
加密与解密 Encryption & Decryption
古典密码学
起源:古代战争 - 古典密码学,为防止「信使」被敌方掳获获得我方情报,诞生了最初代的古典密码学,其代表加密工具就为 - 密码棒,如下图:

密码棒的规格是严格定制的,发情报的一方和收情报的一方是一一对应的,如上图中每一面都是对应的加密信息。
加密的意义不在于信息不被侵犯,而在于被侵犯获取后不被破解。
其实,密码棒中就已经包含了密码学最重要的两个因素:加密算法和密钥,在密码棒中,加密算法即为缠绕方式,密钥则是木棒的规格。
古典密码学加密方式分为:移位式加密和替换式加密,密码棒就属于典型的移位式加密,而替换式加密的代表就是替换文字加密,如:
发送方需要发送的是 Christina Aguilera,加密规则为:每个字符都替换成它的下一位,于是密文就变成了:
Disjtujob Bhvjmfsb
在此过程,加密算法则为:替换文字,密钥为:码表(表示信息和加密后的密文一一对应的映射关系)。当双方都拿着一样的码表便可以进行通信了。
现代密码学
当计算机发展高速的时候,这些加密的思想便应用到计算机领域当中,一些高深复杂的数学知识可以完美的应用到加密算法中,这样得到的密文很难破解。于是,诞生了现代密码学,现代密码学不止用于文字,还可以用于二进制数据。
现代密码学的加密方式同样分为两种:对称加密和非对称加密,对称加密和移位式加密很像,但是要复杂得多。
对称加密
对称加密的原理:使用密钥和加密算法对数据进行转换,得到的无意义数据即为密文;使用解密算法和密钥进行逆向转换,得到原数据。
经典算法:DES(密钥太短容易被破解被弃用)、AES。
一个优秀的加密算法是让破解方使用穷举法(在此通俗理解就是破解方把可能性范围内所有的密钥去破解的这种暴力破解方法)才能破解的算法,也就是指花费破解方时间成本最高、精力成本最高的算法。当破解时间达到一个很大的值如 1000 年、10000 年则可认为该密文不能破解,在计算机发展的今天 AES 可以满足对称加密需求,在未来的一段时间内,硬件的不断更新迭代,计算的速度越来越大,AES 的密钥必定不能满足对称加密需求。
非对称加密
非对称加密原理:使用公钥对数据进行加密得到密文;使用私钥数据即行解密得到原数据
非对称加密相对对称加密的优点是:密钥可以放心的在网络之间传输。对称加密的传输过程中,一旦密钥被截取,那么本次传输也就不再安全。
非对称加密的通信过程如下:
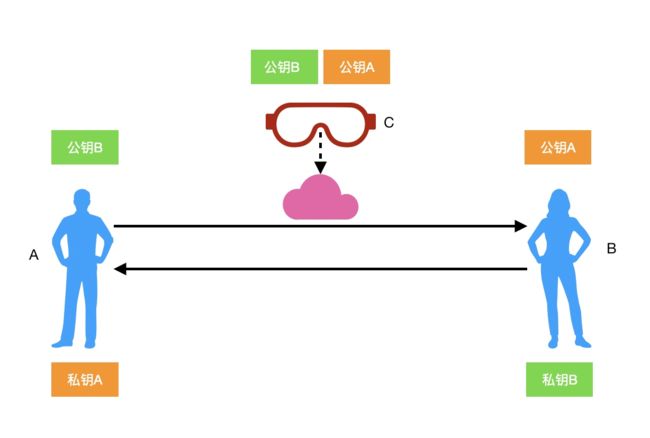
