一、CNN文本分类简介
文本分类是NLP领域的一个重要子任务,文本分类的目标是自动的将文本打上已经定义好的标签,常见的文本分类任务有:
- 用户评论的情感识别
- 垃圾邮件过滤
- 用户查询意图识别
- 新闻分类
由此看出文本分类的用途十分之广,包括知识图谱领域的关系抽取任务也是使用文本分类实现的。
有很多经典的统计学习方法可以用来做文本分类,比如SVM,LR,MaxEnt等等。这些方法的一般流程是标注数据、特征工程、模型训练、模型预测。有过相关经验的同学应该知道,这里最耗费时间的过程应该就是特征工程。这里特征通常有词法特征、语法特征等等,下面找了一篇关于特征设计的论文供大家参考:http://www.aclweb.org/anthology/S10-1057

这是篇关系抽取的论文,但其中特征的设计可以供我们参考 。这个表中的特征有词性识别(pos)、依存分析(dependency)、N-gram等,除此之外还使用很多外部知识库,比如wordNet/FrameNet/TextRunner等等,要想训练一个比较好的文本分类器,需要设计大量的特征,有的任务特征会达到千万级别。特征设计这里主要有两个缺点:
- 需要一些背景知识设计各种精巧的特征
- 需要借助其他NLP工具。NLP工具本身会有一些误差,这样就将误差传播到后续的任务中
这里就不得不提深度学习的强大,比如CNN可以自动的提取一些文本的特征而不需要再人工设计大量的特征,而且在准确率上甚至比人工设计特征的方法还要高。也难怪目前NLP领域都开始上深度学习了。
二、CNN模型
2.1 CNN模型简介
卷积神经网络(CNN)跟全连接神经网络一样,CNN的每一层也是由神经元组成的,全连接神经网络中,每相邻的两层之间的节点都有边相连,而CNN相邻层之间只有部分节点相连,并且在CNN的输入层、卷积层、池化层中,每层的维度包括输入都是三维的。
CNN通常由输入层、卷积层、池化层、全连接层、softmax层组成,下面简单介绍下这几层,以方便大家理解CNN是如何工作的。
2.1.1 卷积层
卷积层是卷及神经网络中最重要的部分,这个部分通常被称作过滤器(filter)或内核(kernel),在这里我们称之为过滤器。下图是一个过滤器工作的示意图:
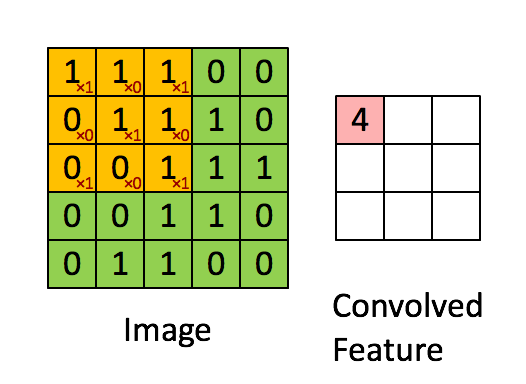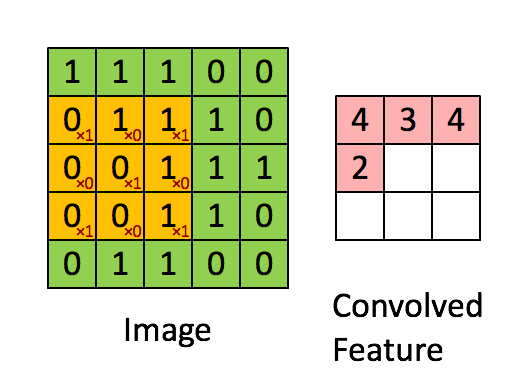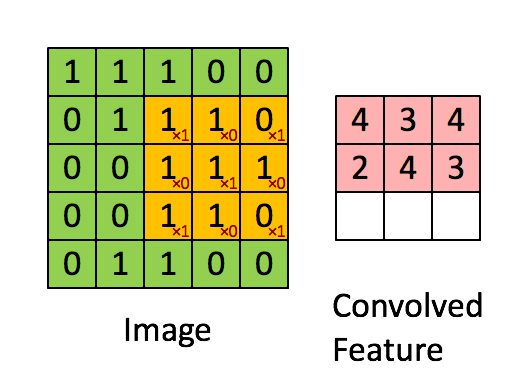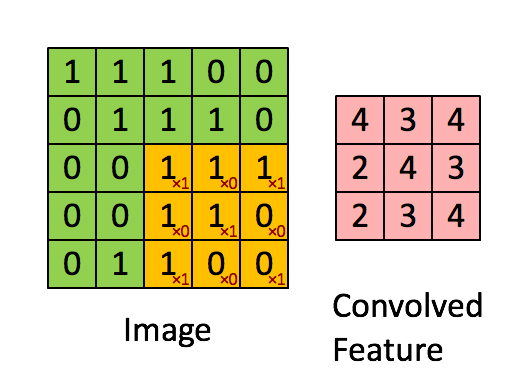
