本文主要内容
- LruCache使用
- LruCache原理
- DiskLruCache使用
- DiskLruCache原理
缓存是一种非常常见的策略,它能有效加强资源加载速度,提升用户体验,降低关键资源使用(比如流量等),Android开发中,加载Bitmap经常需要使用缓存。
Android中缓存一般而言,有两种类型,内存缓存和硬盘缓存,它们都是使用Lru算法(最近最少使用算法),算法的实现都是依赖于LinkedHashMap,关于LinkedHashMap可参考LinkedHashMap原理分析,本文主要介绍下两种缓存的使用方法以及源码解析。
LruCache使用
先看看LruCache的构造方法:
int maxMemory = (int) Runtime.getRuntime().maxMemory();
int cacheSize = maxMemory / 8;
mMemoryCache = new LruCache(cacheSize) {
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount();
}
};
构造函数中指定最大内存使用值,同时需要重写sizeOf方法,统计保存元素的内存占用大小。
保存及获取也非常简单:
mMemoryCache.get(key);
mMemoryCache.put(key, bitmap);
使用过程非常简单,当保存元素大小超过LruCache的最大值时,LruCache会自动回收近期最少使用的元素,以回收内存。接下来我们读读源码,看它是怎么实现的
LruCache原理
LruCache中有3个非常重要的成员变量:
//使用LinkedHashMap存储元素
private final LinkedHashMap map;
//当前所有元素总的大小值
private int size;
//允许的最大值
private int maxSize;
LruCache使用LinkedHashMap来保存元素,依赖于LinkedHashMap,才能知道哪个元素是最近最少使用的。如果size大于maxSize,则开始删除内存保存的元素,回收内存。
看看它的put方法:
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
//计算要保存对象的大小
size += safeSizeOf(key, value);
//如果key对应着一个旧的对象,要删除并且减去旧对象的大小
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
//观察是否超过maxSize,如果超过则删除近期最少使用的元素
trimToSize(maxSize);
return previous;
}
put方法的逻辑比较简单,保存键值对到LinkedHashMap中,同时计算大小,在trimToSize方法中,如果当前大小超过最大值了,则要删除近期最少使用元素。
public void trimToSize(int maxSize) {
//循环删除,直到 size <= maxSize 成立
while (true) {
K key;
V value;
synchronized (this) {
if (size <= maxSize) {
break;
}
//找出近期最少使用的Entry对象
//map.eldest方法,应该就是LinkedHashMap的header对象的after节点
Map.Entry toEvict = map.eldest();
if (toEvict == null) {
break;
}
//删除并重新计算所有元素的总大小
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
trimToSize方法也比较简单,只有一个疑惑点,本人下载的是openJDK 7.0的源码,怎么也找不到 LinkedHashMap的eldest 方法,在Android源码中也找不到此方法,结合对 LinkedHashMap 的了解,只能推断是eader对象的after节点。
LruCache的get方法更加简单:
public final V get(K key) {
V mapValue;
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
//create方法默认返回为null,除非用户重写create方法,否则接下来的逻辑都不会发生
V createdValue = create(key);
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
if (mapValue != null) {
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
trimToSize(maxSize);
return createdValue;
}
}
get方法看起来很长,但非常简单,从LinkedHashMap看取值并返回即可。如果不重写create,后边的逻辑都不会执行。在做Bitmap缓存时,一般也不会重写create方法。
DiskLruCache使用
DiskLruCache使用非常广泛。一般硬盘缓存保存在/sdcard/Android/data/pkg/cache/ 目录下,且缓存文件夹中保存着许多未知文件格式的文件,以及 journal 文件,类似下图:
稍后会对 journal 文件进行解释,此处先按下不表。
DiskLruCache的使用稍显复杂,首先,它并不存在于Android源码中,无法直接引用到,需要下载到本地才可使用。我会把DiskLruCache上传到自己的github中,欢迎取用。
先看看 DiskLruCache 的初始化:
mDiskLruCache = DiskLruCache.open(cacheDir, 1, 1, 50 * 1024 * 1024);
在初始化时需要4个参数:
- 缓存位置,用于保存缓存文件的路径,通常是/sdcard/Android/data/pkg/cache/
- appVersion,指当前应用的版本号,并没有特殊的意义,我观察直播吧等app这个值都是1
- valueCount,一般都传1,表示一个entry中保存着几个缓存文件,一般都是1
- maxSize,缓存的最大值,上述代码表示的最大值是50M
下面来看它的get方法:
//获取方法
snapshot = mDiskLruCache.get(key);
if (snapshot != null) {
fileInputStream = (FileInputStream) snapshot.getInputStream(0);
fileDescriptor = fileInputStream.getFD();
}
get返回的对象并不是我们想要的Bitmap或其它的,而是一个Snapshot对象,它可以提供文件读入流供我们使用,进而拿到Bitmap
接下来看看它的保存方法:
Editor editor = mDiskLruCache.edit(key);
if (editor != null) {
OutputStream outputStream = editor.newOutputStream(0);
//拿到输出流,向缓存文件中写入,完成保存
if (downloadUrlToStream(imageUrl, outputStream)) {
editor.commit();
} else {
editor.abort();
}
}
DiskLruCache提供Editor对象,Editor 对象提供文件输出流,用户拿到文件输出流,写文件,文件写完后需要调用commit方法,完成保存。
LruCache和DiskLruCache的完整事例,在下一篇博文中将会完整贴出来,还会上传到github中,本文中暂不加以细节描述。
DiskLruCache原理
DiskLruCache依然使用LinkedHashMap来保存对象,不过对象并不直接保存在LinkedHashMap中,而是保存在文件里,通过文件的输入输出流实现读取与写入。
个人觉得可能DiskLruCache最难理解的大概有两个点:
- journal 文件
- 保存的元素与文件的对应关系
DiskLruCache是线程安全的,而且文件的写入是需要时间的,如何避免文件还未写入完成就被读取呢?
