参考内容:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html#Standalone_Operation
如果你想要使用VIM,则如下命令在ubuntu上安装:
$ sudo apt install vim
一、安装Java
说明:后文我用的Java安装路径也有可能在/home/yay/software/java/jdk1.8.0_191,不一定是本例子所述路径
1.1 下载
1.2 准备一个安装目录
yay@10049605-ThinkPad-T470-W10DG:~$ cd /
yay@10049605-ThinkPad-T470-W10DG:/$ sudo mkdir /java
[sudo] yay 的密码:
yay@10049605-ThinkPad-T470-W10DG:/$ cd home/yay/下载
yay@10049605-ThinkPad-T470-W10DG:~/下载$ sudo mv jdk-8u191-linux-x64.tar.gz /java
yay@10049605-ThinkPad-T470-W10DG:~/下载$ cd /java
1.3 解压缩
1.4 配置环境变量
编辑/etc/profile,在最后增加下面几行:
export JAVA_HOME=/java/jdk1.8.0_191
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
最后让它立即生效:
yay@10049605-ThinkPad-T470-W10DG:~$ source /etc/profile
测试:
yay@10049605-ThinkPad-T470-W10DG:~$ java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
yay@10049605-ThinkPad-T470-W10DG:~$
我们也可以打印环境变量,看看是否生效(下面两种方法都可以):
yay@10049605-ThinkPad-T470-W10DG:~$ echo $JAVA_HOME
yay@10049605-ThinkPad-T470-W10DG:~$ env
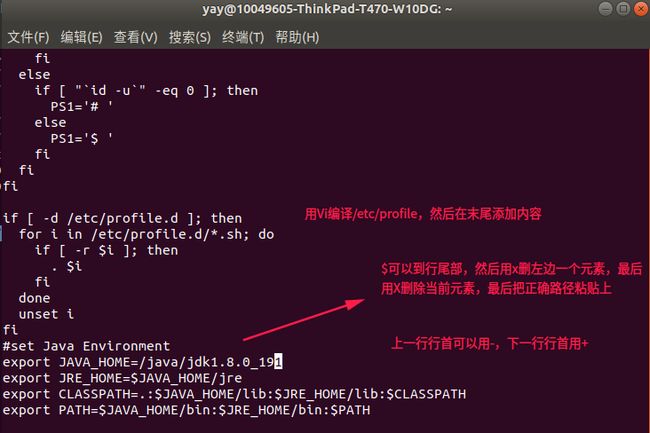
要注意刷新环境变量,使立即生效
二、安装SSH
yay@10049605-ThinkPad-T470-W10DG:~$ sudo apt-get update
yay@10049605-ThinkPad-T470-W10DG:~$ sudo apt-get install ssh
[sudo] yay 的密码:
正在读取软件包列表... 完成
正在分析软件包的依赖关系树
正在读取状态信息... 完成
...........
yay@10049605-ThinkPad-T470-W10DG:~$ sudo apt-get install rsync
正在读取软件包列表... 完成
..........