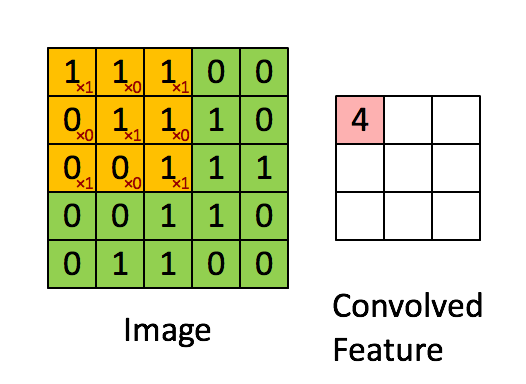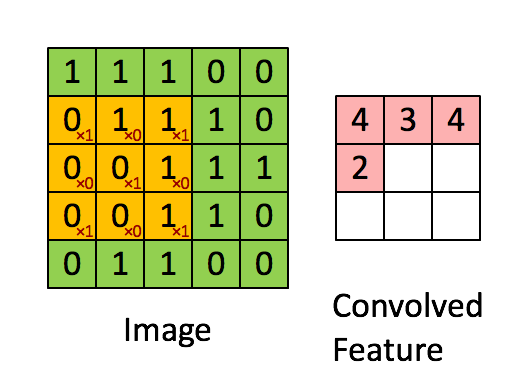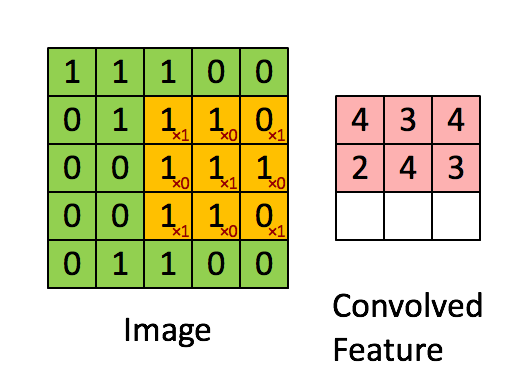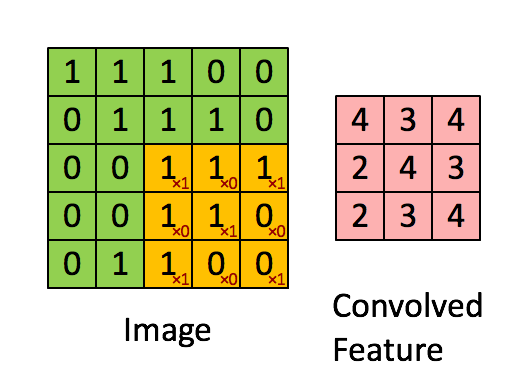
输入经过一个filter处理后得到的粉红色区域叫做Feature Map,在示意图中filter的尺寸是[图片上传失败...(image-e4bdc7-1557814223444)]
,在实际应用中这个尺寸也是根据需求人工设定的,一般设定为[图片上传失败...(image-bbecc1-1557814223444)]
等等。因为过滤器处理矩阵的深度与当前层神经网络矩阵的深度时一致的,所以在这里我们只设定过滤器的长和宽就可以了,另外我们还需要指定过滤器的深度。过滤器的作用在图像领域比较好理解,就是提取图像局部的特征。
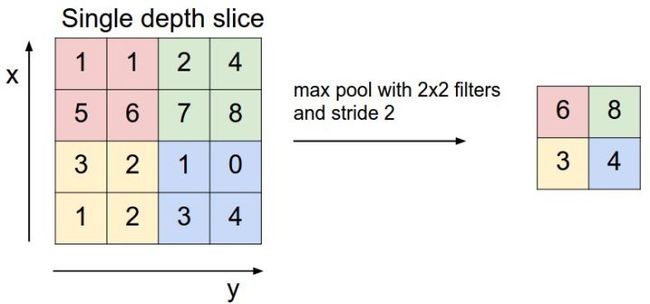
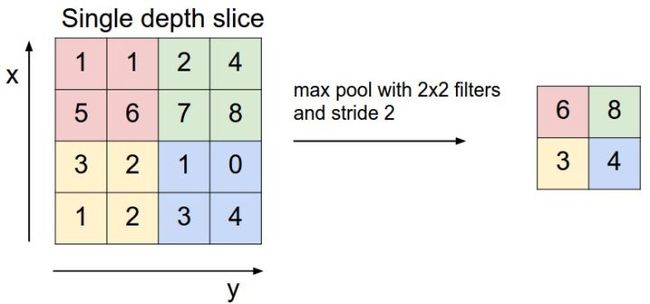
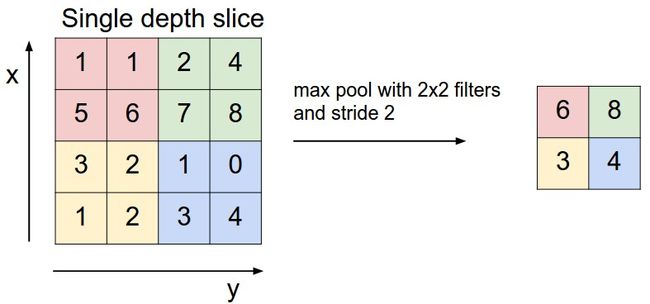
2.2.2 池化层
在卷积层之后往往会加入一层池化层,池化层可以有效缩小矩阵的尺寸,从而减少最后全连接层的参数,利用池化层既可以加速计算也可以减小过拟合。下图是池化层工作的示意图,使用一个尺寸为[图片上传失败...(image-aae9b9-1557814223444)]
的filter进行max pooling。
**2.2.3 经典卷积模型LeNet-5 **
卷积神经网络的特有结构为卷积层和池化层,通过这种网络结构组合而得的神经网络有无限多种,下面我们介绍一个经典的卷积模型LeNet-5 ,这个模型是在论文Gradient-based learning applied to document recognition中提出的,它是第一应用于数字识别的卷积神经网络,在MNIST数据集上LeNet-5模型上可以得到99.2%的准确率,它一共有7层结构:
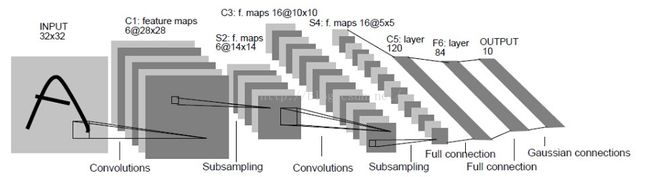
从左到右分别是:卷积、池化、卷积、池化、全连接、全连接、全连接。
2.2 CNN文本分类
上面章节简单对CNN进行了介绍,那回到我们的正题,继续说CNN和文本分类,我们以一篇经典的论文方法介绍下CNN是如何用于文本分类的(论文地址:https://arxiv.org/pdf/1408.5882.pdf)。
