会是一个好选择。数据量非常大的时候MapReduce要比Spark快。
对于仅需要流处理的工作负载,Storm可支持更广泛的语言并实现极低延迟的处理,但默认配置可能产生重复结果并且无法保证顺序。
对于混合型工作负载,Spark把streaming看成是更快的批处理,而Flink把批处理看成streaming的special case。Spark可提供高速批处理和微批处理模式的流处理。该技术的支持更完善,具备各种集成库和工具,可实现灵活的集成。Flink提供了真正的流处理并具备批处理能力,通过深度优化可运行针对其他平台编写的任务,提供低延迟的处理。
参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.3/concepts/programming-model.html
http://codingxiaxw.cn/2016/12/10/61-spark-streaming
http://xuexi.edu360.cn/88.html