$ sudo apt-get install pdsh
确保ssh localhost能通。如果不通,则设置免密码登录的ssh,方法如下:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
root@1001836:~# ssh localhost
ssh: connect to host localhost port 22: Connection refused
这中情况下很可能是由于你的ssh没有安装,你可能是由于没有执行 sudo apt-get update
注意当出现下面的一个错误时,我们可能需要配置pdsh,如下:
Starting namenodes on [localhost]
pdsh@yay-ThinkPad-T470: localhost: rcmd: socket: Permission denied
Starting datanodes
pdsh@yay-ThinkPad-T470: localhost: rcmd: socket: Permission denied
Starting secondary namenodes [yay-ThinkPad-T470]
pdsh@yay-ThinkPad-T470: yay-ThinkPad-T470: rcmd: socket: Permission denied
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ sudo echo "ssh" > /etc/pdsh/rcmd_default
-bash: /etc/pdsh/rcmd_default: 权限不够
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ su
密码:
root@yay-ThinkPad-T470:/home/yay/software/hadoop/hadoop-3.2.1# echo "ssh" > /etc/pdsh/rcmd_default
root@yay-ThinkPad-T470:/home/yay/software/hadoop/hadoop-3.2.1#
三、安装Hadoop
3.1 下载
3.2 解压缩
建一个/hadoop文件夹。然后:
yay@10049605-ThinkPad-T470-W10DG:~/下载$ sudo mv hadoop-3.2.1.tar.gz /hadoop
[sudo] yay 的密码:
yay@10049605-ThinkPad-T470-W10DG:~/下载$
yay@10049605-ThinkPad-T470-W10DG:~/下载$ cd /hadoop
yay@10049605-ThinkPad-T470-W10DG:/hadoop$ sudo tar -zxvf hadoop-3.2.1.tar.gz
3.3 Standalone Operation模式运行Hadoop自带的例子
注意单机版运行hadoop自带的例子(即Standalone Operation)不用启动别的东西:
yay@yay-ThinkPad-T470:~$ cd $HADOOP_HOME
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ mkdir input
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ cp etc/hadoop/*.xml input
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
3.4 Pseudo-Distributed Operation模式hadoop的配置
3.4.1 run a MapReduce job locally
3.4.1.1 修改 etc/hadoop/core-site.xml:

fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/home/yay/hadoop_tmp
A base for other temporary directories.
3.4.1.2 修改 etc/hadoop/hdfs-site.xml:

dfs.replication
1
3.4.1.3 配置etc/hadoop/hadoop-env.sh
只需要配置这一行。注意,即使已经在/etc/profile中配置了JAVA_HOME,这里仍然要配置