private static final String CLEAN = "CLEAN";
private static final String DIRTY = "DIRTY";
private static final String REMOVE = "REMOVE";
private static final String READ = "READ";
DiskLruCache添加了4种文件操作状态:
- DIRTY ,正在写入缓存文件时,此状态下,缓存文件不可读取
- CLEAN ,写入完成时
- REMOVE ,删除缓存文件
- READ ,读取缓存文件
DiskLruCache操作缓存文件,并将操作状态写入journal 文件。
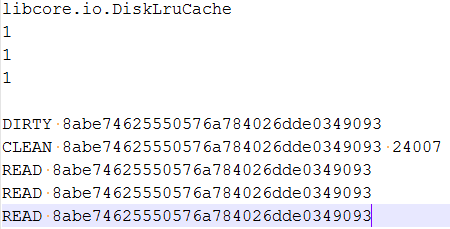
journal 文件前4行的意义分别是:
- libcore.io.DiskLruCache,魔数,类似Java文件的魔数是babycoffee一样,表征文件格式
- 1,表示DiskLruCache的版本,它的值目前是1,代码中定义的final值,可能后续版本号会增加
- 1,表示应用版本号,在DiskLruCache的初始化函数中传入的值
- 1,valueCount,在初始化中传入的值,一般也是1
接下来解释另一个问题,保存的元素与缓存文件之间的对应关系,查看Entry的代码:
public File getCleanFile(int i) {
return new File(directory, key + "." + i);
}
返回的文件以key为名,非常容易就一一对应起来。比较有意思的是文件的后缀,如果i等于0,那么后缀则为 “.0”。我们在DiskLruCache的初始化方法中传入valueCount值为1,表示当前Entry对应着1个缓存文件。后缀与valueCount相关,如果valueCount值为2,则i的值可以取0或1,事实上Entry内部有一个数组,数组的长度就是valueCount,它表示对应缓存文件的大小。
// 表示缓存文件的大小值
private final long[] lengths;
现在来看看缓存文件的保存过程:
private synchronized Editor edit(String key, long expectedSequenceNumber) throws IOException {
checkNotClosed();
validateKey(key);
//获取key对应的Entry对象,lruEntries是LinkedHashMap对象
Entry entry = lruEntries.get(key);
if (expectedSequenceNumber != ANY_SEQUENCE_NUMBER &&
(entry == null || entry.sequenceNumber != expectedSequenceNumber)) {
return null; // Snapshot is stale.
}
//如果entry为null,则构造一个新的entry并保存到lruEntries中
if (entry == null) {
entry = new Entry(key);
lruEntries.put(key, entry);
} else if (entry.currentEditor != null) {
//如果entry不为null,并且它的currentEditor 也不为null
//则表明它正在保存当中,后续可以看到只有正在保存当中的entry,currentEditor 才不为空
return null; // Another edit is in progress.
}
Editor editor = new Editor(entry);
//要开始保存了,才赋值currentEditor ,默认currentEditor 是空的
entry.currentEditor = editor;
//向journal文件中写入事件,当前文件的状态为DIRTY,是一个脏数据,不可读取的
// Flush the journal before creating files to prevent file leaks.
journalWriter.write(DIRTY + ' ' + key + '\n');
journalWriter.flush();
return editor;
}
获取Editor 之后,就可以向用户提供文件输出流了,用户使用文件输出流保存缓存文件。
public OutputStream newOutputStream(int index) throws IOException {
if (index < 0 || index >= valueCount) {
throw new IllegalArgumentException("Expected index " + index + " to " + "be greater than 0 and less than the maximum value count " + "of " + valueCount);
}
synchronized (DiskLruCache.this) {
if (entry.currentEditor != this) {
throw new IllegalStateException();
}
//entry.readable是一个状态值,表明当前entry是否可读,如果是DIRTY状态,则不可读
//readable为false,则不可读,那么Editor对象的written值则为true,表示开始来写文件了
if (!entry.readable) {
written[index] = true;
}
//从entry中获取Dirty file,当写入成功后,会将文件重命名成正式缓存文件
File dirtyFile = entry.getDirtyFile(index);
FileOutputStream outputStream;
try {
outputStream = new FileOutputStream(dirtyFile);
} catch (FileNotFoundException e) {
// Attempt to recreate the cache directory.
