文章思路:1.介绍字符编码相关概念。 2.实际应用示例(java io)。 3.java io 源码分析。
ibm的论坛里面的那篇许令波的文,我觉得蛮详细的。ibm的论坛里面真的有不少好东西。
我的这篇算笔记,全文基本围绕许令波的文开展而来。
首先,字符编码这个概念是怎么来的?拆开来是两个词语:字符——编码。先分别理解这两个词语。
字符
计算机中处理的数据有两类:数值数据和非数值数据。
数值数据指表示数量的数据,有正负和大小之分,在计算机中以二进制的形式存储和进行运算。
非数值数据包括字符、汉字、声音和图像等(注意:“字符”跟“汉字”我觉得在含义上稍微有点重合,因为字符包括了汉字),在计算机中处理前必须以某种编码形式转换成二进制数表示。
出处:
程序员考试辅导
https://books.google.com/books?id=z5wHFhgKnAUC&pg=PA4&lpg=PA4&dq=%E7%A0%81%E5%88%B6%E6%98%AF%E4%BB%80%E4%B9%88&source=bl&ots=z4uTklbcn3&sig=Jzt1zA3TW0HkldW6FKj4SiLaJdM&hl=zh-CN&sa=X&ved=0ahUKEwiLg5jipevZAhVF8GMKHYiIBHMQ6AEIQzAG#v=onepage&q&f=false
由以上可知,计算机中处理的非数值数据——字符,在计算机中处理前必须以某种编码形式转换成二进制数表示。那么问题来了,什么是字符?字符是如何编码的?有哪几种常见编码形式?
简单地看下 字符的概念。
字符(character)是一段文字的最小单位,它可能是汉字、阿拉伯数字、英文字母、日语假名、标点符号或其他有意义的内容。
charset :字符集。拆开来是character——set。
Java集合-----Set , Set:无序的,不可重复的。字符集理解成一个set,存储的是character。
编码
常见编码格式有 ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16、Unicode 等。
例如ASCII 码表中的字符 * (这就相当于是一个编码的过程),计算机要如何识别该数据呢?这就需要解码了。凡是有编码的地方,就需要解码。这里计算机需要对应ASCII码表去解码。 * 对应二进制数值为0010 1010。
从上面的例子来看,编码就是定义一个规则(这里具体体现在表上面),key和value一一对应,使用数值数据(key)来表示非数值数据(value)。计算机通过key-value的方式,表示非数值数据。
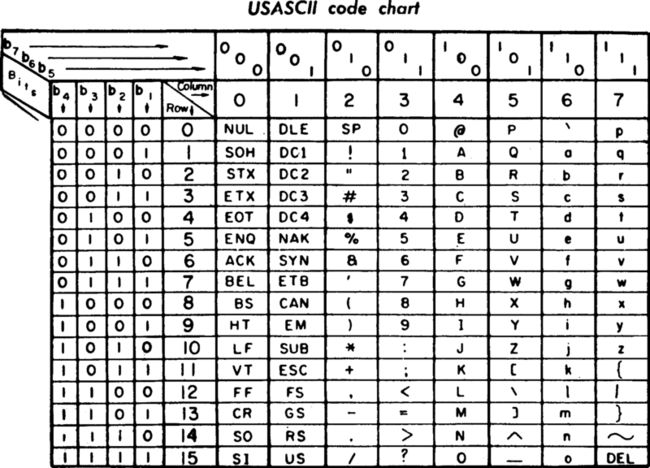
英文字符编码的国际标准是ASCII码。用7位二进制数表示,可表示128个符号(ASCII编码表中,不同的二进制数据对应不同的字符)。
汉字编码有很多种方法。 例如GB2312的编码方式是区位码,将常用汉字分成94 个区,每个区又分94 位。
1.ASCII码
ASCII 的最后一次更新是在 1986 年,由 ANSI 发布了 ANSI INCITS 4-1986 (R2012)。
2.ISO-8859-1
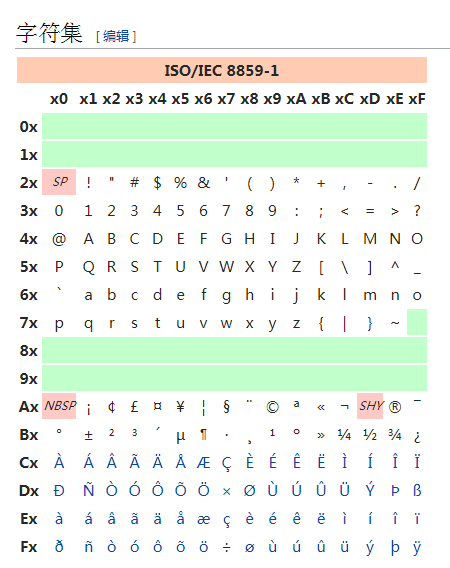
