Trie 又称作字典树、前缀树。
Trie 的结构
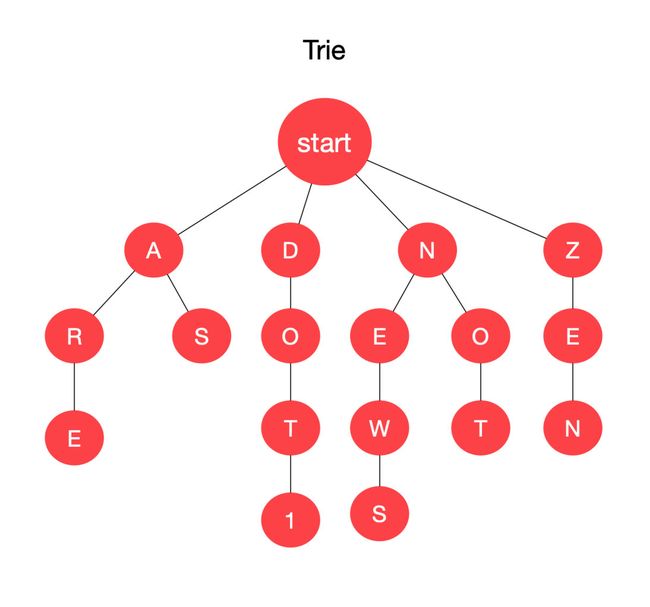
1、Trie 的设计很巧妙,它不像一般的字典那样,把一整个单词存在数据结构里。Trie 利用单词的前缀去匹配一棵树,能匹配上,则说明这个字典里有这个单词;
2、Trie 的结构有那么一点点像链表,只不过链表的 next 指针指向的是一个 Node 结点,而 Trie 的 next 指针指向的是一个 Map;
3、Trie 本身携带的内容仅仅只是 isWord 这样一个布尔型变量,而沿着 next 指针一路走下来的路径,就能表示一个单词。
下面是一个 Trie 树的基本结构:
Java 代码:
import java.util.TreeMap;
public class Trie {
private class Node {
// isWord 表示沿着根结点往下走,走到这个结点的时候是否是一个单词的结尾
public boolean isWord;
// 因为这里不涉及排序操作,用哈希表也是可以的
public TreeMap next;
public Node(boolean isWord) {
this.isWord = isWord;
next = new TreeMap<>();
}
public Node() {
this(false);
}
}
private Node root;
private int size;
public Trie() {
root = new Node();
size = 0;
}
public int getSize() {
return size;
}
}
Trie 的添加操作
Java 代码:
public void add(String word) {
// root 是当前 Trie 对象的属性
Node currNode = root;
for (int i = 0; i < word.length(); i++) {
Character c = word.charAt(i);
if (currNode.next.get(c) == null) {
currNode.next.put(c, new Node());
}
currNode = currNode.next.get(c);
}
// 如果已经添加过,才将 size++
if (!currNode.isWord) {
currNode.isWord = true;
size++;
}
}
Trie 的查询操作
1、理解 Trie 的查询只与待查询的字符串的长度有关;
2、下面这个方法查询整个单词在 Trie 中是否存在,所以在路径匹配完成以后,一定不要忘了判断匹配到的那个结点的 isWord 属性,如果它是一个单词的结尾,才返回 True。
Java 代码:
// 基于 Trie 的查询
public boolean contains(String word){
Node currNode = root;
Character currC;
for (int i = 0; i < word.length(); i++) {
currC = word.charAt(i);
if(currNode.next.get(currC)==null){
return false;
}
currNode = currNode.next.get(currC);
}
return currNode.isWord;
}
Trie 的前缀查询操作
前缀查询就更简单了,此时不需要判断 isWord 属性的值,只需要判断从树的根结点是不是很顺利地都能匹配单词的每一个字符。
Java 代码:
// 是否有某个前缀
public boolean isPrefix(String prefix) {
Character c;
Node currNode = root;
for (int i = 0; i < prefix.length(); i++) {
c = prefix.charAt(i);
if (currNode.next.get(c) == null) {
return false;
}
currNode = currNode.next.get(c);
}
// 只需要判断从树的根结点是不是很顺利地都能匹配单词的每一个字符
// 所以,能走到这里来,就返回 True
return true;
}
例题:LeetCode 第 208 题:Implement Trie (Prefix Tree)
传送门:英文网址:208. Implement Trie (Prefix Tree) ,中文网址:208. 实现 Trie (前缀树) 。
实现一个 Trie (前缀树),包含
insert,search, 和startsWith这三个操作。示例:
Trie trie = new Trie(); trie.insert("apple"); trie.search("apple"); // 返回 true trie.search("app"); // 返回 false trie.startsWith("app"); // 返回 true trie.insert("app"); trie.search("app"); // 返回 true说明:
