王二北原创,转载请标明出处:来自王二北
这两天项目上需要添加一个限流,基于redis+lua的实现方案,项目中使用ShardedJedis进行redis集群分片,但是ShardedJedis并不支持eval和evalsha函数,所以就对jedis包中SharedJedis部分做了一点修改,使其可以支持这两个函数。顺便看了一下ShardedJedis中分片部分的实现源码,以前也用过基于代理的方式访问redis集群的方案,这里结合着自己的理解总结记录一下。
要实现Redis分布式集群需要注意的点有很多,比如如何进行数据分片、集群服务的高可用、集群的伸缩性等等,这里只着重介绍下面几种redis集群方案中是如何进行数据分片的。
一、关于redis分布式集群的常见实现方案
当应用的访问量和数据量达到一定规模时,单台服务器对应的带宽、cpu、内存甚至是磁盘等都无法应对访问量和数据量日益增长的需求,无论你如何进行垂直扩展(狂加cpu、狂加内存)最后都是无济于事,这个时候通常需要横向进行扩展(无论是mysql等关系型数据库还是redis等nosql都是一样的)。一般常见的redis分布式集群实现方案有如下几种:
(1)基于客户端的分片
以前我所参与过的项目中,实现redis分片的方式通常有两种,一种是当前小节所讲的基于客户端的分片,另外一种是下面小节所讲的基于代理proxy的分片。
基于客户端分片,就是在redis客户端实现如何根据一个key找到redis集群中对应的节点的方案,如下图所示。
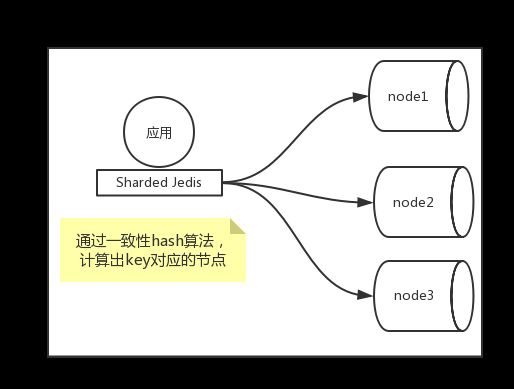
一般来说,基于redis客户端分片通常使用hash(如一致性hash)、取模等算法。很多时候常用的都是采用一致性hash算法,一致性hash算法的好处是当redis节点进行增减时只会影响新增或删除节点前后的小部分数据,相对于取模等算法来说,对数据的影响范围较小。如果将redis作为缓存,并且不考虑数据丢失致使缓存穿透造成的影响,在redis节点增减时可以不用考虑部分数据无法命中的问题。如果将redis作为一个nosql的数据库或者缓存穿透影响会比较大,则需要进行数据的迁移,或者使用预分配的方式来延迟或规避扩容。
预分片
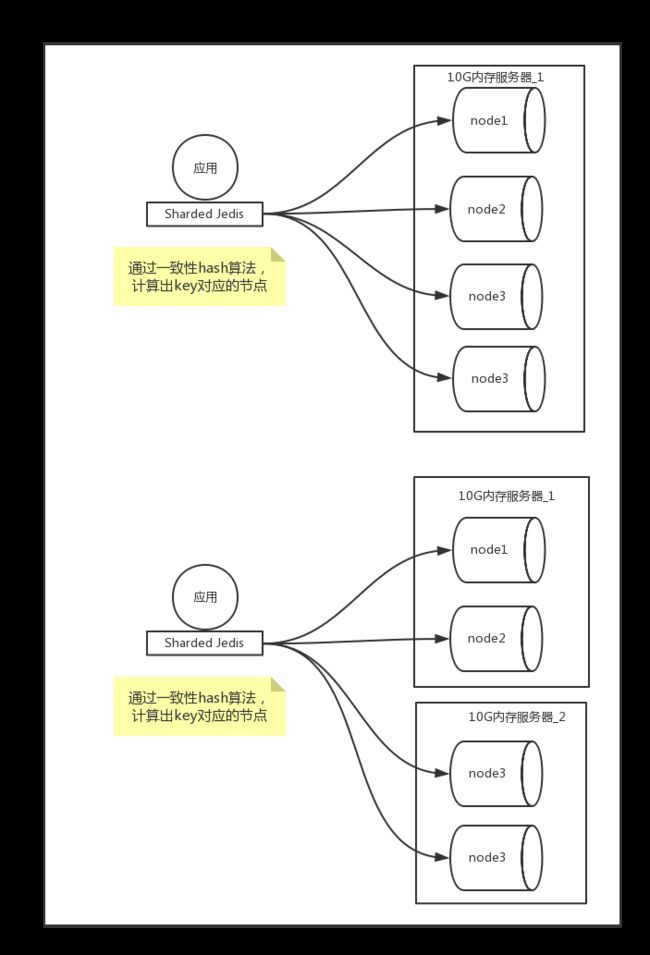
所谓预分片,就是指在项目初期,就启动足够多的redis实例,即使只有一台redis服务器,也在上面启动n个redis实例(n的数值可以根据你预估应用发展的需要,估计一个相对比较大的值,比如你估计项目发展到后期需要有32台redis才能支撑),这台服务器有10G的内存,可以在这台服务器上启动32个redis实例,并且一开始就使用这32个节点进行分片操作。随着数据量的增加,一台服务器的内存逐渐无法满足32个节点的内存需要,则可以将32个节点中的16个节点移动到另外一台服务器上(这台服务器可以使用10G或者更高的内存),这样就有两台服务器,每台服务器上16个redis实例。如果后期数据量增加仍然导致内存不足,则从第一台上移动4台,第二台上移动4台,把这8台移动到第3台服务器上,后期如果有需要,继续进行同样的操作。
移动单个redis实例的过程:
- 在一台新的服务器上启动一台新的redis实例newB.