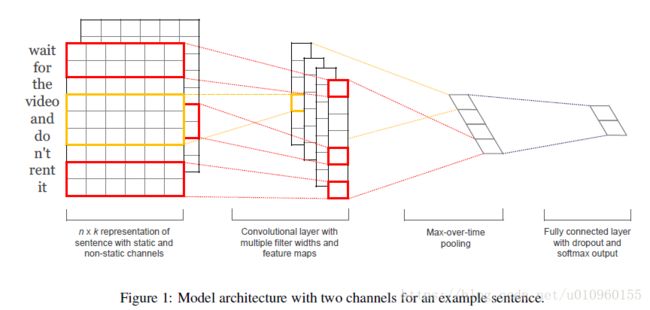
这篇论文提出的模型架构图如上,整体模型主要分为三个部分:输入层、卷积+池化层、全连接+softmax层。可以看出,这个模型跟我们前面介绍LeNet-5模型相比结构简单了许多,这也是由文本输入特殊性造成的。
2.2.1 输入层
输入层会将一段文本转换成卷积层所需要的输入格式,一般会得到一个三维的输入[图片上传失败...(image-a61c54-1557814223444)]
。
其中[图片上传失败...(image-82634d-1557814223444)]
代表一段文本单词数量。因为文本的单词数量是变长的,在这里我们需要对输入文本做预处理,将其加工成定长。常用的方法有取数据中最长文本长度、统计文本长度分布取一个能覆盖大部分文本的长度。这里推荐第二种方法。
[图片上传失败...(image-6fd036-1557814223444)]
代表embedding的维度。每个单词的embedding可以使用word2vec或者GloVe训练好的词向量,比如这个网站上有使用GloVe模型训练好的词向量,地址:https://nlp.stanford.edu/data/,其中词向量维度有50,100,200,300维。当然也可以使用完全随机的词向量。不过一般实验证明,使用pre-trained词向量对于一般的NLP任务都有提升。
[图片上传失败...(image-1ef4bb-1557814223444)]
对于一个图像来说通常是3,代表RGB图片,对于文本来说,通常这个值为1。不过这篇文章中提出了一种multi-channel方法,将这个设置为2,其实就是将两种文本的不同来源的embedding拼到了一起,下面介绍下论文中提到不同embedding的方法
不同类型输入
|
|
|
| CNN-rand | 所有的word vector都是随机初始化的,同时当做训练过程中优化的参数 |
| CNN-static | 所有的word vector直接使用无监督学习即Google的Word2Vector工具(COW模型)得到的结果,并且是固定不变的 |
| CNN-non-static | 所有的word vector直接使用无监督学习即Google的Word2Vector工具(COW模型)得到的结果,但是会在训练过程中被Fine tuned |
| CNN-multichannel | CNN-static和CNN-non-static的混合版本,即两种类型的输入 |