- 你可以假设所有的输入都是由小写字母
a-z构成的。- 保证所有输入均为非空字符串。
分析:这道问题要求我们实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。其实就是我们上面列出的“添加”、“查询”、“前缀查询”操作。
Python 代码:
class Trie(object):
class Node:
def __init__(self):
self.is_word = False
self.dict = dict()
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = Trie.Node()
def insert(self, word):
"""
Inserts a word into the trie.
:type word: str
:rtype: void
"""
cur_node = self.root
for alpha in word:
if alpha not in cur_node.dict:
cur_node.dict[alpha] = Trie.Node()
# 这里不要写成 else ,那就大错特错了
cur_node = cur_node.dict[alpha]
if not cur_node.is_word:
cur_node.is_word = True
def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
:rtype: bool
"""
cur_node = self.root
for alpha in word:
if alpha not in cur_node.dict:
return False
else:
cur_node = cur_node.dict[alpha]
return cur_node.is_word
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
:type prefix: str
:rtype: bool
"""
cur_node = self.root
for alpha in prefix:
if alpha not in cur_node.dict:
return False
else:
cur_node = cur_node.dict[alpha]
return True
说明:其实很简单,多写几遍也就熟悉了。
Trie 字典树和简单的模式匹配
例1:LeetCode 第 211 题: Add and Search Word - Data structure design
传送门:英文网址:211. Add and Search Word - Data structure design,中文网址:211. 添加与搜索单词 - 数据结构设计 。
设计一个支持以下两种操作的数据结构:
void addWord(word) bool search(word)search(word) 可以搜索文字或正则表达式字符串,字符串只包含字母
.或a-z。.可以表示任何一个字母。示例:
addWord("bad") addWord("dad") addWord("mad") search("pad") -> false search("bad") -> true search(".ad") -> true search("b..") -> true说明:
你可以假设所有单词都是由小写字母
a-z组成的。
Python 代码:
class WordDictionary(object):
class Node:
def __init__(self):
self.is_word = False
self.dict = dict()
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = WordDictionary.Node()
def addWord(self, word):
"""
Adds a word into the data structure.
:type word: str
:rtype: void
"""
cur_node = self.root
for alpha in word:
if alpha not in cur_node.dict:
cur_node.dict[alpha] = WordDictionary.Node()
cur_node = cur_node.dict[alpha]
if not cur_node.is_word:
cur_node.is_word = True
def search(self, word):
"""
Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter.