export JAVA_HOME=/home/yay/software/java/jdk1.8.0_191
3.4.1.4 执行
1 Format the filesystem
yay@yay-ThinkPad-T470:~/software$ hdfs namenode -format

2 Start NameNode daemon 和 DataNode daemon
yay@yay-ThinkPad-T470:~/software$ start-dfs.sh

3 Browse the web interface for the NameNode
接下来就可以查看namenode信息:
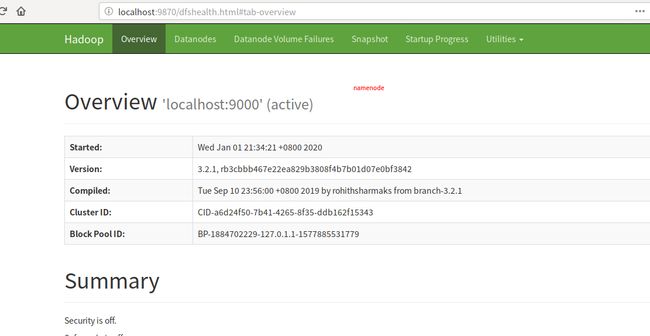
4 创建 HDFS directories required to execute MapReduce jobs
yay@yay-ThinkPad-T470:~/software$ hdfs dfs -mkdir /user
yay@yay-ThinkPad-T470:~/software$ hdfs dfs -mkdir /user/yay
5 准备输入数据并作计算
yay@yay-ThinkPad-T470:~/software$ hdfs dfs -mkdir /user
yay@yay-ThinkPad-T470:~/software$ hdfs dfs -mkdir /user/yay
yay@yay-ThinkPad-T470:~/software$ hdfs dfs -mkdir input
yay@yay-ThinkPad-T470:~/software$ hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml input
yay@yay-ThinkPad-T470:~/software$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'

6 停止namenode和datanode 的demos

3.4.2 YARN on Single Node
execute a job on YARN
1 同Pseudo-Distributed Operation本地模式一样执行这四步骤
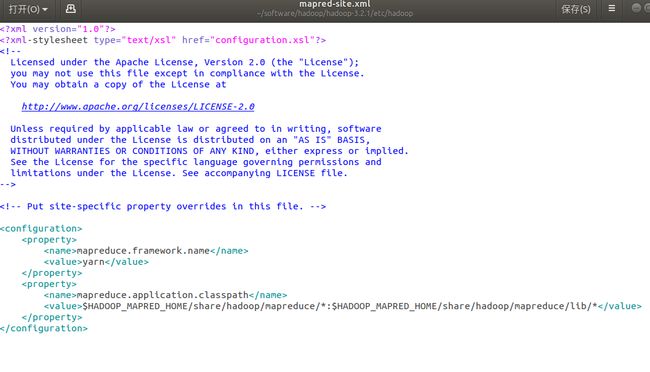
2 配置etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
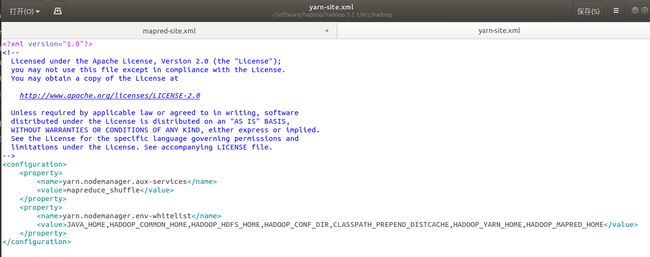
3 配置etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
4 Start ResourceManager daemon and NodeManager daemon

接下来可以查看ResourceManager
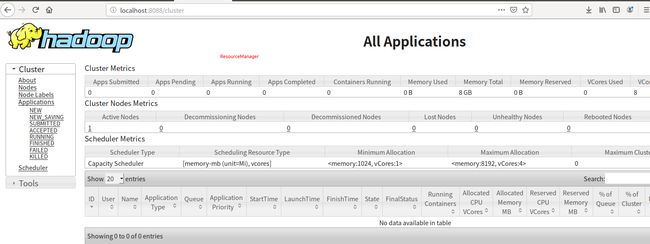
下面这些我最新一次配置实际上都没有用到
3.3 配置hadoop
以下针对Hadoop3
3.3.1 配置etc/hadoop/hadoop-env.sh文件
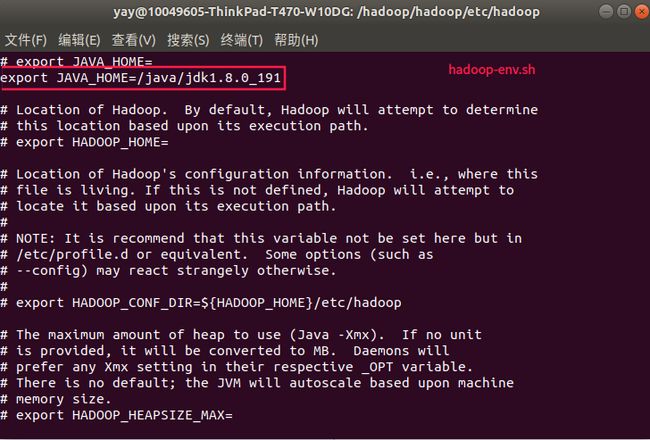
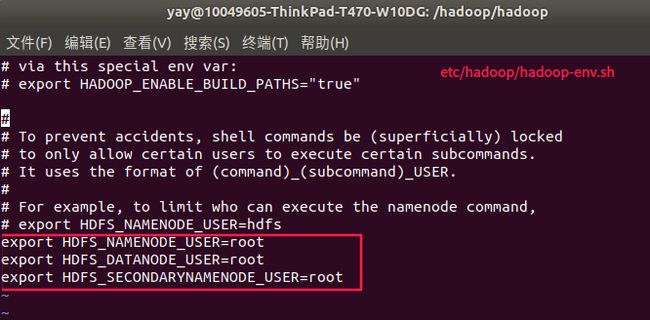
export JAVA_HOME=/java/jdk1.8.0_191
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
3.3.2 在 /etc/profile 中设置环境变量
#在末尾增加下面的内容
#set Java Environment
export JAVA_HOME=/java/jdk1.8.0_191
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
#hadoop 3
export HADOOP_HOME=/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PDSH_RCMD_TYPE=ssh
3.3.3 配置etc/hadoop/core-site.xml
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/home/yay/hadoop_tmp
A base for other temporary directories.