2.2.2 卷积+池化层
经过输入层后,我们得到了表示文本的三维输入,它的形状为[图片上传失败...(image-46335-1557814223443)]
,接下来我们对输入进行卷积操作。卷积filter的尺寸为[图片上传失败...(image-e716d2-1557814223443)]
,其中[图片上传失败...(image-3e45c7-1557814223443)]
代表filter长度,也就是每次处理文本中单词的数量;[图片上传失败...(image-8243a1-1557814223443)]
代表embedding的维度;[图片上传失败...(image-3be78c-1557814223443)]
代表filter的深度,我们可以使用不同的[图片上传失败...(image-255b48-1557814223443)]
分别进行卷积来提取更多的特征。可以看出每次卷积的时候都是整行整行的进行。当[图片上传失败...(image-6b5203-1557814223443)]
可以理解为unigram特征,[图片上传失败...(image-785ccc-1557814223443)]
的时候就是bigram特征。在卷积层我们分别采取[图片上传失败...(image-b419e5-1557814223443)]
进行卷积就得到了三个feature map,每个feature map的长度跟原文本的长度相关,宽度为[图片上传失败...(image-b56d23-1557814223443)]
,经过卷积层后我们就提取到了原文本的n-gram相关特征。
在池化层采用了max-pooling的方法,池化层的filter的[图片上传失败...(image-ef9c30-1557814223443)]
,其中[图片上传失败...(image-837cf6-1557814223443)]
代表对文本卷积后feature map的长度。经过池化后feature map的维度会降为1,因此pooling结束后,得到向量的维度就是[图片上传失败...(image-7311e4-1557814223443)]
,这样就得到整个文本的特征表示。
这个模型只使用了一层卷积+一层池化,跟LeNet-5模型相比,还是太过于简单了,但是从paper中的实验来看,这个模型性能已经很好了,那么问题来了
- CNN用于文本可以采用多层卷积+池化的结构吗?
- CNN提取的特征究竟代表什么意义?
- max-pooling的方法过于简单粗暴,有没有什么别的方法?