在传输前 A、B 双方会得到对方的公钥,当 A 给 B 发信息的时候,会先用 B 的公钥进行加密,B 收到 A 的密文拿着自己的私钥解密得到原始数据,B 给 A 发信息同样如此,加入通信过程中 C 截获了消息,并且截获了公钥 A 和公钥 B,他是没有办法破解原始数据的,因为解密的关键私钥 A 和私钥 B 在 A、B 双方安全的保存。
私钥能解公钥,公钥亦能解私钥,但是公钥和私钥不能置换使用,因为很多时候公钥是根据私钥计算出来的,如应用在比特币身上的加密算法-椭圆曲线算法中公钥就是根据私钥计算的,假设公私钥置换使用,破解方截获了私钥,也就意味着破解方同时拥有了公钥和私钥。
⚠️上述过程中,同样有潜在的不安全问题在,当 C 截获了公钥 A 和公钥 B 的时候,C 是可以伪造 A 的身份(因为他有公钥 B)与 B 进行通信,那么这个问题该如何解决?签名就发挥作用了。
签名与验证
非对称加密一个很重要的延伸用途:数字签名。
签名与验证的过程
签名和验证的意义就在于:
要让别人知道,这则消息是「我」本人发出的。也就是说「我」用「我」的私钥加密了信息,别人拿着「我」的公钥能还原信息并能确认是「我」本人的信息。就好比一张欠条,别人一看就能知道,是我本人亲自签署的。这时候,「签署」和「签名」有着相同的意味。加密和验证的过程如下图:
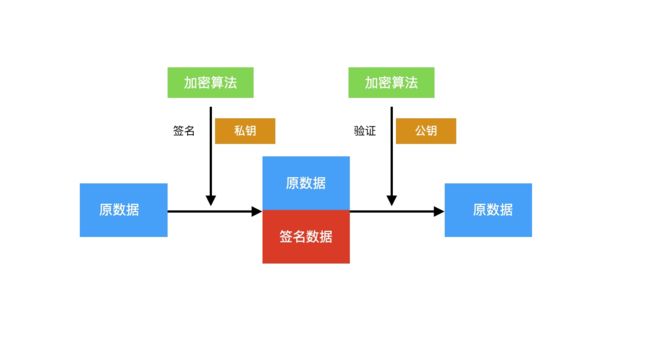
与加密相反的是,签名是用私钥签名,然后对方通过公钥验证,而加密则是原数据通过对方公钥加密,对方通过手中的私钥解密得到原数据。
签名过程通常会携带原数据,方便验证方通过公钥得到的原数据和携带的原数据进行对比从而得到验证结果。
签名 + 加密
过程如下图:
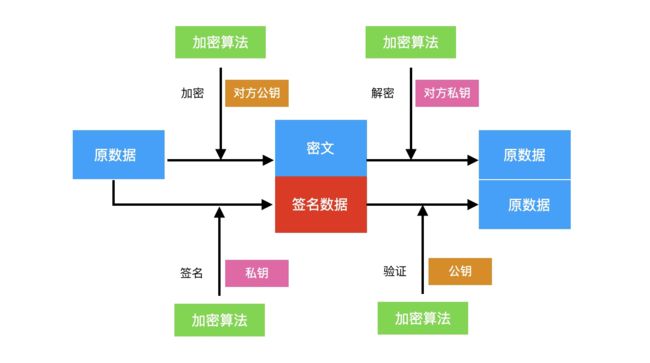
原数据会使用对方公钥进行加密得到密文,同时需要身份验证,所以要使用私钥加密得到签名数据,最终得到密文+签名数据就是签了名的加密数据。
上一节 ⚠️ 部分中一个安全隐患,就可以通过加密+签名的机制来解决,当 B 拿到数据后通过解密和验证后可得知该消息是否真的来自 A。
非对称加密的经典算法:RSA 和 DSA,DSA 专门用来签名,而 RSA 签名加密解密都可以。
DSA 设计方式特殊,它的签名和验证过程非常之快,所以只用来签名。椭圆曲线算法就属于 DSA。
--
同样的,一个优秀的非对称加密算法同样是破解方只能通过「穷举法」去破解。
密码学密钥和登录密码
二者除了有个“密”字没有任何关系。
- 密钥(Key):用于加密和解密,属于数学的领域,目的是保证数据被盗时不被人看懂;
- 登录密码(Password):用于用户的身份验证,不需要任何数学方面的计算和证明,目的是为了给服务方提供「你是你」的证明。
编码与解码 Encoding & Decoding
Base64
Base64 是什么?
