传统分布式算法
传统的分布式算法通常是采用hash取模的方式来处理数据与服务器节点的映射关系。
举个栗子
假设有个图片为test.jpg,现在有3个服务器,我们称之为0服务器、1服务器、2服务器。首先我们对这张图片进行hash,可以拿到一个散列值,用散列值对3进行取模,取模结果为0或者1或者2。如果结果是0则将图片存入0服务器节点上,如果是1则存入1服务器节点,如果是2则存入2服务器节点。

按照上述的方式,此时假设我们有4个redis节点,分别是redis0、redis1、redis2、redis3。有20个数据,这20个数据的hash结果分别为1-20。然后对4进行取模,取模的结果就是对应数据存储的redis节点。最终数据的分配情况如图所示。

项目运行时我们发现redis节点不够用了,所以新增了一个节点,或者是说发现redis集群负载非常低,我们可以删除一个节点来节省资源。现在的场景是增加了一个节点,我们重新将这20个数据进行取模放置到5个redis节点中。
如图,其中1、2、3、20这四个数据在4个redis节点和5个redis节点中存储的服务器是一样的。所以新增了一个redis节点之后还能获取到这4个数据,因为存储位置没有发生变化。

结论
20个数据在新增了一个服务器节点后只有4个数据命中,命中率是:4/20 = 20%。
当然这里只是举例,实际生成环境数据量可能是百万级、千万级,在实际的生产环境中可能对cache节点会有所调整,比如删除一个cache节点,增加一个cache节点。那么使用传统的hash算法取模的方式将会对后台服务器造成巨大的冲击。很多缓存都没有命中,如果你的业务代码是穿透型的,那就会穿过cache直击db,很容易把数据库搞垮。接下来就看一下Consistent hashing一致性算法的精髓所在。
Consistent hashing
一致性hash算法,Consistent hashing算法早在1997年就在论文《Consistent hashing and random trees》提出。
设计目标是为了解决因特网中的热点(Hot spot)问题,现在一致性hash算法在分布式系统中也得到了广泛应用。
环形hash空间
