
需求背景
使用dismax查询的特点在于说,可以比较综合的考虑字段得分来进行打分。假设我有以下数据
{
"title": "阿根廷小组未能出线",
"content": "今天小组赛结束,阿根廷输给尼日尼亚"
}
那么dismax的查询方式是会比较在字段title和字段content上的得分,得分最大的做为整个文档的得分。如果还不了解dismax的计算方式可以先去谷歌看看文档了解一下,本文从这里开始。
接下来要提一个新需求,我需要得到dismax在title和content上分别的得分,这个得分后续可能用于做一些新的排序和召回的计算,总之我现在希望在查询的时候我能返回这两个字段分别的得分。
总结下我们的需求,浓缩成简单的一句话:拿到title和content在dismax查询下的得分。
方案设计
总结清楚了需求和目的,那么接下来就是设计方案的时候,首先我考虑以下几种方案
- 通过explain参数拿到explain后解析
- 通过aop方式代理类来优雅的修改逻辑
- 直接去源代码找到想要的东西
经过几天不懈的努力,终于证明了三种方式其实都不怎么可行,其中3我做出来了,但是我也不忍直视自己究竟修改了多少源代码,也只是1方式的复杂版。但是这一次源代码探索之旅是学习到很多东西的,也希望有一天成为开源贡献者。
那么本篇主要讲方法3
源码探索
首先做一个猜测,每个分数和字段都是一一对应的,score->field,那么我找到分数在代码中的位置很可能就能找到字段值
看看我的查询体
{
"explain": "true",
"from": 0,
"size": 1,
"query": {
"function_score": {
"query": {
"bool": {
"should": [
{
"dis_max": {
"boost": 3,
"queries": [
{
"match": {
"appNgram1": {
"query": "懒人投资",
"type": "boolean",
"boost": 2.5
}
}
},
{
"match": {
"appNgram2": {
"query": "懒人投资",
"type": "boolean",
"boost": 1.2
}
}
}
]
}
}
]
}
},
"functions": []
}
}
}
一段很典型的dismax query
回顾我们的目标,我们要拿到每个字段的分数,那么哪里能看得到分数呢?explain即可(以下是实际数据的分数情况)
"_explanation": {
"value": 5.177436,
"description": "max of:",
"details":……
max of:表示使用max运算,即取最大值的运算。OK我们展开下面的选项,可以很清晰的看到懒人投资四个字分词后分别在每个appNgram1和appNgram2的得分。其实好像我们已经拿到了分数?看下图
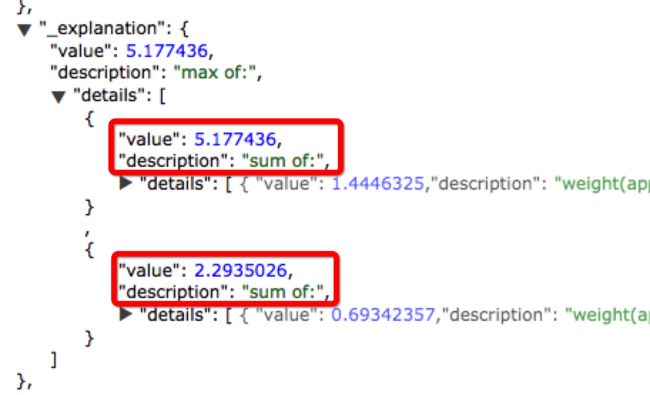
两个分数我们无从得知到底哪个分数是appNgram1还是appNgram2。再展开后的是分词后的每个单字在字段中的得分。到这一步,便会产生这样的想法,是不是源代码中可以通过简单的修改添加一两行代码把field显示出来?
很顺利的找到了dismax比较分数的位置,如下
package org.apache.lucene.search;
import org.apache.lucene.index.Term;
import java.io.IOException;
import java.util.List;
public class DisjunctionMaxScorer extends DisjunctionScorer {
/* Multiplier applied to non-maximum-scoring subqueries for a document as they are summed into the result. */
private final float tieBreakerMultiplier;
/**
* Creates a new instance of DisjunctionMaxScorer
*
* @param weight
* The Weight to be used.
* @param tieBreakerMultiplier
* Multiplier applied to non-maximum-scoring subqueries for a
* document as they are summed into the result.