128 个字符显然是不够用的,于是 ISO 组织在 ASCII 码基础上又制定了一些列标准用来扩展 ASCII 编码,它们是 ISO-8859-1~ISO-8859-15,其中 ISO-8859-1 涵盖了大多数西欧语言字符,所有应用的最广泛。ISO-8859-1 仍然是单字节编码,它总共能表示 256 个字符。
文字太单调,图文更好理解。
3.GB2312
它的全称是《信息交换用汉字编码字符集 基本集》,它是双字节编码,总的编码范围是 A1-F7,其中从 A1-A9 是符号区,总共包含 682 个符号,从 B0-F7 是汉字区,包含 6763 个汉字。具体可以下载pdf文档看看,简单明了。
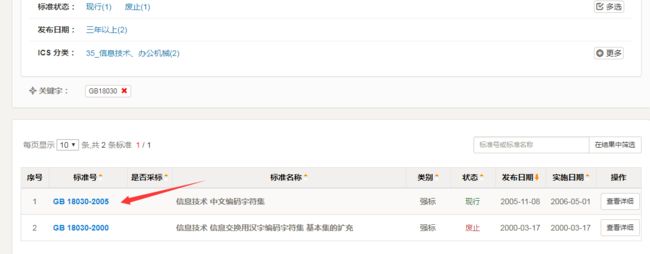
不知道为什么这种gb开头的pdf版的资料网络上很难找到。在寻找过程中发现国家标准全文公开系统的网站,但是这个网站能看的GB文件不全,GB2312是查不到的,应该是未收录。GB18030我倒是查到了。2000年3月17日推出了GB 18030-2000标准,以取代GBK,但是2000版下载废止了,现行是2005版。
网站链接: http://www.gb688.cn/bzgk/gb/index
下载地址:ftp://ftp.oreilly.com/examples/cjkvinfo/AppE/gb2312.pdf
这里我是用idm下载的。
这里的是加密版,如需解密,可通过一些解密pdf网站解密。
对我而言,看看就行,不用太深入了解。
GB 2312-80是一个94*94的表。
横的叫区,竖的叫位,总共 94 个区,每个区有 94 个位。区和位的编号都从 1 开始。可以看到粗略有三大部分。
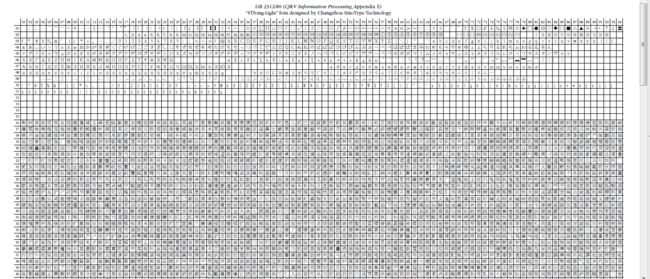

关于GB2312更多详细的地方,可参考文末的参考链接中的文章:字符集与编码(九)——GB2312,GBK,GB18030。
4.GBK
全称叫《汉字内码扩展规范》。由于GB 2312-80只收录6763个汉字,有不少汉字,如部分在GB 2312-80推出以后才简化的汉字(如“啰”),部分人名用字(如的“镕”字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。于是厂商微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码(GB 13000已废止)。
这句话来自wiki,但是我不确定正确性:
代码页936 比 GBK 少95个字符,皆为当时尚未收入 Unicode 的字符,虽然该等字符现在已全部收入 Unicode,但代码页936 至今都没有修订。
现时中国大陆强制要求所有软件皆要支持 GB 18030(Microsoft 称之为代码页54936)。
主要我不确定2018年4月19日,我写这篇文章的时候,Code page 936是否有修订。应该是一开始通用的GBK就是微软的代码页936,后来GBK增加了一些字符但是936没有修订,目前看来是这样的。
但是,目前我能找到的最全的GBK表应该就是微软的Code page 936,这个看看就行。
GBK 使用两字节保存中文,也能兼容 ASCII,而对常用汉字,UTF-8 都是采用三字节编码,因此无论是全中文还是中英文混合的情况,GBK 保存的效率都要好于 UTF-8。
但它也有些不好的地方,比如它不能支持一些国际性的文字,在国际化,通用性方面它肯定不如 UTF-8;就汉字而言,由于容量空间的限制,它也无法收录更多的汉字了。