它是将二进制数据转换成 64 个字符组成的字符串的编码算法。
什么是二进制数据?
非文本数据就是二进制数据,广义的计算机数据都是二进制数据。
Base64 转换
Base64 的码表:
| Index | Char | Index | Char | Index | Char | Index | Char |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
Base64 有 64 个字符可表示内容,其中每一个字符都要对应上述码表中的一个数,2 的 6 次方是 64,如超出 6 位,该码表就无法表达内容,故划分 6 个 Bits 为一个单元。
下面的例子,「Man(ASCII 编码)」:
M 的二进制数据为:01001101;
a 的二进制数据为:01100001;
n 的二进制数据为:01101110。
每个字母的二进制数据 6 个为一组,得到
M:010011 + 01;
a:011000 + 01;
n:011011 + 10。
M 的前六位的十进制为 19,19 对应上述码表 T,剩下两位和 a 的前四位组合转化成十进制为得到 22 对应 W,a 的后四位和 n 的前两位组合转换十进制为 5 对应 F,n 的后六位对应 u。
所以对「Man」进行 Base64 转码得到 TWFu,由此可见 Base64 转化后的数据明显「增大了」,由 3 个变成了 4 个,那么为什么不选用 Base256 也就是 2 的 8 次方表示呢?因为常见的字符合集不够 256 个,无法满足需求。
**Base64 的用途:
- 让原数据具有字符串所具有的特性,如可以放在 URL 中传输、可以保存文本文件等;
- 人眼无法识别,降低头盔风险。**
Base64 加密传输图片,可以更高效更安全?
安全只能靠加密保证,Base64 不具备加密效果,没有任何安全性可言;高效也是错的,通过 Base64 编过的数据已经变大了很多,延长了传输时间,反而降低了效率。
Base58
Base64 的变种,去掉了 Base64 种 0 和大写 O,小写 l 和小写 I 以及 + 和 /,Base58 主要用在比特币(或其他币)领域的地址上,该地址可能被手抄,那么 0 和 O以及 l 和 I 会造成混淆,至于去掉 + 和 / 是为了方便双击复制。
Base64 的重要应用
URL encoding:将 URL 中的保留字符使用 % 进行编码。
为什么使用 % 的特定编码方式?原因在下。
示例:当在地址栏中输入 https://facebook.com/张雷克斯 (这是一个不存在的网页),浏览器会显示:
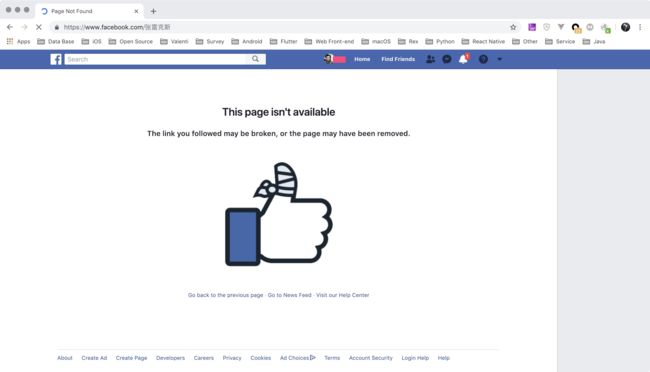
当把地址栏的地址拷贝到一个文本编辑器中的时候会变成:https://www.facebook.com/%E5%BC%A0%E9%9B%B7%E5%85%8B%E6%96%AF 这样的结果。
中文的部分变成了看不懂的字符,那是因为浏览器不支持显示中文继而转换成其他字符,另,「/」和「+」在 URL 中有特定的含义,为了消除歧义选择了 % 编码,能避免分析错误。
压缩与解压缩 Compression & Decompression
压缩:把数据换一种方式来存储,以减小存储空间。
解压缩:将压缩后的数据还原。
常见的压缩算法:DEFLATE、JPEG、MP3
zip 的归档方式使用的压缩算法就是 DEFLATE,JPEG 就是对图片处理的压缩算法,MP3 则为对音频处理的压缩算法。
压缩属于编码吗?