2.2.3 全连接+softmax层
经过卷积池化后我们得到了表示文本的特征向量,然后再经过一个全连接+softmax层就得到了代表属于不同类别的概率向量,也就完成了分类的工作。
三、实验结果
贴一个原文的实验结果:
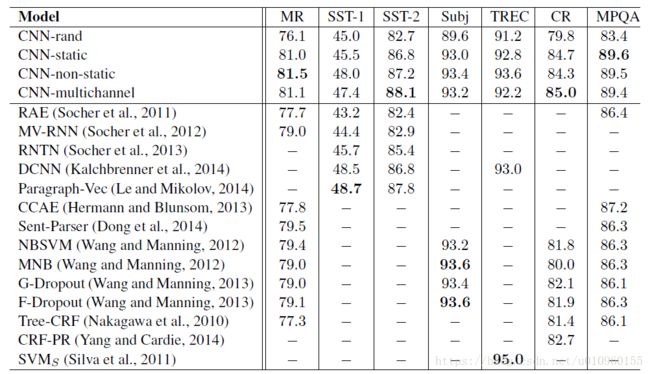
- pre-trained词向量能明显提升分类效果,可以看出CNN-static是明显好于CNN-rand的结果
- CNN-multichannel在小数据集上好于CNN-singlechannel。作者初始是希望multichannle避免过拟合,是词向量尽量不要偏离原始预训练好的词向量同时也使词向量适应于具体的任务
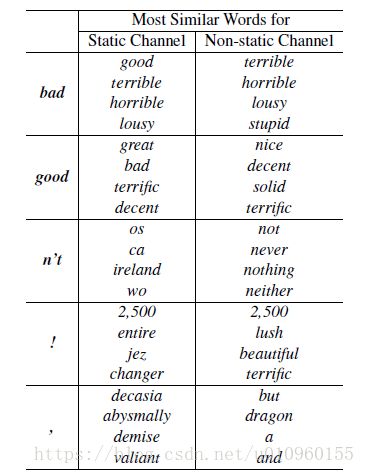
- CNN-non-static比大部分CNN-static好,说明适当fine-tune是有用的,使词向量适当适应具体任务,如下表所示,对于'bad'这个词,static channel将'good'作为邻居词,这对情感分析类的任务是不太准确的。而Non-static channel经过fine tune就得到‘terrible’的邻居词,这跟情感分析任务是对应的。
下面给出一些调参技巧,出自https://blog.csdn.net/memray/article/details/51454208
下面总结一下Ye Zhang等人基于Kim Y的模型做了大量的调参实验之后的结论:
- 由于模型训练过程中的随机性因素,如随机初始化的权重参数,mini-batch,随机梯度下降优化算法等,造成模型在数据集上的结果有一定的浮动,如准确率(accuracy)能达到1.5%的浮动,而AUC则有3.4%的浮动;
- 词向量是使用word2vec还是GloVe,对实验结果有一定的影响,具体哪个更好依赖于任务本身;
- Filter的大小对模型性能有较大的影响,并且Filter的参数应该是可以更新的;
- Feature Map的数量也有一定影响,但是需要兼顾模型的训练效率;
- 1-max pooling的方式已经足够好了,相比于其他的pooling方式而言;
- 正则化的作用微乎其微。
Ye Zhang等人给予模型调参者的建议如下:
- 使用
non-static版本的word2vec或者GloVe要比单纯的one-hot取得的效果好得多; - 为了找到最优的过滤器(Filter)大小,可以使用线性搜索的方法。通常过滤器的大小范围在
1-10之间,当然对于长句,使用更大的过滤器也是有必要的; -
Feature Map的数量在100-600之间; - 可以尽量多尝试激活函数,实验发现
ReLU和tanh两种激活函数表现较佳; - 使用简单的
1-max pooling就已经足够了,可以没必要设置太复杂的pooling方式; - 当发现增加
Feature Map的数量使得模型的性能下降时,可以考虑增大正则的力度,如调高dropout的概率; - 为了检验模型的性能水平,多次反复的交叉验证是必要的,这可以确保模型的高性能并不是偶然。
四、代码实现
CNN文本分类的tensorflow实现
执行训练
使用随机初始化的词向量进行训练
python train.py --input_layer_type 'CNN-rand'
使用与训练好的GloVe 词向量训练,在训练过程中词向量不可训练,是固定的
python train.py --input_layer_type 'CNN-static'
使用与训练好的GloVe 词向量训练,在训练中微调词向量
python train.py --input_layer_type 'CNN-non-static'
使用两个词向量组成双通道作为输入,一个固定,另一个可以微调
python train.py --input_layer_type 'CNN-multichannel'
Preference
https://www.analyticsvidhya.com/blog/2018/04/a-comprehensive-guide-to-understand-and-implement-text-classification-in-python/
http://www.jeyzhang.com/cnn-apply-on-modelling-sentence.html
http://www.cnblogs.com/yelbosh/p/5808706.html