这个表我没有找到pdf版的文档,但是有一个微软的网页版文档,质量比较高,大部分网站版的排版惨不忍睹,当然我的文章排版也很烂就是了。
微软的Code page 936网页链接貌似一直在换,因此如果链接指向404,例如下面的这个网页链接失效了。
http://msdn.microsoft.com/en-US/goglobal/cc305153.aspx
然后,解决办法:搜索 Code page 936。
微软的网站,百度也是可以搜索的出来的。
有效地址:
https://msdn.microsoft.com/en-us/library/cc194913.aspx
大致看看就行。

5.GB18030
全称是《信息交换用汉字编码字符集》,是我国的强制标准,它的编码与 GB2312 编码兼容,这个虽然是国家标准,但是实际应用系统中使用的并不广泛。貌似GBK比GB18030广泛,不知道为什么。可能本身有硬伤吧。这个标准可以在前面的国家标准官网上看。
6.Unicode
unicode是字符集,utf-8、utf-16等是表现形式(编码方式,类似于中文跟行书、楷书等的关系)。
Unicode 是 Java 和 XML 的基础,下面详细介绍 Unicode 在计算机中的存储形式。
由 Xerox、Apple 等制造商于 1988 年组成的统一码联盟(The Unicode Consortium)也在致力于开发一个单一字符集,即 Unicode。付费即可加入。
Unicode在很长一段时间内无法推广,直到互联网的出现。

Unicode译为万国码、国际码。Unicode是为了解决传统的字符编码方案的局限而产生的,例如ISO 8859-1所定义的字符虽然在不同的国家中广泛地使用,可是在不同国家间却经常出现不兼容的情况。
Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符。
Unicode只是一个符号集, 它只规定了符号的二进制代码, 却没有规定这个二进制代码应该如何存储(因此有了utf-8 -16 -32)。
比如UTF-8、UTF-16、UTF-32都是Unicode编码的实现方式,不过UTF-8是使用最多的实现。
GBK和UTF-8的相互转换
一般来说UTF-8可应用于大多数场景,尤其是互联网上,而中文编码主要使用GBK编码,因此这就有了GBK、GB2312和UTF-8的相互转换需求。
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换
GBK、GB2312 —> Unicode —> UTF-8
UTF8 —> Unicode —> GBK、GB2312
下面的链接是在网上搜到的Unicode编码表,700多页,可以看看感受下(ps:百度网盘真是个好东西),孤立地看表用处不大。
https://pan.baidu.com/s/1slg2Pit
7.UTF-8
UTF-16 统一采用两个字节表示一个字符,虽然在表示上非常简单方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的今天,这样会增大网络传输的流量,而且也没必要。而 UTF-8 采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以是由 1~6 个字节组成。
UTF-8是采用变长的编码方式,为1~6个字节,但通常我们只把它看作单字节或三字节的实现,因为其它情况实在少见。UTF-8编码通过多个字节组合的方式来显示,这是计算机处理UTF-8的机制,它是无字节序之分的,并且每个字节都非常有规律。