要弄清楚这个问题首先要明白编码到底是什么?其实,编码没有实际的定义,但通俗来理解,就是从一个格式转换成另一个格式并且可以转回来,在转换的过程中不丢失信息不增加信息,这个过程叫编码,所以压缩是完全属于编码。
媒体数据的编码
图片的编码:把图像数据写成 JPG、PNG 等文件的编码格式。
图片的解码:把 JPG、PNG 等文件中的数据解析成标准的图像数据。
音视频的编解码同理。
媒体文件中还存在有损压缩,但不妨碍对媒体数据的解读。
序列化 Serialization
序列化:把数据对象(一般是内存中的,如 JVM 中的对象)转换成字节序列的过程。
反序列化:把字节序列重新转换成内存中的对象。
通俗点说,序列化的过程就是将内存中的数据转换成可以存储的线性的格式,如 JSON 格式、xml 格式。目的是让内存中的对象可以与外界通信(存储、传输)。
序列化属于编码吗?
严格来说,编码是两个不同的格式互相转换,而序列化是内存中的数据转换成可通信的格式。但广义上来说也属于编码。
哈希 Hash
定义:把任意数据转换成制定大小范围(通常很小)的数据。
作用:摘要、数字指纹。
计算机领域当中的某个数据可能非常大,我们在描述它的时候不希望将整个的数据进行描述,而是通过一个指代它的很小的字节就可以描述。这就是 hash 值的作用。
经典算法:MD5、SHA1、SHA256等。
优秀的 Hash 算法是计算出的结果之间不会碰撞,即碰撞率极低。
实际用途:
- 数据完整性验证;如下载某个开源包或者某个安装包时,发布方都会提供一个或多个 hash 值,下载后对下载文件计算 hash 值,如果和发布方的相同则表示是完整的。
- 快速查找:hashCode() 和 HashMap;
- 隐私保护。
Java 开发中通常在重写 equals() 方法的同时要重写 hashCode(),为什么?
假如有 Singer 类:
class Singer{
int age;
String name;
public boolean equals(Object obj) {
return age == obj.age && name.equals(obj.name);
}
}
public long hashCode() {
return age + name.length() // 简单的 hash code
}
hashCode 是用来做身份验证和识别的,在 hashCode() 中有 N 多的方法可以提高该对象 hash 值的唯一性。hashCode 直接影响 HashMap、HashSet 等的内存地址定位。
HashMap 的对象是根据 Key 的 hash code 来获取对应 Value。当 Singer 类的 hashCode() 方法重写的不严谨时,算出的 hash code 是一个非常简单的值会导致两对象的 Key 指向同一个 Value,修改 A 后再修改会 B 会把 A 的 Value 替换掉。
所以重写 hashCode() 后与 HashMap 等相关的操作才能正常使用,使用 hashCode() 性能会比较好。
为什么需要同时写呢?因为 hash code 只是简单的对对象进行比对,并不会比对两个对象属性的具体信息。假如没重写 hashCode() 方法,会调用其父类默认的 hashCode() 方法,这会导致调用 equals() 方法比对两对象不相等但比对 hashCode() 方法的结果的时候相等。
重写并严谨的重写两个方法可以大大提升开发效率。
⚠️ Hash 不是编码,是单向的,不能够还原。
⚠️ Hash 不是加密,MD5 亦不是加密。
Hash 和非对称加密
在非对称加密传输过程中,一个文件的大小约在 10G 左右,那么通过加密算法签名后的签名数据也为 10G 左右,再加上需要验证的原数据则一共为 20G,数据太过臃肿,在实际生活中,签名的过程为:先对原数据进行哈希,再对哈希值签名。完整的过程为:

字符集 Charset
含义:一个由整数向现实世界中符号的 Map。
分支:
- ASCII: 128 个字符,1 字节;
- ISO-9885-1: 对 ASCII 的扩充,1 字节;
- Unicode: 13 万个字符,多字节,UTF-8/UTF-16 是他的编码分支;
- GB 系列: 中国自研标准,多字节。