:type word: str
:rtype: bool
"""
# 注意:这里要设置辅助函数
return self.match(self.root, word, 0)
def match(self, node, word, index):
if index == len(word):
return node.is_word
alpha = word[index]
if alpha == '.':
for next in node.dict:
if self.match(node.dict[next], word, index + 1):
return True
# 注意:这里要返回
return False
else:
# 注意:这里要使用 else
if alpha not in node.dict:
return False
# 注意:这里要使用 return 返回
return self.match(node.dict[alpha], word, index + 1)
Trie 字典树和字符串映射
例2:LeetCode 第 677 题:Map Sum Pairs
传送门:英文网址:677. Map Sum Pairs ,中文网址:677. 键值映射 。
实现一个 MapSum 类里的两个方法,
insert和sum。对于方法
insert,你将得到一对(字符串,整数)的键值对。字符串表示键,整数表示值。如果键已经存在,那么原来的键值对将被替代成新的键值对。对于方法
sum,你将得到一个表示前缀的字符串,你需要返回所有以该前缀开头的键的值的总和。示例 1:
输入: insert("apple", 3), 输出: Null 输入: sum("ap"), 输出: 3 输入: insert("app", 2), 输出: Null 输入: sum("ap"), 输出: 5
分析:使用 Trie 单词查找树这个数据结构来完成,将原来的 isWord 设计成 value 它不但可以表达原来 isWord 的含义,还能表示题目中一个单词携带的整数的含义。
首先先把前缀遍历完,如果前缀都不能遍历完成,就说明单词查找树中不存在以这个单词为前缀的单词,应该返回 0,否则以一个结点为根,循环遍历到所有叶子节点,途径的所有 value 值都应该加和到最终的结果里。
计算 sum 设计成一个递归方法,递归方法几行就完成了计算,虽然没有显式地写出递归终止条件,但递归终止条件已经包含在方法体中了。
Python 代码:
class MapSum(object):
class Node:
def __init__(self):
self.val = 0
self.dict = dict()
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = MapSum.Node()
def insert(self, key, val):
"""
:type key: str
:type val: int
:rtype: void
"""
cur_node = self.root
for aplha in key:
if aplha not in cur_node.dict:
cur_node.dict[aplha] = MapSum.Node()
cur_node = cur_node.dict[aplha]
cur_node.val = val
def sum(self, prefix):
"""
:type prefix: str
:rtype: int
"""
cur_node = self.root
for alpha in prefix:
if alpha not in cur_node.dict:
return 0
cur_node = cur_node.dict[alpha]
return self.presum(cur_node)
def presum(self, node):
"""
计算以 node 为根结点的所有字符串的和
:param node:
:return:
"""
s = node.val
for next in node.dict:
s += self.presum(node.dict[next])
return s
参考资料
1、subetter 的文章《字典树》
https://subetter.com/algorithm/trie-tree.html
LeetCode 第 208 题: Implement Trie (Prefix Tree)
LeetCode 第 211 题 :Add and Search Word - Data structure design
LeetCode 第 677 题:Map Sum Pairs
LeetCode 第 745 题:前缀和后缀搜索
传送门:前缀和后缀搜索
给定多个
words,words[i]的权重为i。设计一个类
WordFilter实现函数WordFilter.f(String prefix, String suffix)。这个函数将返回具有前缀prefix和后缀suffix的词的最大权重。如果没有这样的词,返回 -1。例子:
输入: WordFilter(["apple"]) WordFilter.f("a", "e") // 返回 0 WordFilter.f("b", "") // 返回 -1注意:
words的长度在[1, 15000]之间。- 对于每个测试用例,最多会有
words.length次对WordFilter.f的调用。words[i]的长度在[1, 10]之间。prefix, suffix的长度在[0, 10]之前。words[i]和prefix, suffix只包含小写字母。
LeetCode 第 720 题:词典中最长的单词
传送门:词典中最长的单词。
给出一个字符串数组
words组成的一本英语词典。从中找出最长的一个单词,该单词是由words词典中其他单词逐步添加一个字母组成。若其中有多个可行的答案,则返回答案中字典序最小的单词。若无答案,则返回空字符串。
示例 1:
输入: words = ["w","wo","wor","worl", "world"] 输出: "world" 解释: 单词"world"可由"w", "wo", "wor", 和 "worl"添加一个字母组成。示例 2:
输入: words = ["a", "banana", "app", "appl", "ap", "apply", "apple"] 输出: "apple" 解释: "apply"和"apple"都能由词典中的单词组成。但是"apple"得字典序小于"apply"。注意:
- 所有输入的字符串都只包含小写字母。
words数组长度范围为[1,1000]。words[i]的长度范围为[1,30]。
分析:排序,利用字典树,将单词压入字典树中,先判断该单词的前 个字符在字典树中是否存在,