通常hash算法都是将value映射在一个32位的key值当中。而一致性哈希则将整个哈希值空间组织成一个虚拟的圆环,取值范围是从0-2^32-1(即哈希值是一个32位无符号整形)。
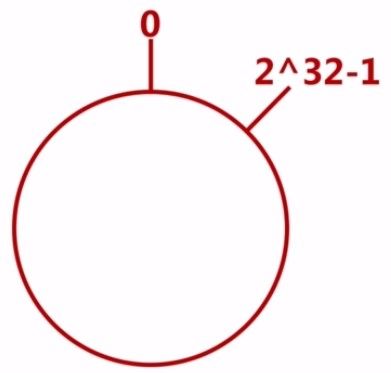
把对象映射到hash空间
这里的对象就是我们真实存储的数据,以4个为例,分别为object1~object4。通过hash函数计算出hash值,分别为key1~key4,这四个值肯定会落在环形hash空间上。
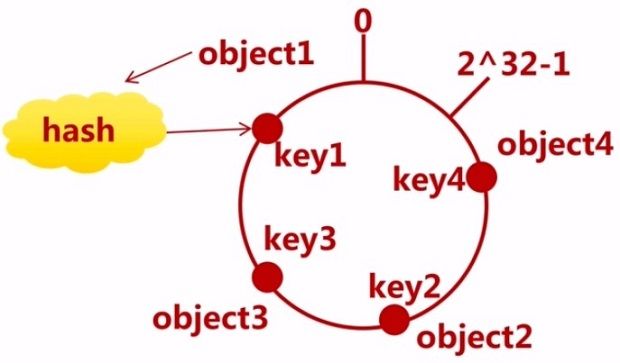
把cache映射到hash空间
基本思想就是将对象和cache都映射到同一个hash数值空间中,并且使用相同的hash算法。即hash(cache A)=key A;
cache就是实际的缓存服务器节点,以3个为例,对cache的hash计算一般的方法可以使用cache的机器的IP地址或者机器名作为hash输入,也可以引入更多的因子,比如端口号等。最终cache通过同一个hash算法也落在对象所在的相同的环形hash空间上。
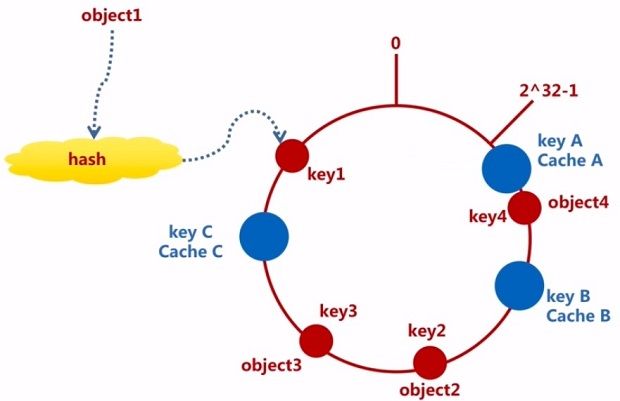
把对象映射到cache
接下来就是要考虑如何把对象映射到cache上,具体的做法就是找到对象所在环形空间的位置,顺时针出发,碰到的第一个cache节点就作为该对象的存储节点。因为对象的hash和cache的hash都是固定的,因此某个对象存储的cache必然是唯一并且确定的。这样就找到了数据映射到cache的一个方案(如图虚线箭头所示)。
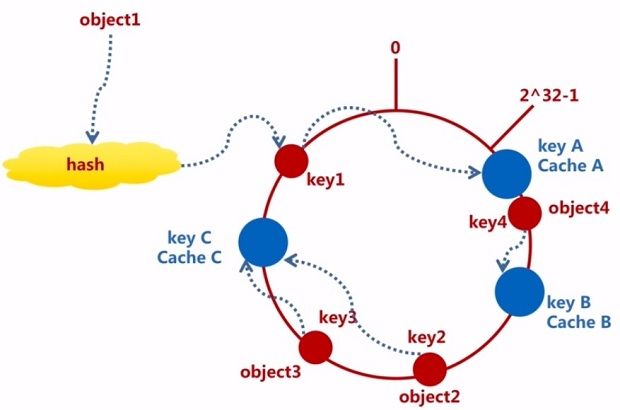
移除Cache
在实际的生产环境中通常对cache节点会有所调整,我们来看下一致性哈希算法是如何处理的。
比如我们移除cache B,此时只有object4无法命中,但是还是可以通过这个算法继续找到新的cache节点cache C,object4就会存储到cache C上。所以对于移除cache B来说,它影响的范围仅仅是它和逆时针到达的第一个cahce节点即cache A之间的数据(如图所示的透明区域),对于环形的其他数据节点都不会影响,影响范围是非常小的。