UTF-8 有以下编码规则:
如果一个字节,最高位(第 8 位)为 0,表示这是一个 ASCII 字符(00 - 7F)。可见,所有 ASCII 编码已经是 UTF-8 了。
如果一个字节,以 11 开头,连续的 1 的个数暗示这个字符的字节数,例如:110xxxxx 代表它是双字节 UTF-8 字符的首字节。
如果一个字节,以 10 开始,表示它不是首字节,需要向前查找才能得到当前字符的首字节。
utf-8节省空间示例:最后一个字符感叹号,用utf-8只要一个字节,而utf-16需要两个字节。由此可见utf-8可以节省空间。
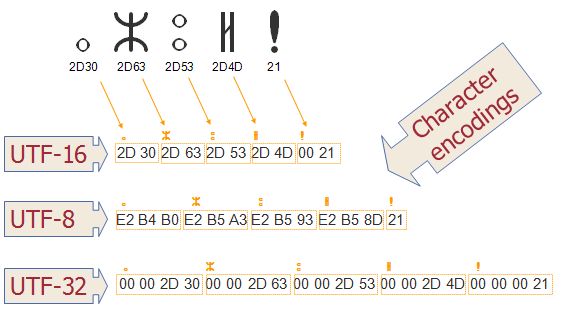
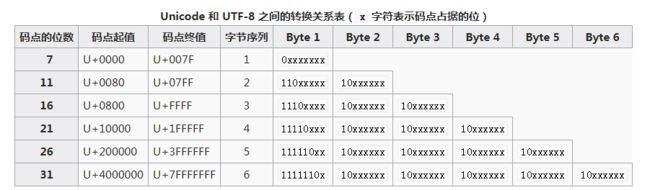
关于这个转换过程的理解(下面仅以utf-8为例):
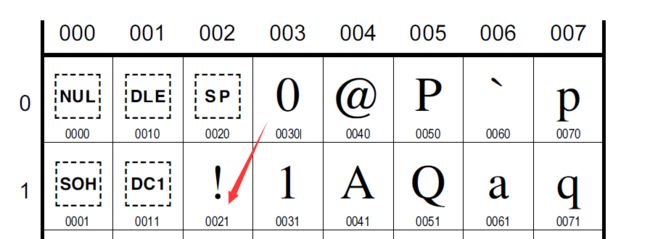
以感叹号 “!”为例,“!”在unicode编码表中,对应的十六进制数据为0021。转换成二进制数据为100001(这个是用计算器算的)。对应的utf-8格式的数据为0xxxxxxx(因为范围在U+0000 -- U+007F内),因此“!”为00100001(转换成十六进制依旧是21)。
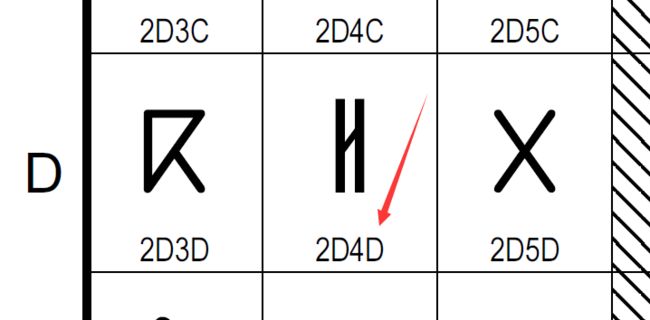
2D4D转换成10110101001101 。根据码点范围判断2D4D应该为1110xxxx 10xxxxxx 10xxxxxx。 即 11100010 10110101 10001101 。转换成十六进制,即为E2B58D。
还有一种直接使用Notepad++插件的方式,对Unicode 与 UTF-8 之间的转换。
在安装完所需插件(HEX-Editor)后,新建txt文档,写下“如”字。
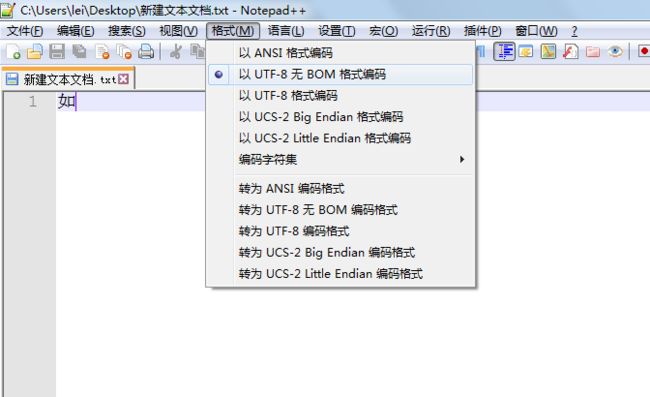
然后使用插件,查看对应的utf-8的十六进制数据。
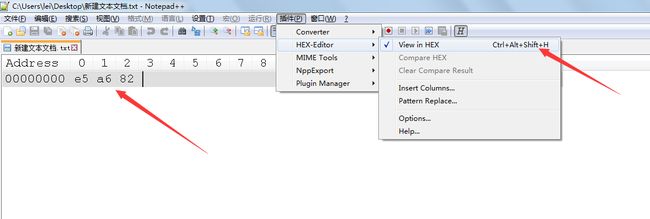
下面验证下转换的结果。
“如”字在unicode编码表中对应的数字为5982(十六进制),转换成二进制数据即为101 100110 000010(应使用1110xxxx10xxxxxx10xxxxxx对其进行补全)。
补全后数据为11100101 10100110 10000010。
最后转换成十六进制为E5A682。

参考链接:
Unicode详解
https://charlee.li/unicode-intro.html
【字符编码系列】常用的几种字符编码(GBK,UTF-8,UTF-16)
https://dailc.github.io/2017/05/17/severalCommonlyCharEncoding.html
GBK 汉字内码扩展规范编码表(编码顺序)
https://wenku.baidu.com/view/efb261f8770bf78a6529549c.html?rec_flag=default&sxts=1531299962698
最全面的GBK编码表/GBK字符集
http://tools.jb51.net/table/gbk_table
Unicode 和 UTF-8 有什么区别?