* @param subScorers
* The sub scorers this Scorer should iterate on
*/
DisjunctionMaxScorer(Weight weight, float tieBreakerMultiplier, List subScorers, boolean needsScores) {
super(weight, subScorers, needsScores);
this.tieBreakerMultiplier = tieBreakerMultiplier;
}
@Override
protected float score(DisiWrapper topList) throws IOException {
float scoreSum = 0;
float scoreMax = 0;
for (DisiWrapper w = topList; w != null; w = w.next) {
final float subScore = w.scorer.score();
scoreSum += subScore;
if (subScore > scoreMax) {
scoreMax = subScore;
}
}
return scoreMax + (scoreSum - scoreMax) * tieBreakerMultiplier;
}
}
代码中比较大小处就是dismax分数计算的逻辑,OK分数找到了,那么再找到字段名岂不是皆大欢喜?
没有
debug到图中比较大小的位置,完全无法找到任何field的信息,完全不知道到底是计算哪个字段的分数。topList相当于一个iterator的迭代器,找不到任何字段信息。本来好像近在咫尺,只好做罢。
接下来再看看打分类
……省略
public final class Explanation {
……省略
private final boolean match; // whether the document matched
private final float value; // the value of this node
private final String description; // what it represents
private final List details; // sub-explanations
/** Create a new explanation */
private Explanation(boolean match, float value, String description, Collection details) {
this.match = match;
this.value = value;
this.description = Objects.requireNonNull(description);
this.details = Collections.unmodifiableList(new ArrayList<>(details));
for (Explanation detail : details) {
Objects.requireNonNull(detail);
}
}
……省略
}
只看构造函数,我们很清晰的看得出打分类的构造,通过debug发现,details中包含着子类的打分 ,很明显的树状数据结构,可以递归获取整棵打分树。那么这里能不能拿到对应的字段呢?
还是没有
唯一的String类型变量description,是操作描述符,就是前面的max of:,sum of:等等 ,details是树的子节点,value是分数,match是否匹配文档。又失败了。
两个地方都没找到,我开始怀疑我之前的思路是否正确,我重新观察了一下代码和查询出来的结果,得出新的结论。
分数和字段不是一一对应的,dismax运行在appNgram1字段上其实是分解为
appNgram1:懒 appNgram1:人 appNgram1:投 appNgram1:资我想要的分数是appNgram1:懒 + appNgram1:人 + appNgram1:投 + appNgram1:资,在es的设计概念中并不存在这个分数对应哪个字段,即使我们肉眼可见全部是在appNgram1上搜索,但就是拿不到。
换句话说,对于ES来说,并不存在我猜测的有存储score->field这样的映射关系,实际上的映射关系是这样的score->field x:term y(x=0,1,2,3……,y=0,1,2,3……)。需求出错了。
但是在我需要的特定场景下,比如dismax的query下,我可以认为我的x是恒定不变的,比如上面的数据中,我所有的term都是在appNgram1这个字段下进行TFIDF计算。那么接下来的思路逻辑虽然很丑陋,却成了不得不做的事情。我原来希望可以不入侵的方式修改源代码,来达到解耦,但是遍寻不到路后也不能坐以待毙,开始尝试暴力修改。
源码修改
这里关于修改源码的两个方式要说一下,也是为以后定制开源组件做准备。
- 通过aop方式的修改(aspectJ)
aop我不多介绍,相较于暴力的修改源码,aop方式不但干净而且解耦,如果依赖升级的情况下自身升级也相对容易。假设我如果需要拦截获取第三方jar包中方法或者类来进行修改的话我一定会选择这种方法。但是有两个缺点。
- 比如第三方jar包中的类或者方法定义为final的情况下是无法通过aspectJ来拦截的,究其原因是java本身语法上已经定义了final是无法派生出新的东西的。
- 能改动的逻辑也比较有限,适合轻度修改做补丁之类的工作。
- 直接修改源代码
这里有个问题,第三方依赖包在工程中是以jar包->class文件存在的,是只读(read-only)文件,我们可以通过反编译或者像IDEA一样可以直接去maven仓库下载源代码,通过ctrl+鼠标左键来阅读源代码,但是无法修改。这里有两个方法
- 在工程目录下建立和要修改的类同包名类名的文件,然后将其源代码拷贝过来,编译后拿class文件替换掉jar包内的class文件。
- 在工程目录下建立和要修改的类同包名类名的文件,然后将其源代码拷贝过来,然后就可以直接编译使用,工程内的class文件在classloader中的优先级是比第三方jar包来得高的。这个方法要注意一件事,es的源代码是有做jar包冲突检验的,如果像刚才说的这么做会报
jar hell!。所以要先做注释掉检查包冲突的代码,具体代码在org.elasticsearch.bootstrap.JarHell中,注释掉154行开始的public static void checkJarHell(URL urls[]) throws Exception这个方法即可。