3.3.4 配置etc/hadoop/hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
/hadoop/hadoopdata/name
dfs.datanode.data.dir
/hadoop/hadoopdata/data
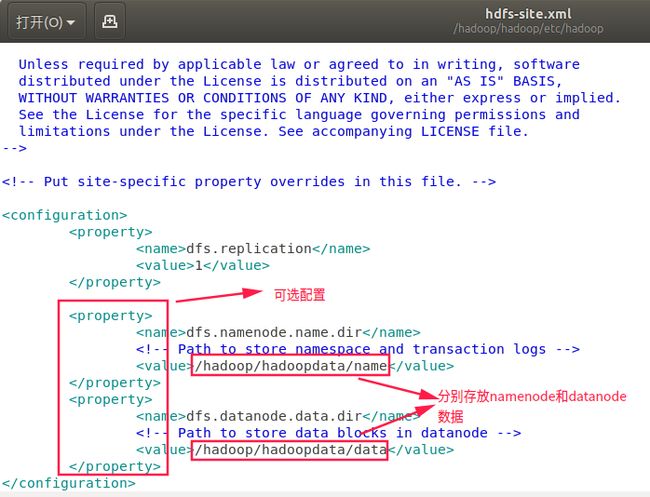
3.3.5 start-yarn.sh和stop-yarn.sh修改
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop/sbin$ sudo cat start-yarn.sh
[sudo] yay 的密码:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
注意开头增加这三行,其余保持不变
stop-yarn.sh也作一样的修改
3.3.5 start-dfs.sh和stop-dfs.sh修改
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3.3.6 Setup passphraseless ssh
root@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
root@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop# chmod 0600 ~/.ssh/authorized_keys
四、启动集群的三种模式
4.1 Standalone Operation模式
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop-2.9.2$ sudo mkdir input
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop-2.9.2$ sudo cp etc/hadoop/*.xml input
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop-2.9.2$ sudo bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar grep input output 'dfs[a-z.]+'
18/12/24 21:05:42 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
18/12/24 21:05:42 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
18/12/24 21:05:42 INFO input.FileInputFormat: Total input files to process : 8
18/12/24 21:05:42 INFO mapreduce.JobSubmitter: number of splits:8
.....
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop-2.9.2$ sudo cat output/*
1 dfsadmin
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop311$ sudo mkdir input
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop311$ sudo cp etc/hadoop/*.xml input
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop311$ sudo bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar grep input output 'dfs[a-z.]+'
2019-01-05 23:31:17,246 INFO impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-01-05 23:31:17,457 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s).
2019-01-05 23:31:17,457 INFO impl.MetricsSystemImpl: JobTracker metrics system started
*****************************************************************
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop311$ cat output/*
1 dfsadmin
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop311$
4.2 Pseudo-Distributed Operation模式
以下针对Hadoop3
4.2.1 配置etc/hadoop/hadoop-env.sh文件
4.2.2 在 /etc/profile 中设置环境变量
#在末尾增加下面的内容
#set Java Environment
export JAVA_HOME=/java/jdk1.8.0_191
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
#hadoop 3
export HADOOP_HOME=/hadoop/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PDSH_RCMD_TYPE=ssh
4.2.3 配置etc/hadoop/core-site.xml
fs.defaultFS
hdfs://localhost:9000
hadoop.tmp.dir
/home/yay/hadoop_tmp
A base for other temporary directories.