https://www.zhihu.com/question/23374078
UTF-8
https://zh.wikipedia.org/wiki/UTF-8
Notepad++ 使用二进制或16进制模式查看文件
https://blog.csdn.net/hong10086/article/details/76423268
——————————————————分割线——————————————————
以上简单地介绍了常见的编码规则,下面来看看如何应用(理论是实践的基石)。那么回到最初,我是如何发散到这个问题这里来的。
首先,Unicode 是 Java 和 XML 的基础。
最初是将android设备当做服务器,从电脑端利用curl上传文件(curl命令是curl -F "key=value" -F "filename=@你好.txt" http://192.168.3.169:8080/upload),当文件名有中文字符的时候,文件从电脑传至android设备中的时候,文件名变成乱码(问题的出现的原因是当编码格式不一致的时候,字符会出现乱码)。后面解决办法是传输文件的过程中,修改android程序中的代码,设置编码格式为gbk(fileUpload.setHeaderEncoding("gbk"))。乱码是如何产生的? 本质上都是由于字符原本的编码格式 与 读取时解析用的编码格式不一致导致的。
从下表中可以看出,中文版本的Windows系统,默认编译环境是GBK。
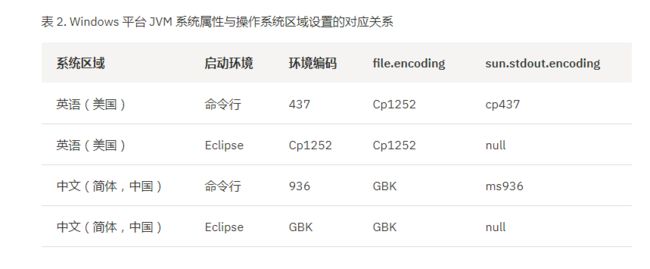
//待精简
——————分割线————
从Windows中发出的文件的文件名,是以gbk编码的,而Unicode是java的基础,因此,在文件从Windows向android设备传输过程中,由于编码解码格式不一致,导致了乱码现象的产生。
当android设备与PC设备之间进行socket或HTTP通讯时,常常会出现中文乱码问题,其主要原因在于android设备端字符编码默认为UTF-8,而PC设备端默认为gbk。
如果pc端能进行编码的话,就最好在字符传输之前,将字符编码格式GBK转成UTF-8,但是我由于是用curl命令行发送文件(即pc作为客户端,android设备作为服务端),并且我没有找到将文件转换后传输的命令,因此,我需要改变java代码(即android设备端的部分代码,设置传输过程中的编码格式为gbk)。
android设备中以utf-8格式来显示接收到的gbk格式的字符,字符出现乱码。怎么出现乱码的呢?