directory.mkdirs();
try {
outputStream = new FileOutputStream(dirtyFile);
} catch (FileNotFoundException e2) {
// We are unable to recover. Silently eat the writes.
return NULL_OUTPUT_STREAM;
}
}
return new FaultHidingOutputStream(outputStream);
}
}
文件有不同的状态,DIRTY和CLEAN等,如果是脏数据则不可读取,只有是clean状态,用户才能读取。源码中有几个变量来表征这一过程:
- entry.readable,表示缓存文件是否可读,如果是正在写入文件阶段,则不可读取,会返回空值
- editor.written,表示文件是否正在写入
- entry.currentEditor,只有正在写入,脏数据,currentEditor才不为空
用户获取到了文件输出流,比如说从网络上读取,再写入到此文件输出流中,当文件写入成功后,需要调用commit方法,最终调用到completeEdit方法中。
private synchronized void completeEdit(Editor editor, boolean success) throws IOException {
Entry entry = editor.entry;
if (entry.currentEditor != editor) {
throw new IllegalStateException();
}
// If this edit is creating the entry for the first time, every index
// must have a value.
if (success && !entry.readable) {
for (int i = 0; i < valueCount; i++) {
//如果文件写完了,written还为false,则表明出现异常,要abort这次提交
if (!editor.written[i]) {
editor.abort();
throw new IllegalStateException("Newly created entry didn't create value for index " + i);
}
//如果要写入的dirty file不存在,也是异常情况
if (!entry.getDirtyFile(i).exists()) {
editor.abort();
return;
}
}
}
//从0遍历到valueCount,如果是commit,那么将dirty file改名成正式文件,同时计算大小值加入到总大小值当中
for (int i = 0; i < valueCount; i++) {
File dirty = entry.getDirtyFile(i);
if (success) {
if (dirty.exists()) {
File clean = entry.getCleanFile(i);
dirty.renameTo(clean);
long oldLength = entry.lengths[i];
long newLength = clean.length();
entry.lengths[i] = newLength;
size = size - oldLength + newLength;
}
} else {
deleteIfExists(dirty);
}
}
redundantOpCount++;
entry.currentEditor = null;
if (entry.readable | success) {
//写成功后,将readable置为true,同时向 journal 文件写入 clean状态值
entry.readable = true;
journalWriter.write(CLEAN + ' ' + entry.key + entry.getLengths() + '\n');
if (success) {
entry.sequenceNumber = nextSequenceNumber++;
}
} else {
lruEntries.remove(entry.key);
journalWriter.write(REMOVE + ' ' + entry.key + '\n');
}
journalWriter.flush();
// LRU算法的关键之处,如果超过大小了,则需要删除部分缓存文件
if (size > maxSize || journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
}
在写入成功后,会检测大小是不是超过最大值了,如果超过,则需要删除部分缓存文件。在cleanupCallable中,最后调用 trimToSize 方法。
private void trimToSize() throws IOException {
while (size > maxSize) {
Map.Entry toEvict = lruEntries.entrySet().iterator().next();
remove(toEvict.getKey());
}
}
回忆LinkedHashMap中的内容,lruEntries.entrySet().iterator().next(),它其实就是指代的header的after节点,就是近期最少使用节点,删除它,Lru算法也实现了。
接下来我们看看get方法,这个方法非常的简单:
public synchronized Snapshot get(String key) throws IOException {
checkNotClosed();
validateKey(key);
Entry entry = lruEntries.get(key);
//如果没有保存过此key,返回为null
if (entry == null) {
return null;
}
//如果readable值为false,那么也会返回为null,表明缓存文件还没有写入完成
if (!entry.readable) {
return null;
}
// Open all streams eagerly to guarantee that we see a single published
// snapshot. If we opened streams lazily then the streams could come
// from different edits.
InputStream[] ins = new InputStream[valueCount];
try {
for (int i = 0; i < valueCount; i++) {
//返回clean file的文件输入流
ins[i] = new FileInputStream(entry.getCleanFile(i));
}
} catch (FileNotFoundException e) {
// A file must have been deleted manually!
for (int i = 0; i < valueCount; i++) {
if (ins[i] != null) {
Util.closeQuietly(ins[i]);
} else {
break;
}
}
return null;
}
redundantOpCount++;
//journal 文件中写入read状态
journalWriter.append(READ + ' ' + key + '\n');
if (journalRebuildRequired()) {
executorService.submit(cleanupCallable);
}
//返回Snapshot节点,Snapshot节点中包含缓存文件的输入流,便于用户读取
return new Snapshot(key, entry.sequenceNumber, ins, entry.lengths);
}
从保存缓存文件和读取缓存文件,可以看到 DiskLruCache 设计得非常精妙,它保存时,写入的文件是dirty文件,如果保存成功,将dirty文件改名成clean文件,用户读取缓存文件的时候,则直接返回为clean文件。
关于如何使用内存缓存与硬盘缓存构建二级缓存,我将在下一篇博文中详细阐述