这是苹果官方文档 Core Data Programming Guide 的渣翻译。
Faulting可以降低通过在持久化存储中保留占位对象(faults)的方式来降低应用内存的使用。有一个叫uniquing的相关特性能确保上述功能,在一个既定的托管对象上下文中,一条既定记录只会有一个托管对象。
Faulting限制了对象图的大小
托管对象代表了持久化存储中的数据。在某些情况下托管对象可能是一个fault —— 一个还没有从外部数据存储中加载到属性值的对象。Fualting降低了应用的内存消耗。一个fault是一个表示了一个尚未完全实现的托管对象,或是一个表示了一个关系的集合对象。
- 一个托管对象fault是一个相应类的实例,但是它的持久化变量还没初始化。
- 一个关系fault是表示了这个关系的集合类的子类。
Faulting允许Core Data在对象图上放置边界。因为一个fault是没有被实现的,一个托管对象fault消耗更少的内存,并且关联到一个fault的托管对象完全不需要表示在内存中。
为了说明这一点,可以想象一个应用允许一个用户去查询并编辑一个“雇员”的详情。这个“雇员”有一个关系是指向一个“经理”和一个关系指向一个“部门”,并且这些对象反过来也有其他关系。如果你在持久化存储中仅仅查询一个“雇员”,它的“经理”、“部门”和“报告”关系都是用faults初始化表示的。图13-1展示了使用fault来表示的“部门”关系。
图13-1 一个使用fault表示的“部门”
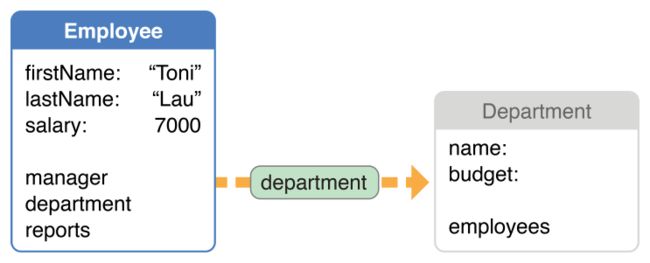
虽然这个fault是一个“部门”类的实例,但是它并没有被实现 —— 任何一个它的持久化实例变量都还没被设定。这就意味着不单单“部门”对象消耗更好的内存,并且不需要填充它的“雇员”关系。如果需要让对象图变得完整,那就编辑一个“雇员”的一个属性,它最后就会去创建对象来表示整个结构。
Firing Faults
Fault处理是直接的 —— 你不需要执行任何查询来实现一个fault。如果在某些场合一个fault对象的持久化属性被访问到了,那么Core Data就会自动查询数据来初始化对象。这个过程一般被称为“fire the fault”。如果你访问“部门”对象上的一个属性,例如“名字”,那么这个fault就会被fire —— 并且在这种情况Core Data会为你执行一个查询来检索到所有的对象属性。
Core Data在一个fault的一个持久化属性(例如“名字”)被访问到的时候fire fault。然而,一个个地fire fault是十分低效的,并且有更好的策略来从持久化存储中拿到数据(参考Decreasing Fault Overhead)。想要更高效处理fault和关系,可以参考Fetching Managed Objects和Preventing a Fault from Firing。
当一个fault被fire,如果这个数据在缓存中可用Core Data不会再去存储中获取。使用缓存命中,转换一个fault为一个已实现的托管对象是非常快的 —— 就像普通的托管对象被实例化一样。如果这个数据不在缓存中可用,Core Data会自动为这个fault执行查询;这就能从持久化存储中获取数据,并再次放进内存中。
一个对象是否是fault简单地意味着一个既定的托管对象是否拥有已被包装好的持久化属性和已经准备好被使用。如果你需要判断一个对象是否是fault,可以调用它的“isFault”方法,这个方法不会fire这个fault(没有访问任何关系或属性)。如果“isFault”返回“NO”,那么这个数据应该存在内存中并且不是fault。然后,如果“isFault”返回“YES”,并不能简单认为这个数据不在内存中。这个数据可能存在内存中,或者不存在,取决于许多影响到缓存机制的因素。
虽然“description”方法不会引起fault被fire,但是如果你实现了一个自定义的“decription”方法并访问了对象的持久化属性,那么这个fault会被fire。强烈不建议你用此方式覆写“description”。
