环境准备
服务器集群
我用的CentOS-6.6版本的4个虚拟机,主机名为hadoop01、hadoop02、hadoop03、hadoop04,另外我会使用hadoop用户搭建集群(生产环境中root用户不是可以任意使用的)
关于虚拟机的安装可以参考以下两篇文章:
在Windows中安装一台Linux虚拟机
通过已有的虚拟机克隆四台虚拟机给集群中的每个虚拟机都创建一个hadoop用户,并赋予sudoer权限
参考:
Linux用户管理常用命令
Linux给普通用户赋予sudoer权限每台虚拟机都需安装JDK
参考在Linux中安装JDK集群中的所有虚拟机可以两两之间免秘钥登录以及可以登录自身
参考配置各台虚拟机之间免秘钥登录集群中的所有虚拟机的时间同步
参考Linux集群系统时间同步集群中已经安装了ZooKeeper集群
参考zookeeper-3.4.10的安装配置hadoop安装包
下载地址:https://mirrors.aliyun.com/apache/hadoop/common/
我用的hadoop2.6.5
1. 原理概述
(1) 为什么会有Hadoop HA机制?
HA:High Available,高可用
在Hadoop 2.0之前,在HDFS集群中NameNode存在单点故障 (SPOF:A Single Point of Failure)
对于只有一个NameNode的集群,如果NameNode机器出现故障(比如宕机或是软件、硬件升级),那么整个集群将无法使用,直到NameNode重新启动
(2) 如何解决?
HDFS的HA功能通过配置Active/Standby两个NameNode 实现在集群中对NameNode的热备来解决上述问题。
如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将NameNode很快的切换到另外一台机器。
在一个典型的HDFS(HA)集群中,使用多台单独的机器配置为 NameNode,在任何时间点,确保多个NameNode中只有一个处于 Active状态,其他的处在Standby状态。
其中ActiveNameNode负责集群中的所有客户端操作,StandbyNameNode仅仅充当备机,保证一旦ActiveNameNode出现问题能够快速切换。
为了能够实时同步Active和Standby两个NameNode的元数据信息(editlog),需提供一个共享存储系统,可以是NFS、QJM(Quorum Journal Manager)或者Zookeeper,ActiveNamenode将数据写入共享存储系统,而Standby监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与 ActiveNameNode保持基本一致,如此这般,在紧急情况下 standby便可快速切为 activenamenode。
为了实现快速切换,Standby节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode需要配置所有NameNode的位置,并同时给他们发送文件块信息以及心跳检测。

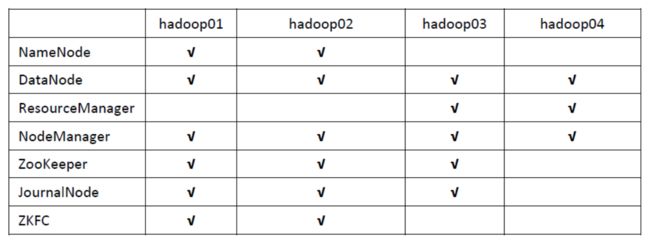
2. 集群规划
3. 安装步骤
(1) 把hadoop安装包上传到服务器并解压
tar zxvf hadoop-2.6.5.tar.gz -C /home/hadoop/apps/
(2) 修改 hadoop-env.sh、mapred-env.sh、yarn-env.sh 这三个配置文件,添加JAVA_HOME
hadoop的配置文件在HADOOP_HOME/etc/hadoop/下
export JAVA_HOME=/usr/local/jdk1.8.0_73
(3) 修改 core-site.xml
fs.defaultFS
hdfs://jed/
hadoop.tmp.dir
/home/hadoop/hadoopdata/
ha.zookeeper.quorum
hadoop01:2181,hadoop02:2181,hadoop03:2181
(4) 修改 hdfs-site.xml
dfs.replication
2
dfs.nameservices
jed
dfs.ha.namenodes.jed
nn1,nn2
dfs.namenode.rpc-address.jed.nn1
hadoop01:9000
dfs.namenode.http-address.jed.nn1
hadoop01:50070
dfs.namenode.rpc-address.jed.nn2
hadoop02:9000
dfs.namenode.http-address.jed.nn2
hadoop02:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/jed
dfs.journalnode.edits.dir
/home/hadoop/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.jed
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
(5) 修改 mapred-site.xml
集群中只有mapred-site.xml.template,可以从这个文件进行复制
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop01:10020
mapreduce.jobhistory.webapp.address
hadoop01:19888
(6) 修改 yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
jyarn
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop03
yarn.resourcemanager.hostname.rm2
hadoop04
yarn.resourcemanager.zk-address
hadoop01:2181,hadoop02:2181,hadoop03:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
86400
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
(7) 修改 slaves 配置文件,指定DataNode所在的节点
hadoop01
hadoop02
hadoop03
hadoop04
(8) 把hadoop安装包分发给其他节点
[hadoop@hadoop01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.6.5 hadoop02:/home/hadoop/apps/
[hadoop@hadoop01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.6.5 hadoop03:/home/hadoop/apps/
[hadoop@hado0p01 hadoop]# scp -r /home/hadoop/apps/hadoop-2.6.5 hadoop04:/home/hadoop/apps/
(9) 给每个节点配置HADOOP_HOME环境变量
vim ~/.bash_profile
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
(10) 启动zookeeper集群
保证zookeeper集群正常启动
zkServer.sh start
# 检查zookeeper集群是否正常
zkServer.sh status
(11) 分别在每个journalnode节点上启动journalnode进程
[hadoop@hadoop01 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop02 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop03 ~]$ hadoop-daemon.sh start journalnode
使用jps命令确认这3个节点上的JournalNode进程都启动
(12) 在第一个namenode节点(node01)上格式化文件系统
[hadoop@hadoop01 ~]# hadoop namenode -format
看到以下信息说明格式化成功:

(13) 同步两个namenode的元数据
查看你配置的hadoop.tmp.dir这个配置信息,得到hadoop工作的目录,我的是/home/hadoop/hadoopdata/,把hadoop01上的hadoopdata目录发送给hadoop02的相同路径下,这一步是为了同步两个namenode的元数据
[hadoop@hadoop01 ~]$ scp -r /home/hadoop/hadoopdata hadoop02:/home/hadoop/
也可以在hadoop02执行以下命令:
[hadoop@hadoop02 ~]# hadoop namenode -bootstrapStandby
(14) 格式化ZKFC(任选一个namenode节点格式化)
[hadoop@node01 ~]# hdfs zkfc -formatZK
看到如下信息说明ZKFC格式化成功

(15) 启动hdfs
[hadoop@hadoop01 ~]$ start-dfs.sh
(16) 启动yarn
[hadoop@hadoop03 zkdata]$ start-yarn.sh
# 需要在另外一个resourcemanager节点手动启动resourcemanager
[hadoop@hadoop04 zkdata]$ yarn-daemon.sh start resourcemanager
(17) 启动 mapreduce 任务历史服务器
[hadoop@hadoop01 ~]mr-jobhistory-daemon.sh start historyserver
3. 验证集群是否搭建成功
(1) 查看进程是否全部启动
根据集群的规划查看是否每个节点对应的进程都启动了
[hadoop@hadoop01 ~]$ jps
5906 DataNode
6420 Jps
5461 QuorumPeerMain
6347 DFSZKFailoverController
6028 NodeManager
5804 NameNode
5534 JournalNode
6515 JobHistoryServer
[hadoop@hadoop02 ~]$ jps
4096 DFSZKFailoverController
4176 Jps
3508 QuorumPeerMain
3911 NodeManager
3815 DataNode
3752 NameNode
3581 JournalNode
[hadoop@hadoop03 ~]$ jps
49825 DataNode
50002 NodeManager
50359 Jps
49657 QuorumPeerMain
49898 ResourceManager
49738 JournalNode
[hadoop@hadoop04 ~]$ jps
3332 DataNode
3240 QuorumPeerMain
3643 Jps
3406 NodeManager
3598 ResourceManager
(2) 查看HDFS状态
这里只展示部分
[hadoop@hadoop01 ~]$ hdfs dfsadmin -report
......
-------------------------------------------------
Live datanodes (4):
Name: 192.168.21.11:50010 (hadoop01)
Hostname: hadoop01
......
Name: 192.168.21.12:50010 (hadoop02)
Hostname: hadoop02
......
Name: 192.168.21.13:50010 (hadoop03)
Hostname: hadoop03
......
Name: 192.168.21.14:50010 (hadoop04)
Hostname: hadoop04
......
(3) 查看各节点的主备状态
[hadoop@hadoop01 ~]$ hdfs haadmin -getServiceState nn1
standby
[hadoop@hadoop01 ~]$ hdfs haadmin -getServiceState nn2
active
[hadoop@hadoop01 ~]$ yarn rmadmin -getServiceState rm1
active
[hadoop@hadoop01 ~]$ yarn rmadmin -getServiceState rm2
standby
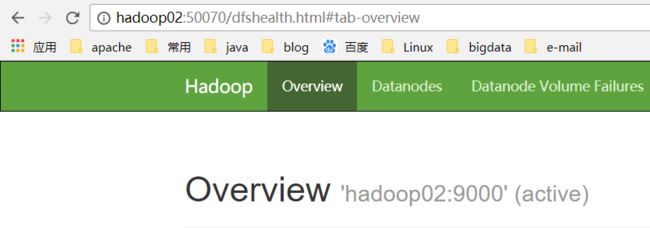
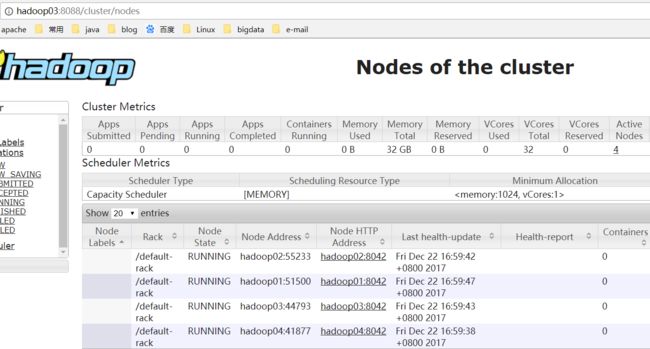
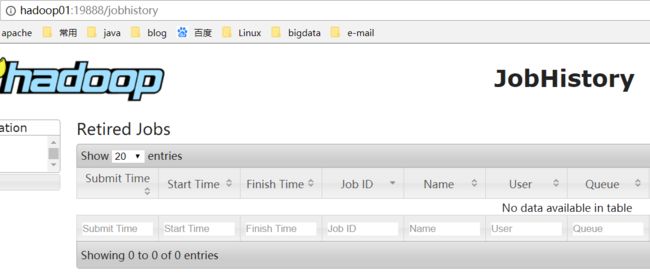
(4) 访问WEB页面
-
访问namenode