不存在直接跳出,该单词不需要压入,然后我们将第 个字符压入字典树中,并更新当前最长且字典序最小的单词。

Python 无排序版本:
class Solution:
def longestWord(self, words):
"""
:type words: List[str]
:rtype: str
"""
# 放到 set 里面,重复的去掉了,而且可以很快查到前缀是否有
# 字典树效果更好
word_set = set(words)
res = ''
for word in words:
# 默认有,只要有一个没有,就可以退出循环了
has_pre = True
for i in range(1, len(word)):
if word[:i] not in word_set:
has_pre = False
break
if has_pre:
if not res or len(word) > len(res):
res = word
elif len(word) == len(res) and res > word:
res = word
return res
if __name__ == '__main__':
words = ["a", "banana", "app", "appl", "ap", "apply", "apple"]
solution = Solution()
result = solution.longestWord(words)
print(result)
Java 代码:使用 Set ,本质上是一个自定义排序的过程,这里的 Set 用哈希表,是为了判断前缀是不是存在,哈希表其实可以换成 Trie,速度更快
Java 代码:重点理解为什么从后向前,这一点很关键
import java.util.Arrays;
import java.util.Comparator;
import java.util.HashSet;
import java.util.Set;
/**
* 参考资料:https://www.youtube.com/watch?v=BpkEnyfJUag
*/
public class Solution {
public String longestWord(String[] words) {
int len = words.length;
if (len == 0) {
return "";
}
Set dict = new HashSet<>();
for (int i = 0; i < len; i++) {
dict.add(words[i]);
}
Comparator comparator = new Comparator() {
@Override
public int compare(String o1, String o2) {
int len1 = o1.length();
int len2 = o2.length();
if (len1 != len2) {
return len1 - len2;
}
// 注意这里的顺序
return o2.compareTo(o1);
}
};
Arrays.sort(words, comparator);
// System.out.println(Arrays.toString(words));
// 从后向前遍历
for (int i = len - 1; i >= 0; i--) {
if (judgeWordInDict(words[i], dict)) {
return words[i];
}
}
return "";
}
private boolean judgeWordInDict(String word, Set dict) {
int len = word.length();
for (int i = 0; i < len - 1; i++) {
if (!dict.contains(word.substring(0, i + 1))) {
return false;
}
}
return true;
}
public static void main(String[] args) {
String[] words = {"a", "banana", "app", "appl", "ap", "apply", "apple"};
Solution solution = new Solution();
String longestWord = solution.longestWord(words);
System.out.println(longestWord);
}
}
说明:针对题目中给出的例子,打印输出:
[a, ap, app, appl, apply, apple, banana]
apple
可以帮助理解解决问题的思路。
下面这篇博文给出了一个比较好理解的 Trie 树解决的方法:
https://www.cnblogs.com/bonelee/p/9256217.html
下面给出一个不太好理解的使用 Trie 的版本。
Python 代码:
class Node:
def __init__(self, key, is_end=False):
self.key = key
self.children = {}
self.is_end = is_end
class Trie:
def __init__(self):
self.root = Node('')
self.root.is_end = True
def insert(self, word):
node = self.root
for alpha in word:
if alpha not in node.children:
node.children[alpha] = Node(alpha)
node = node.children[alpha]
node.is_end = True
class Solution:
def longestWord(self, words):
"""
:type words: List[str]
:rtype: str
"""
trie = Trie()
for word in words:
trie.insert(word)
return ''.join(self.__get_word(trie.root))
def __get_word(self, node):
if not node.is_end:
return []
if not node.children:
return [node.key]
li = [self.__get_word(c) for c in node.children.values()]
n = len(max(li, key=len))
li = [i for i in li if len(i) == n]
li.sort()
return [node.key] + li[0]
本文源代码
Python:代码文件夹,Java:代码文件夹。
(本节完)