4.2.4 配置etc/hadoop/hdfs-site.xml
无须预先生成/hadoop/hadoop/data和/hadoop/hadoop/name目录,他们会被自动创建
dfs.replication
1
dfs.namenode.name.dir
/hadoop/hadoopdata/name
dfs.datanode.data.dir
/hadoop/hadoopdata/data
4.2.5 Setup passphraseless ssh
下面这个我已经设置过了,无须在设置
root@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
root@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop# chmod 0600 ~/.ssh/authorized_keys
4.2.6 run a MapReduce job locally(后面会采用另外一种方式: YARN_on_Single_Node).
这里要作两件事情
- 格式化文件系统
- 启动 NameNode daemon 和 DataNode daemon
//1. 格式化文件系统
yay@10049605-ThinkPad-T470-W10DG:/hadoop/hadoop$ su -
密码:
root@10049605-ThinkPad-T470-W10DG:~# hdfs namenode -format
....................................................
//2. 启动 NameNode daemon 和 DataNode daemon:
root@10049605-ThinkPad-T470-W10DG:~# start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
localhost: datanode is running as process 5299. Stop it first.
pdsh@10049605-ThinkPad-T470-W10DG: localhost: ssh exited with exit code 1
Starting secondary namenodes [10049605-ThinkPad-T470-W10DG]
10049605-ThinkPad-T470-W10DG: secondarynamenode is running as process 5555. Stop it first.
pdsh@10049605-ThinkPad-T470-W10DG: 10049605-ThinkPad-T470-W10DG: ssh exited with exit code 1
root@10049605-ThinkPad-T470-W10DG:~#
4.2.7 查看ResourceManager运行状态
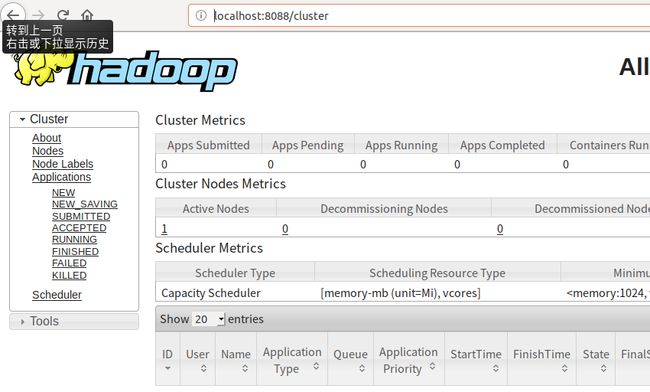
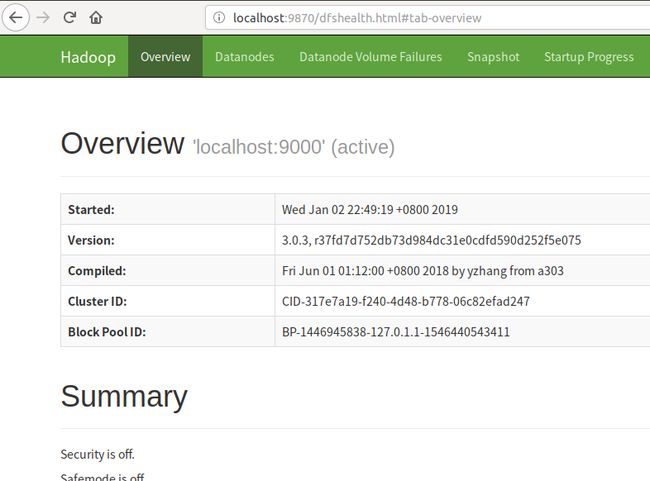
4.2.8 尝试运行一个例子
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -mkdir /userwho
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -mkdir input
mkdir: `input': No such file or directory
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -mkdir /input
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -put /hadoop/hadoop/etc/hadoop/*.xml /input
root@10049605-ThinkPad-T470-W10DG:~# hadoop jar /hadoop/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.3.jar grep /input /output 'dfs[a-z.]+'
......