打个比方中文字“啊”在GBK中对应的机内码是B0A1,在unicode中对应的数据是554A(对应UTF-8格式的十六进制数据为e5 95 8a),要知道,gbk和utf只是编码格式,字符数据在计算机中是以二进制形式存储的,传递字符数据的时候,传递的实际是对应编码表中的字符的位置(即B0A1或554A,实际传递的是01011(瞎写的)),再由JVM解码,得到字符。当JVM以utf-8格式去 解B0A1这个位置实际会得到什么?不知道,但是绝对不会是“啊”字。因为unicode格式中“ 啊”的位置是554A。因此,数据显示就出现了乱码。
//语言啰嗦,画个图更简单明了。
简单来看,应该类似于下面的情况。
以utf-8格式写入“如”后,如果直接选择以ANSI格式编码,就会变成乱码。

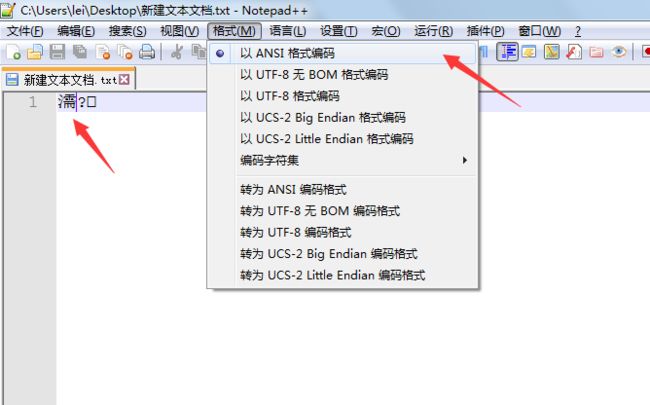
但是,如果选择转为ANSI格式编码,就不会产生乱码。

当选择转为ANSI编码格式后,文件会以ANSI格式显示。
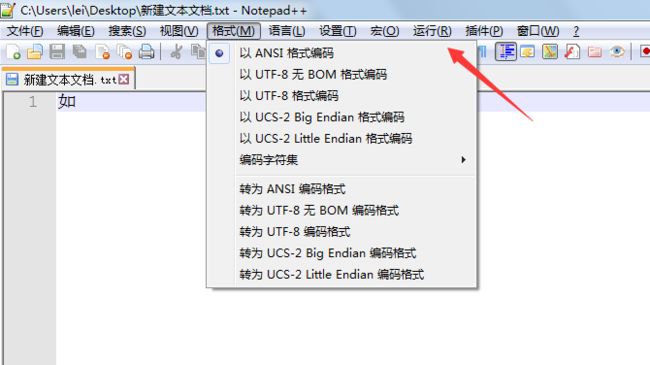
8.UTF-16
UTF-16 具体定义了 Unicode 字符在计算机中存取方法。UTF-16 用两个字节来表示 Unicode 转化格式,这个是定长的表示方法,不论什么字符都可以用两个字节表示,两个字节是 16 个 bit,所以叫 UTF-16。UTF-16 表示字符非常方便,每两个字节表示一个字符,这个在字符串操作时就大大简化了操作,这也是 Java 以 UTF-16 作为内存的字符存储格式的一个很重要的原因。
UTF-16由RFC2781规定,它使用两个字节来表示一个代码点(unicode中对应的值)。
字符“如果没有”。代码点为5982 679C 6CA1 6709。
当以utf-16 大端格式编码时二进制数据为fe ff 59 82 67 9c 6c a1 67 09


//字符“如果没有”。代码点为5982 679C 6CA1 6709。
当以小端格式编码时二进制数据为ff fe 82 59 9c 67 a1 6c 09 67 。
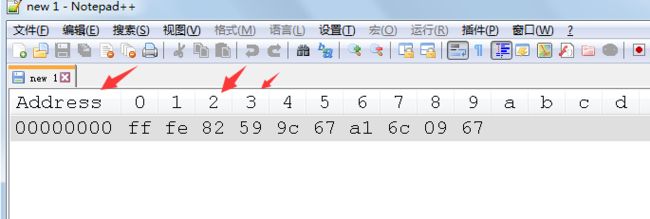
UTF-16中,一个字符是用2个字节来表示 59 82 (十六进制)的。59占一个字节(2个数值占一个字节),82占一个字节,一个字节有8个bit位。十六进制的59转为二进制数据则为 1011001,因此在计算机中该数据实际存储为 0101 1001(即一个字符两个字节)。
大小端的差别在于——代码点的存储顺序(字符所对应字节的存储方式)。
至此,字符编码相关概念基本就这么多。下面来看一看实际应用。