由于修改的代码太多实在放不过来我只说下思路
做完上述准备工作后开始考虑怎么修改。我想要的是score->field这样的映射关系,目前我知道score的位置,但没有field,所以我的考虑是在org.apache.lucene.search.Explanation这个类中增加一个field的字段,在计算得分的时候同时保存得分来自于哪个字段。以下是修改过的Explanation类的构造函数
/** Create a new explanation */
private Explanation(boolean match, float value, String description, Collection details, String field) {
this.field = field;
this.match = match;
this.value = value;
this.description = Objects.requireNonNull(description);
this.details = Collections.unmodifiableList(new ArrayList<>(details));
for (Explanation detail : details) {
Objects.requireNonNull(detail);
}
}
DEBUG过程中查看哪个位置创建了Explanation,寻找field字段加入,比如下面的org.apache.lucene.search.BooleanWeight中经过我修改的explain方法
@Override
public Explanation explain(LeafReaderContext context, int doc) throws IOException {
……省略上面部分
if (fail) {
return Explanation.noMatch("Failure to meet condition(s) of required/prohibited clause(s)", subs);
} else if (matchCount == 0) {
return Explanation.noMatch("No matching clauses", subs);
} else if (shouldMatchCount < minShouldMatch) {
return Explanation.noMatch("Failure to match minimum number of optional clauses: " + minShouldMatch, subs);
} else {
//重点看这里 我修改的地方 当分数是来自于sum of:计算的时候我们会保留field信息到Explanation中
String field = "";
if (subs.size() > 0){
field = subs.get(0).field;
}
Explanation result = Explanation.match(sum, "sum of:",field, subs);
final float coordFactor = disableCoord ? 1.0f : coord(coord, maxCoord);
if (coordFactor != 1f) {
result = Explanation.match(sum * coordFactor, "product of:", field,
result, Explanation.match(coordFactor, "coord("+coord+"/"+maxCoord+")", field));
}
return result;
}
}
上述代码是类中explain部分,通过定制修改保留下field信息后,其实就相当于在最后获得的Explanation树中可以获得分数所属的field,还需要从lucene中挖出来修改的类包括DisjunctionMaxQuery,TermQuery,DisjunctionMaxScorer等等。最后要在org.elasticsearch.search.internal.InternalSearchHit中补充以下代码用于最后展示
@Override
public XContentBuilder toXContent(XContentBuilder builder, Params params) throws IOException {
……省略
//测试测试测试
if (explanation() != null){
builder.field("flag");
builder.startObject();
StringBuffer sb = new StringBuffer();
Explanation[] details = explanation().getDetails();
for (Explanation detail : details) {
if (detail.getDescription().contains("sum of:")
&& detail.field != null
&& !detail.field.equals("")){
// sb.append("field:" + explanation.field + " value:" + explanation.getValue());
builder.field(detail.field, detail.getValue());
}
}
builder.endObject();
}
if (innerHits != null) {
builder.startObject(Fields.INNER_HITS);
for (Map.Entry entry : innerHits.entrySet()) {
builder.startObject(entry.getKey());
entry.getValue().toXContent(builder, params);
builder.endObject();
}
builder.endObject();
}
builder.endObject();
return builder;
}
我们在拿到得分的时候寻找带有sum of:操作的子节点并构造到xcontent结构体
最后上一下最终结果
小结
到最后绕了非常远的道,但其实做成的原理和解析json的原理没什么区别,源代码改的七零八落,自己看着都觉得不舒服。但是这个尝试还是非常有必要的,我身体力行的翻了一遍es源码,把整个搜索链路研究清楚后,才能给出原来的需求是错误的结论,实践出真知。如果有想要讨论es源码的人非常欢迎联系我~我很乐意一起学习。