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -ls /
Found 4 items
drwxr-xr-x - root supergroup 0 2019-01-02 23:04 /input
drwxr-xr-x - root supergroup 0 2019-01-02 23:08 /output
drwxr-xr-x - root supergroup 0 2019-01-02 23:08 /user
drwxr-xr-x - root supergroup 0 2019-01-02 23:00 /userwho
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -cat /output/*
1 dfsadmin
1 dfs.replication
root@10049605-ThinkPad-T470-W10DG:~#
接下来我们可以产看产出的文件(或者直接在HDFS上,或者下载下来看)
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -cat /output/*
1 dfsadmin
1 dfs.replication
root@10049605-ThinkPad-T470-W10DG:~# pwd
/root
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -get /output /output
root@10049605-ThinkPad-T470-W10DG:~# hdfs dfs -cat /output/*
1 dfsadmin
1 dfs.replication
root@10049605-ThinkPad-T470-W10DG:~# cd /
root@10049605-ThinkPad-T470-W10DG:/# dir
bin dev home java lost+found opt root snap sys var
boot etc initrd.img lib media output run srv tmp vmlinuz
cdrom hadoop initrd.img.old lib64 mnt proc sbin swapfile usr vmlinuz.old
root@10049605-ThinkPad-T470-W10DG:/# rm -r output
root@10049605-ThinkPad-T470-W10DG:/#
我在4.2.1上的运行过程如下:
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ su
密码:
root@yay-ThinkPad-T470:/home/yay/software/hadoop/hadoop-3.2.1# echo "ssh" > /etc/pdsh/rcmd_default
root@yay-ThinkPad-T470:/home/yay/software/hadoop/hadoop-3.2.1# exit
exit
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ sbin/start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [yay-ThinkPad-T470]
yay-ThinkPad-T470: Warning: Permanently added 'yay-thinkpad-t470' (ECDSA) to the list of known hosts.
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ bin/hdfs dfs -mkdir /user
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ bin/hdfs dfs -mkdir /user/yay
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ bin/hdfs dfs -mkdir input
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ bin/hdfs dfs -put etc/hadoop/*.xml input
2020-01-01 00:28:44,787 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,432 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,499 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,573 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,646 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,695 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,745 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,803 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-01-01 00:28:45,862 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
yay@yay-ThinkPad-T470:~/software/hadoop/hadoop-3.2.1$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
4.2.9 停止HDFS
root@10049605-ThinkPad-T470-W10DG:/# stop-dfs.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [10049605-ThinkPad-T470-W10DG]
root@10049605-ThinkPad-T470-W10DG:/#
4.2.10 在YARN上运行Mapeduce
1. 首先需要在start-yarn.sh和stop-yarn.sh中顶部增加下面内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
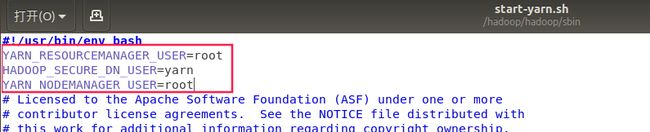
2. 修改etc/hadoop/mapred-site.xml 内容
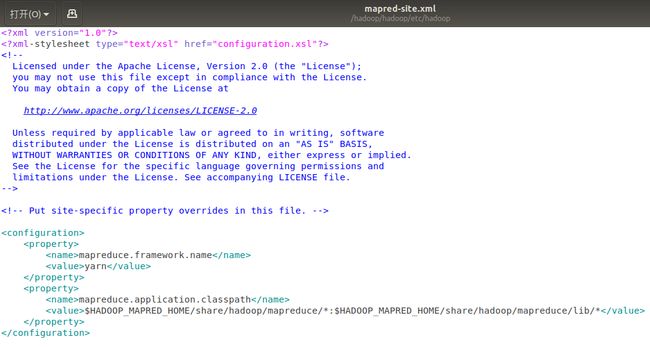
3. 启动yarn并查看监控数据

注意: