根据极光日报2018 年人工智能 AI 指数报告指出,今年人工智能「达到或超越人类表现」的重要进展 —— 包括微软汉英双语机器翻译系统在有关测试中达到人类水平、谷歌的深度学习系统在前列腺癌有关诊断研究中准确率超过美国认证病理医生等。除了这些应用之外,谷歌还与纽约时报进行合作通过AI对照片进行数字化。
100 多年来,下面这个位于时代广场办公室附近的数百个文件柜中,存放了超过 500 万张照片,这里被称为「morgue」。虽然卡片目录提供了存档内容的概述,但是照片中的许多内容都没有进入索引,而是尘封在这里。纽约时报》与 Google Cloud 合作,在其档案中对 500 万至 700 万张旧照片进行数字化处理。Google 的人工智能将负责在大量的历史图像中发掘背后「不为人知的故事」。
这个系统除了将照片以高分辨率存储在云中之外,还将识别文本、手写以及使用物理打印件找到的其他数据。

通过 Google Vision 识别后,能够在正反两面提取出文本:
NOV 27 1985
JUL 28 1992
Clock hanging above an entrance to the main concourse of Pennsylvania Station in 1942, and, right, exterior of the station before it was demolished in 1963.
PUBLISHED IN NYC
RESORT APR 30 ‘72
The New York Time THE WAY IT WAS – Crowded Penn Station in 1942, an era “when only the brave flew – to Washington, Miami and assorted way stations.”
Penn Station’s Good Old Days | A Buff’s Journey into Nostalgia
( OCT 3194
RAPR 20072
PHOTOGRAPH BY The New York Times Crowds, top, streaming into the old Pennsylvania Station in New Yorker collegamalan for City in 1942. The former glowegoyercaptouwd a powstation at what is now the General Postadigesikha designay the firm of Hellmuth, Obata & Kassalariare accepted and financed.
Pub NYT Sun 5/2/93 Metro
THURSDAY EARLY RUN o cos x ET RESORT
EB 11 1988
RECEIVED DEC 25 1942 + ART DEPT. FILES
The New York Times Business at rail terminals is reflected in the hotels
OUTWARD BOUND FOR THE CHRISTMAS HOLIDAYS The scene in Pennsylvania Station yesterday afternoor afternoothe New York Times (Greenhaus)
本文将简单介绍一下谷歌数字化照片用到的AI技术之一,OCR文本识别技术,以及谷歌推出的一个开源的识别工具tesseract。
ocr:光学字符识别
ocr,说的简单点就是把图片中的文字找出来,并转换成文本形式。也许有人会说,这玩意也叫ai,人可以很简单的就从图片中找出文本,但是对于计算机来说,就是这么一个简单的玩意,从1929年提出来至今,还没有一个算法能够达到人类识别的水平。因为计算机和人类看到的图片并不一样,它是用数字对一幅图像进行表示。

人眼看到的图像
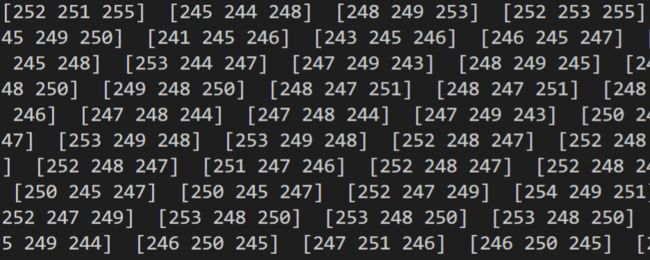
计算机中的图像
是不是看到全部是数字后头也大了,下面将介绍一个谷歌的开源工具tesseract,可以将图像中的文字,变成可以操作的文本。
tesseract的简单介绍
先简单介绍下tesseract,这个库最早是由惠普在1985年进行开发的,在2005年进行开源,并在2006年交由谷歌进行维护,最新的版本是2018.10.29发布的,可以先看下国内外的小伙伴对这个库的评价。

国内某乎小伙伴评价

国际友人评价
当然,不能通过几个人的评价就说tesseract是全世界最好的开源库,但是目前来说,在通用性和使用范围上来说,tesseract的确是开源中做的比较好的项目。
下面简单介绍下tesseract的使用,它是用c++写的,但是对python也有很好的支持(人生苦短,我用python),不管你使用win,mac还是linux,tesseract的安装都是比较简单的,可以在网上轻易搜到,下面主要讲下它的使用。
text=pytesseract.image_to_data(img)

没错,就一行代码,就可以把一张照片中的文本提取出来,但是,这个输出,呃...
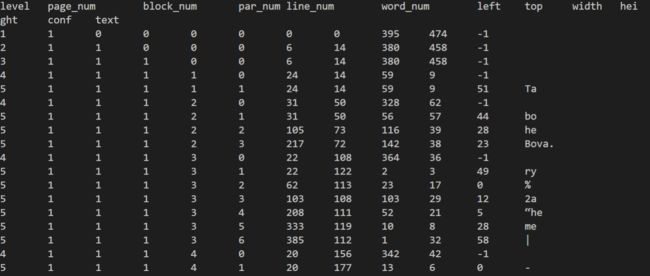
tesseract输出
先不慌,解释下最有用的几个字段,left、top表示这个文字的左上角坐标,width、height表示这个文字占的长和宽,text表示tesseract识别出的文本,有了这些信息,我们可以在图像中把这些都标识出来。

tesseract识别结果
这个结果,呃,乍一看杂乱无章,仔细一看,还是稍微能看出点什么,比如Penn Station’s Good Old Days都识别出来了,但是也可以看出,还有一些文字并没有被识别出或者识别错误。
本文只是简单介绍了一下ocr技术记忆tesseract库,对于一些核心内容并没有涉及,但是可以看出,强如谷歌,也没有完全解决ocr识别问题(不过谷歌有付费ocr的sdk,识别效果肯定比免费的好,但是笔者测试过,识别在某些情况,还是会出现错误),所以说,人工智能目前还远远没有达到和人一样智能的地步,但是在某些方面,已经可以替代一些人类的工作,希望对人工智能有兴趣的小伙伴可以继续关注着相关技术的发展,并贡献自己的一份人工。
tesseract源码地址:https://github.com/tesseract-ocr/tesseract
本文为极光征文参赛文章。