-
访问resourcemanager,当访问到resourcemanager的备节点,会自动切换到主节点
-
访问历史记录服务器
(5) 验证集群的功能是否正常
# 上传一个文件
[hadoop@hadoop01 ~]$ hdfs dfs -put ./zookeeper.out /
# 上传成功
[hadoop@hadoop01 ~]$ hdfs dfs -ls /
Found 2 items
drwxrwx--- - hadoop supergroup 0 2017-12-22 16:49 /tmp
-rw-r--r-- 2 hadoop supergroup 1662 2017-12-22 17:06 /zookeeper.out
# 执行一个mapreduce例子程序
[hadoop@node01 mapreduce]# pwd
/home/hadoop/apps/hadoop-2.6.5/share/hadoop/mapreduce
[root@node02 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.6.5.jar pi 5 5
# 执行成功,打印的记录最后一行有pi的结果
......
Estimated value of Pi is 3.68000000000000000000
(6) 验证集群高可用
# 杀死ActiveNameNode进程
[hadoop@hadoop02 ~]$ jps
......
5804 NameNode
[hadoop@hadoop02 ~]$ kill -9 5804
hadoop02现在不能访问

hadoop01切换为ActiveNameNode
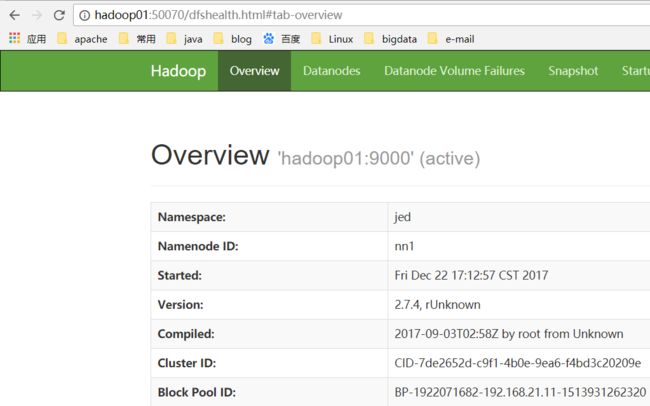
重新启动hadoop02的namenode
[hadoop@hadoop02 ~]$ hadoop-daemon.sh start namenode
hadoop02的namenode并不会切换成ActiveNameNode,而是成为StandbyNamenode

到此,Hadoop HA集群搭建成功!
4. Hadoop HA集群的重装
- 删除所有节点中hadoop的工作目录(core-site.xml中配置的
hadoop.tmp.dir那个目录) - 如果你在core-site.xml中还配置了
dfs.datanode.data.dir和dfs.datanode.name.dir这两个配置,那么把这两个配置对应的目录也删除 - 删除所有节点中hadoop的log日志文件,默认在HADOOP_HOME/logs目录下
-
删除zookeeper集群中所关于hadoop的znode节点

图中的红色框中的znode节点是与hadoop集群有关的,但rmstore这个节点不能删除,会报以下错误
Authentication is not valid : /rmstore/ZKRMStateRoot/RMVersionNode
所以删除另外两个就可以,重新格式化ZKFC的时候会询问是否覆盖rmstore这个节点,输入yes即可
- 删除所有节点中的journaldata,路径是在hdfs-site.xml 中的
dfs.journalnode.edits.dir中配置的 - 按照上面安装集群的步骤重新安装即可