添加Cache
比如我们在cache B和cache C之间新增了一个cache D,相应的object2就得更换存储的cache节点,连接到了新的cache D上。对于添加的cache D其影响的范围是它和逆时针到达的第一个cahce节点即cache B之间的数据(如图所示的透明区域)。
所以对于cache变动,无论是添加cache节点还是删除cache节点,它影响的范围都是很小的。当然这里还有优化的空间。

理想与现实
理想非常丰满,现实非常骨感。左图就是理想中的情况,A、B、C节点分布的非常均匀。而现实呢有可能是右图这样,显然大量的数据都会落在A节点上,B和C节点存储的数据会较少,如果考虑随机性而言的话。这样会导致A节点服务器很忙,负载很高,而B、C比较清闲。这是由于hash的倾斜性导致的。

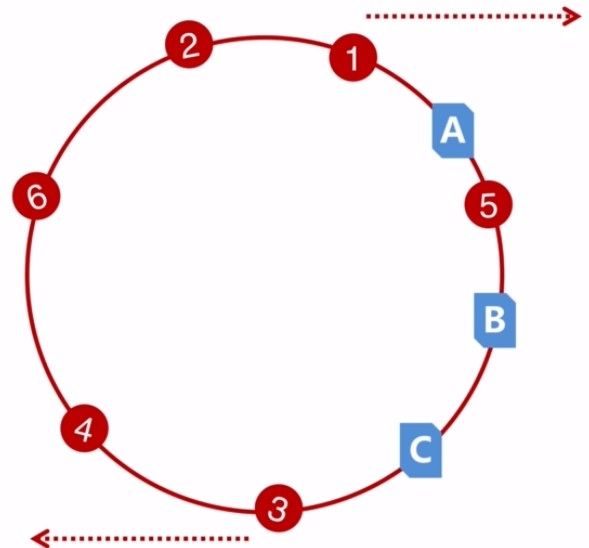
Hash倾斜性
假设有6个数据,它们是随机均匀分布在环形hash空间上,而cache的分布则比较紧密。那么根据这个算法规则数据1、2、3、4、6则都是存储在A节点上,5存储在B节点上,C节点没有数据。这就是hash倾斜性。hash倾斜性导致了A、B、C这三个节点负载、性能都不均匀。
虚拟节点
为了解决hash倾斜性带来的问题,在这个算法中就引入了虚拟节点。来看一下虚拟节点的算法原理。
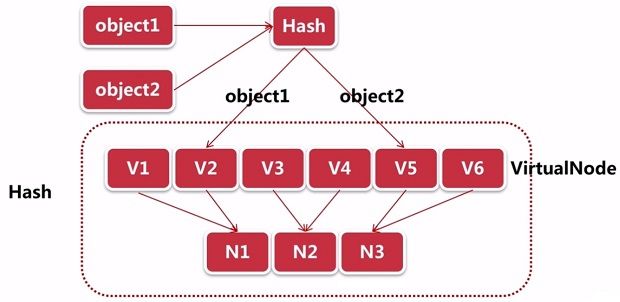
假设有两个数据object1和object2,对它们进行hash,我们增加了6个虚拟节点分别为v1~v6,两个对象hash之后分别落到了v2和v5虚拟节点上,然后对虚拟节点进行rehash,此时v1、v2映射到了N1这个真实节点上,v3、v4映射到了N2节点上,v5、v6映射到了N3节点上。通过虚拟节点把真实的服务器节点进行放大,最终object1存储到了N1节点上,object2存在了N3节点上。
其工作原理就是将一个物理节点拆分为多个虚拟节点,并且同一个物理节点的虚拟节点尽量均匀分布在Hash环上。通过虚拟节点就解决了服务节点少时数据倾斜的问题。
解决hash倾斜性
引入了虚拟节点后,对hash倾斜性的解决方案是怎样的呢?
比如我们增加了6个虚拟节点,这6个虚拟节点最终映射到了3台真实的cache节点,如图所示。我们对数据进行hash后落在了环形空间上,通过算法规则最终1、3数据落在A上,4、5落在B上,2、6落在C节点上。 相对均匀了一些。
但是虚拟节点在rehash时也存在hash倾斜性,我们可以通过调整虚拟节点的数量,把真实节点和虚拟节点分配一个良好的比例,可以想像真实节点和真实节点间都存在大量的虚拟节点,随着节点越来越多,数据越来越多,那么分布会越来越均匀。并且在添加节点和删除节点时影响也会降到最低。

命中率计算
命中率计算公式:(1-n/(n + m)) * 100%
n:服务器台数
m:服务器变动台数
可以看出当变动的服务器台数越大,命中率就会越大。所以影响就会越来越小。随着分布式集群不断扩大时,这个算法的优点就会很自然的迸发出来。
总结
一致性哈希算法首先将整个哈希值空间(0-2^32-1)组织成一个虚拟的圆环,然后将存储对象进行hash,得到的值映射到圆环空间上。然后使用相同的hash算法对cache服务器节点进行hash,并映射到相同的圆环上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器节点上。
Consistent hashing已经最大限度的抑制了键的重新分布,而且还可以采用虚拟节点的思想让每个实际节点都配置100-500个虚拟节点,这样就能抑制分布不均匀了。同时这个算法已经最大限度的减小了服务器增减时的缓存重新分布。