不可以根据需要只加载托管对象中的某些属性,而不实现整个对象(查询所有属性值)。关于如何处理大数据属性,参考 Binary Large Data Objects (BLOBs)。
转换对象为Fault
转换一个已实现的对象为fault对于整理对象图来说是十分有用的,也能确保属性值是同步的。转换一个托管对象为fault释放不必要的内存,并设置它的内存属性值为nil。(参考Reducing Memory Overhead并保证数据时最新的)。
你可以使用"refreshObject:mergeChanges:"方法转换一个已实现对象为fault。如果你传递"NO"作为“mergeChanges”参数,你必须确保这个对象的关系没有变更。否则,当你保存了这个上下文的时候,你会引发持久化存储的引用的完整性问题。
当一个对象转变成为了fault,它的"didTurnIntoFault"方法就会被调用。你可能实现了一个自定义“didTurnIntoFault”方法来实现一些清理工作功能。例如,保证数据是最新的。
注意
Core Data避免使用属于“unfaulting”因为它具有迷惑性。不能说“unfaulting”一个虚拟内存事件fault。
事件fault可以是被触发、引发、fire(激发?)或者碰到。
当然,你可以通过不同的方法来释放内存。Core Data称之为转换一个对象为fault。
Fault和KVO通知
当Core Data转换一个对象为fault,key-value observing(KVO)变更通知就会发送到这个对象的属性上。如果你正在观察一个被转换成了fault的对象的属性,并且这个fault突然被实现化了,你会收到其实值并没有真正改变的属性的变更通知。参考Key-Value Observing Programming Guide。
虽然这些值从你的角度来看并没有发生改变,但是在内存中随着对象的具现化,其实每个字节都发生了改变。KVO机制要求无论在任何时候只要根据对比指针判断值发生了改变,Core Data都要发出通知。KVO需要这些通知来跟踪跨key path和依赖对象的改变。
Uniquing确保一个托管对象对应一个上下文中的一条记录
Core Data确保,在一个托管对象上下文,一个持久化存储中的实体是和唯一一个托管对象关联的。这个技术就是uniquing。如果没有uniquing,你可能要无休止处理一个上下文中超过一个托管对象表示同一条记录。
例如,试想如图13-2展示的情景;两个“雇员”被加载到了一个托管对象上下文中。每个“雇员”都有一个"部门"关系,但是这时候“部门”是fault。
图13-2 独立的“部门”对象fault

这看起来就是每个“雇员”都有一个独立的“部门”,并且如果你调用每个“雇员”的“部门” —— 转换“部门”fault称为普通对象 —— 你就会得到两个在内存中独立的“部门”。然而,如果两个“雇员”都属于同一个“部门”(例如,市场部),然后Core Data要确保在一个既定的托管对象上下文中只有一个对象表示“市场部”。如果两个“雇员”都属于同一个部门,他们的“部门”关系都应该引用同一个fault,就如图13-3展示的那样。
图13-3 表示两个“雇员”共同工作的“部门”的唯一fault
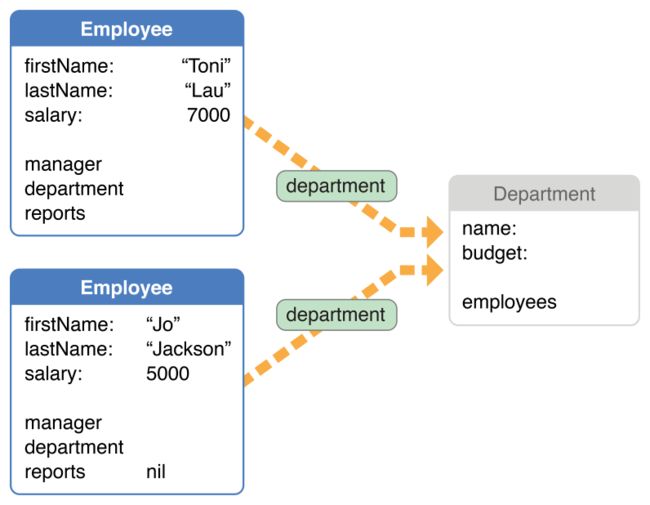
如果没有uniquing,当你获取每个“雇员”并且调用“部门”的时候 —— 从而要fire每个对应的fault —— 一个新的“部门”对象每次都会被创建出来。这样会导致出现很多对象,每个都表示同一个“部门”,可能会导致不同步的、冲突的数据。当上下文保存的时候,就不能保证正确的数据能够提交到存储中。
更通俗地说,在一个既定的上下文中,所有表示“市场部”的托管对象都指向同一个实例 —— 他们拥有相同的“市场部”数据视图 —— 即使这个“市场部”是个fault。
注意
这次讨论主要是围绕单个托管对象上下文的。每一个托管对象上下文都表示一个不同的数据视图。
如果同一个“雇员”加载到了第二个上下文,那么他们 —— 并且对应的所有“部门”对象 —— 都在对象中表现成不同的对象。
在不同的上下文的中对象可能存在不同的、冲突的数据。这恰恰是Core Data架构的任务,同时去检测、解决这些冲突。