- 将newB配置为已经存在的redis实例的B的从节点,并将B上的数据同步到newB上。
- 暂停客户端应用(防止新的数据到来,可以在网站等应用上提示服务器正在维护中,请5分钟后重试)。
- 向新服务器的newB节点发送 SLAVEOF NO ONE 命令,不再让newB作为B的从节点。
- 更新客户端或代理上(分片配置的)被移动的redis实例的ip和端口号,并重启服务。
- 最后,停止老的B节点。
移动redis实例过程如下图所示:
现在项目中用的是Sharded jedis,提供了一致性hash和md5散列两种hash算法,默认使用一致性hash算法。并且为了使得请求能均匀的落在不同的节点上,Sharded jedis会使用节点的名称(如果节点没有名称使用默认名称)虚拟化出160个虚拟节点。也可以根据不同节点的weight,虚拟化出160*weight个节点。
当客户端访问redis时,首先根据key计算出其落在哪个节点上,然后找到节点的ip和端口进行连接访问。
(2)基于代理的redis分片
基于中间代理的redis分片,通常是在客户端和redis服务器直接启动一个代理服务proxy,客户端通过proxy与redis服务器进行交互,客户端并不知道proxy后方的redis服务器的架构部署,对客户端来说,proxy服务就相当于一台单独的redis服务,也就说对于客户端来说,redis的集群架构以及后期的扩容迁移等操作都是透明的,redis服务的集群分片、架构变化都是由代理服务proxy来维护的。如下图所示:

基于客户端的redis分片相对来说有一下不足:
- 分片等操作都在客户端,客户端服务规模比较大时,会增加运维的难度。
- 后期redis扩容时需要修改客户端的配置,甚至重启客户端。
- 每台客户端服务与每台redis节点都单独的建立连接,当客户端服务规模比较大时,仍不能共享连接资源,造成资源的浪费,而且不易优化。
基于proxy服务的分片能很好的解决上面的问题,但是proxy服务也有很大的不足,由于中间多了一层代理转发,会造成一定程度上的性能下降,并且需要使用keepalive等保障proxy服务的高可用性。
常用的proxy代理服务有twemproxy、codis等。
(3)基于redis服务器的分片
基于redis服务器的分片,又可称之为“查询路由”,就是客户端随机连接redis集群中的一个节点,向其发送读写请求,如果这个请求不能够被当前节点处理,则这个节点会将请求转发给正确的节点来处理(这一点很像zookeeper中的主从写请求机制),有的实现并不会由当前节点转发给其他节点,而是当前节点响应给客户端一个正确节点的信息,由客户端再次向正确的节点发出请求。
在redis 3.0版本,官方开始推出Redis Cluster方案,这个方案的原理可以简单描述为:先预先划定16384个(2的14次方)槽,每个redis节点上分配一部分槽位。
假设有A、B两个redis节点:
- A节点上分配0到8192的槽位。
- B节点上分配8193到16384的槽位。
当我们通过key存取值的时候,先通过CRC16算法得出key对应的一个数值,然后使用这个数值和16384取模得到的结果就是这个key要落到的槽位。通过槽位就可以找到要去哪个节点上进行存取操作。
这种基于槽位的结构,在添加或删除节点时,需要人工介入:
比如我要添加一个C节点,那么就需要将A节点和B节点上的一部分槽位分配给C节点,并且如果需要,还需将A和B上分配出去的槽位对应的数据迁移到A节点上。同样的,如果想移除C节点,则需要将C上的槽位和数据迁移到A和B上,然后再删除C。
假设,A/B/C三个节点中,C节点宕机,则会导致C对应的槽位的key不能进行存取,因此官方推荐每个redis节点都使用主从模式,当master挂了之后,redis cluster会从从节点中选举一个升级为master,保证了redis集群的高可用性。
客户端在访问redis集群时,有两种实现:
- 一种是最基本的,即客户端把redis集群看成是一个整体,客户端可以连接集群中任意一个节点进行存取操作,当客户端操作的key没有落到它连接的这个节点上时,redis会返回一个跳转指令(redirect),指定客户端去访问正确的node。
- 另外一种是在客户端缓存(配置)对应的槽位与redis节点的映射,客户端就可以直接根据key找到对应的redis节点进行访问。这种方式在集群节点发生变化时,需要进行修改更新客户端缓存的映射关系。
Redis Cluster的方案在redis3.0之后才出现,相对于前面几种方案来说出现的比较晚,使用的比较少,在我以往的项目中基本没有使用过这这种方式,使用shared和proxy的方式比较多一些。
详细可以参考:http://www.redis.cn/topics/cluster-tutorial.html
二、ShardedJedis分片源码简析
SharedJedis是jedis的jar包中提供的基于客户端分片的实现。
SharedJedis分片相关的代码基本都在redis.clients.util.Sharded类中。
下面是Sharded类的构造函数
public Sharded(List shards, Hashing algo, Pattern tagPattern) {
this.algo = algo;
this.tagPattern = tagPattern;
initialize(shards);
}
Sharded的构造函数有三个构造参数:
- shards,可以指定redis的服务信息对象的list集合(ShardInfo的子类,如JedisShardInfo,存放了redis子节点的ip、端口、weight等信息)。
