1.首先下载phantomjs、selenium,将phantomjs放于设置环境变量的目录中,

2.尝试获取加载js后的单页面,

Paste_Image.png
from urllib import request
import urllib
from bs4 import BeautifulSoup as bs
import re
import os
import pandas as pd
import time
import random
from selenium import webdriver
def getHtml(url):
driver=webdriver.PhantomJS();
driver.get(url)
return driver.page_source
page_info=getHtml('http://tv.sohu.com/item/MTIwNjUzMg==.html')
soup = bs(page_info, 'html5lib')
tp=soup.find('em','total-play').string
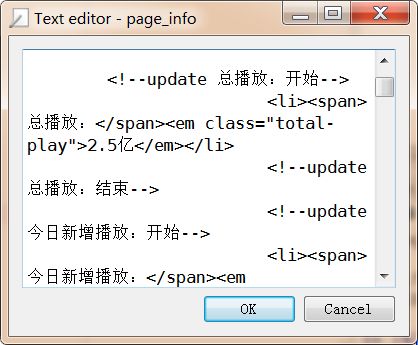
Paste_Image.png
发现播放量成功得到了加载,爬取成功。
3.尝试多页面的爬取
由于爬取中需要模拟浏览器,加载js文件,因此如果未加载完全进行处理,就会获取不到信息。确保加载完全,需要设置等待时间,爬取速度较慢。将代码改写为多进程可加快速度,但仍然受到限制。
from urllib import request
import urllib
from bs4 import BeautifulSoup as bs
import re
import pandas as pd
import time
import random
import multiprocessing
from itertools import chain
from selenium import webdriver
import sys
sys.setrecursionlimit(10000000)
def urlAdd():
list_type=['1100','1101','1102','1103','1104','1105','1106','1107','1108','1109','1110','1111','1112','1113','1114'
,'1115','1116','1117','1118','1119','1120','1121','1122','1123','1124','1125','1127','1128']
list_loc=['1000','1001','1002','1003','1004','1015','1007','1006','1014']
list_time=['2017','2016','2015','2014','2013','2012','2011','2010','11','90','80','1']
return list_loc,list_type,list_time
def PageCreate():
urlsys=[]
list_loc,list_type,list_time=urlAdd()
for loc in list_loc:
for type_1 in list_type:
for time_1 in list_time:
url1='http://so.tv.sohu.com/list_p1101_p210%s_p3%s_p4%s_p5_p6_p7_p8_p92_p101_p11_p12_p13.html'%(type_1,loc,time_1)
urlsys.append(url1)
return urlsys
def urlsPages(url):
url_hrefs=[]
time.sleep(5+random.uniform(-1,1))
req=urllib.request.Request(url)
req.add_header("Origin","http://so.tv.sohu.com")
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2657.3 Safari/537.36')
resp=request.urlopen(req,timeout=300)
html=resp.read().decode("utf-8")
soup = bs(html, 'lxml')
if soup.find_all(attrs={'title':'下一页'})==[]:
page=1
else:
page=int(soup.find_all(attrs={'title':'下一页'})[-1].find_previous_sibling().string)
for i in range(page):
url_page=url.replace('p101',('p10'+str(i+1)))
time.sleep(5+random.uniform(-1,1))
print(url_page)
req=urllib.request.Request(url_page)
req.add_header("Origin","http://so.tv.sohu.com")
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2657.3 Safari/537.36')
resp=request.urlopen(req,timeout=300)
html=resp.read().decode("utf-8")
soup = bs(html, 'html5lib')
hrefs=soup.find_all(attrs={'pb-url':'meta$$list'})
for hreftq in hrefs:
url_href=hreftq.get('href')
url_hrefs.append("http:"+url_href)
return url_hrefs
def getInfo(url):
info=[]
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 100000
cap["phantomjs.page.settings.loadImages"] = False
cap["phantomjs.page.settings.userAgent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2657.3 Safari/537.36"
driver=webdriver.PhantomJS(desired_capabilities=cap)
driver.implicitly_wait(30)
driver.get(url)
time.sleep(3+random.uniform(-1,1))
ps=driver.page_source
soup = bs(ps,'html5lib')
print('有无',soup.find_all('em','total-play'))
if(len(soup.find_all('span','vname'))>=1):
name=soup.find_all('span','vname')[0].getText()
info.append(name)
else:
info.append('missing')
if(len(soup.find_all('em','total-play'))>=1):
tp=soup.find_all('em','total-play')[0].getText()
info.append(tp)
else:
info.append('missing')
print(info)
return info
if __name__ == "__main__":
url_hrefss=[]
urlsys=PageCreate()
print(urlsys)
pool = multiprocessing.Pool(multiprocessing.cpu_count())
url_hrefss.append(pool.map(urlsPages,urlsys))
pool.close()
pool.join()
url_links = list(chain(*url_hrefss))
url_links = list(chain(*url_links))
url_links = [i for i in url_links if i != []]
url_links = list(set(url_links))
print('所有页面',url_links)
infos=[]
pool = multiprocessing.Pool(multiprocessing.cpu_count())
infos.extend(pool.map(getInfo,url_links))
print(infos)
sohu_infos=pd.DataFrame(infos)
sohu_infos.to_csv("c:/tv_his_sohu.csv")
4.利用json文件获取
详情页通过加载json文件,显示播放量。
Paste_Image.png
而每一个plids对应一条记录。
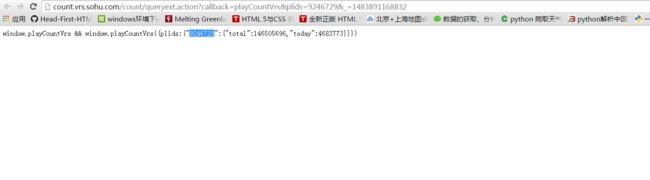
Paste_Image.png
plids可以在网页源代码中提取到,将该值添加到json文件的url里面的对应位置就可以获取所要的信息。