- hash算法(默认一致性hash),jedis中指定了两种hash实现,一种是一致性hash,一种是基于md5的实现,在redis.clients.util.Hashing中指定的。
- tagPattern,可以指定按照key的某一部分进行hash分片(比如我们可以将以order开头的key分配到redis节点1上,可以将以product开头的key分配到redis节点2上),默认情况下是根据整个key进行hash分片的。
在Sharded构造函数中调用了initialize方法完成分片的一些初始化操作:
- 首先根据redis节点集合信息创建虚拟节点(一致性hash上0~2^32之间的点),通过下面的源码可以看出,根据每个redis节点的name计算出对应的hash值(如果没有配置节点名称,就是用默认的名字),并创建了160*weight个虚拟节点,weight默认情况下等于1,如果某个节点的配置较高,可以适当的提高虚拟节点的个数,将更多的请求打到这个节点上。
- Sharded中使用TreeMap来实现hash环。
private void initialize(List shards) {
nodes = new TreeMap();
for (int i = 0; i != shards.size(); ++i) {
final S shardInfo = shards.get(i);
if (shardInfo.getName() == null) for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
else for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash(shardInfo.getName() + "*" + n), shardInfo);
}
resources.put(shardInfo, shardInfo.createResource());
}
}
我们通常通过redis.clients.jedis.ShardedJedis进行redis的读取操作,以set方法为例:
public String set(final String key, final String value) {
Jedis j = getShard(key);
return j.set(key, value);
}
首先通过key获得对应redis分片信息,然后再在这个redis分片节点上进行操作。
下面是通过key进行操作的整个过程,源码的解释,我都加在了注释当中:
public R getShard(String key) {
return resources.get(getShardInfo(key));
}
//注意getKeyTag()方法
public S getShardInfo(String key) {
return getShardInfo(SafeEncoder.encode(getKeyTag(key)));
}
//在介绍Sharded的构造方法时,指定了一个tagPattern,它的作用就是在使用key进行分片操作时,可以根据key的一部分来计算分片,getKeyTag()方法用来获取key对应的keytag,默认情况下是根据整个key来分片,
public String getKeyTag(String key) {
if (tagPattern != null) {
Matcher m = tagPattern.matcher(key);
if (m.find()) return m.group(1);
}
return key;
}
//首先通过key或keytag计算出hash值,然后在TreeMap中找到比这个hash值大的第一个虚拟节点(这个过程就是在一致性hash环上顺时针查找的过程),如果这个hash值大于所有虚拟节点对应的hash,则使用第一个虚拟节点
public S getShardInfo(byte[] key) {
SortedMap tail = nodes.tailMap(algo.hash(key));
if (tail.isEmpty()) {
return nodes.get(nodes.firstKey());
}
return tail.get(tail.firstKey());
}
总的来说,shardedjedis分片的过程如下:
- 根据redis节点名称虚拟出160*weight个虚拟节点。
- 在对key进行存取时,先通过keytag(key或key的一部分)计算出hash值,找到离他最近的比它大的虚拟节点,然后把请求发送到这个节点上。
另外,查看redis.clients.jedis.ShardedJedis的源码,你会发现redis中很多涉及到多个key操作的命令ShardedJedis中都没有支持,这是因为在分片时,这些key可能会被分片到不同的redis节点上,这就会造成:
(1)如果是读取操作,则响应时间等于响应最慢的那个redis节点的时间,并且多个key的读取操作,在ShardeJedis中需要进行归并取交集等操作。
(2)如果是写操作,则有可能会同时去写多个redis节点,很有可能会出现一部分key的写操作成功,而另外一部分失败的问题,也就是无法保证数据一致性的问题。
参考文档:
http://www.redis.cn/topics/cluster-tutorial.html
https://www.cnblogs.com/houziwty/p/5167075.html
http://blog.csdn.net/hj419460467/article/details/51995636
http://blog.csdn.net/upxiaofeng/article/details/51577727