Paste_Image.png
from urllib import request
import urllib
from bs4 import BeautifulSoup as bs
import re
import pandas as pd
import time
import random
import sys
import multiprocessing
from itertools import chain
sys.setrecursionlimit(10000000)
def urlAdd():
list_type=['1100','1101','1102','1103','1104','1105','1106','1107','1108','1109','1110','1111','1112','1113','1114'
,'1115','1116','1117','1118','1119','1120','1121','1122','1123','1124','1125','1127','1128']
list_loc=['1000','1001','1002','1003','1004','1015','1007','1006','1014']
list_time=['2017','2016','2015','2014','2013','2012','2011','2010','11','90','80','1']
return list_loc,list_type,list_time
def PageCreate():
urlsys=[]
list_loc,list_type,list_time=urlAdd()
for loc in list_loc:
for type_1 in list_type:
for time_1 in list_time:
url1='http://so.tv.sohu.com/list_p1101_p210%s_p3%s_p4%s_p5_p6_p7_p8_p92_p101_p11_p12_p13.html'%(type_1,loc,time_1)
urlsys.append(url1)
return urlsys
def urlsPages(url):
url_hrefs=[]
time.sleep(2+random.uniform(-1,1))
req=urllib.request.Request(url)
req.add_header("Origin","http://so.tv.sohu.com")
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2657.3 Safari/537.36')
resp=request.urlopen(req,timeout=180)
html=resp.read().decode("utf-8")
soup = bs(html, 'lxml')
if soup.find_all(attrs={'title':'下一页'})==[]:
page=1
else:
page=int(soup.find_all(attrs={'title':'下一页'})[-1].find_previous_sibling().string)
for i in range(page):
url_page=url.replace('p101',('p10'+str(i+1)))
time.sleep(2+random.uniform(-1,1))
print('收集页面',url_page)
req=urllib.request.Request(url_page)
req.add_header("Origin","http://so.tv.sohu.com")
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2657.3 Safari/537.36')
resp=request.urlopen(req,timeout=180)
html=resp.read().decode("utf-8")
soup = bs(html, 'html5lib')
hrefs=soup.find_all(attrs={'pb-url':'meta$$list'})
for hreftq in hrefs:
url_href=hreftq.get('href')
url_hrefs.append("http:"+url_href)
return url_hrefs
def getInfo(url):
info=[]
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"
headers={"User-Agent":user_agent,'Referer':"http://tv.sohu.com"}
#time.sleep(2+random.uniform(-1,1))
req=urllib.request.Request(url,headers=headers)
resp=request.urlopen(req,timeout=300)
html=resp.read()
soup = bs(html, 'html5lib')
try:
title=soup.find('span','vname').getText()
plids=soup.script.getText()
match=re.findall('playlistId="(.+)";',plids)[0]
url_json='http://count.vrs.sohu.com/count/queryext.action?callback=playCountVrs&plids='+match
data = urllib.request.Request(url=url_json,headers=headers)
resp=request.urlopen(data,timeout=300).read().decode("utf-8")
total = re.findall(r'(\w*[0-9]+)\w*',resp)[1]
except Exception as e:
print(e,url)
title="missing"
total="missing"
info.append(title)
info.append(total)
print('信息',info)
return info
if __name__ == "__main__":
print('开始')
url_hrefss=[]
urlsys=PageCreate()
print(urlsys)
pool = multiprocessing.Pool(multiprocessing.cpu_count())
url_hrefss.append(pool.map(urlsPages,urlsys))
pool.close()
pool.join()
url_links = list(chain(*url_hrefss))
url_links = list(chain(*url_links))
url_links = [i for i in url_links if i != []]
url_links = list(set(url_links))
print('所有页面',url_links)
url_exp=pd.Series(url_links)
url_exp.to_csv("c:/tv_his_sohu_url_exp.csv")
infos=[]
pool = multiprocessing.Pool(multiprocessing.cpu_count())
infos.extend(pool.map(getInfo,url_links))
print(infos)
sohu_infos=pd.DataFrame(infos)
sohu_infos.to_csv("c:/tv_his_sohu.csv")
最后获取到csv。
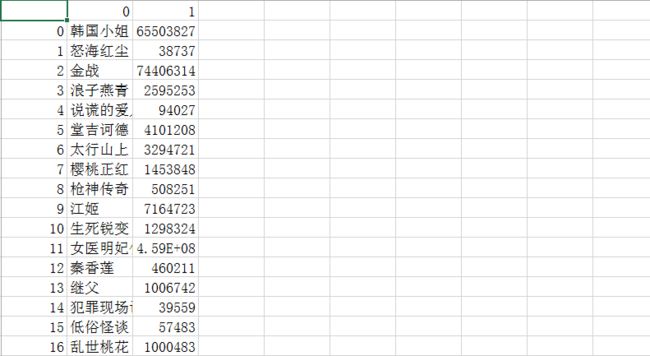
Paste_Image.png