一.栈
1.栈的定义
栈是仅在表尾进行插入和删除操作的线性表
允许插入和删除的一段称为栈顶(top),另一端称为栈底(bottom),不含任何数据元素的栈称为空栈.栈是后进先出(Last In First Out)的线性表,简称LIFO结构.
它是一个线性表,也就是说,栈元素具有线性关系,即前驱后继关系.只不过它是一种特殊的线性表.定义中说在线性表的表尾进行插入和删除操作,这里表尾是指栈顶,而不是栈底
特殊之处:在于限制了这个线性表的插入和删除位置,它始终只在栈顶进行.栈底是固定的,最先进栈的只能在栈底
栈的插入操作.叫做进栈,也成压栈,入栈

进栈
栈的删除操作,叫做出栈,也有的叫做弹栈
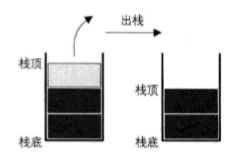
出栈
2.栈的抽象数据类型
ADT 栈(stack)
Data
InitStack (*S):初始化操作,建立一个空栈s
DestroyStack(*S):若栈存在,则销毁它
ClearStack(*S):将栈清空
StackEmpty(S):若栈为空,返回true,否则返回false
GetTop(S,*e):若栈存在,且非空,用e返回S的栈顶元素
Push(*S,e):若栈S存在,插入新元素e到栈S中并成为栈顶元素
Pop(*S,*e):删除栈D中栈顶元素,并用e返回其值
StackLength(S):返回栈S的元个数
endADT
3.栈的顺序存储结构
栈的定义
typedef int SElemType; //SEleType类型根据实际情况而定,这里假设为int
typedef struct{
SElemType data[MAXSIZE];
int top; //用于栈顶指针
}SqStack;
现在有一个栈,StackSize是5,下图是栈的普通情况,空栈,和栈满的情况
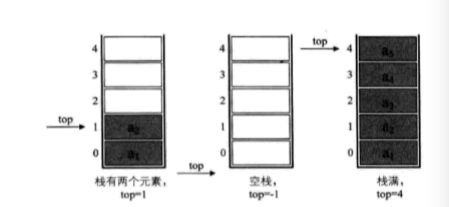
栈的状态
4.栈的顺序存储结构----进栈操作

进栈
//插入元素e为新的栈顶元素
Status Push (SqStack * S, SEleType e)
{
if (S -> top == MAXSIZE - 1) //栈满
{
return ERROR;
}
S -> top++; //栈顶指针增加1
S -> data[S -> top] =e;//将新元素赋值给栈顶空间
return OK;
}
时间复杂度为O(1)
5.栈的顺序存储结构---出栈操作
//若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK,否则返回ERROR
Status Pop (SqStack *S , SElemType *e)
{
if (s -> top == -1) //空栈
{
return ERROR;
}
*e = S -> data[S -> top];//将要删除的栈顶元素赋值给e
S -> top--;//栈顶指针-1
return OK;
}
时间复杂度为O(1)
6.栈的链式存储结构
栈顶放在单链表的头部,另外,都已经有了栈顶在头部,单链表中比较常见的头结点就失去了意义,通常对于链栈来说,就不需要头结点
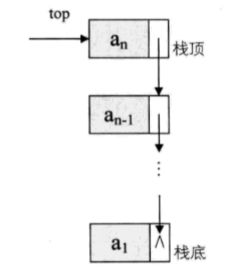
链栈
链栈的结构代码
typedef struct StackNode{
SElemType data;
struct StackNode *next;
}StackNode,*LinkStackPtr;
typedef struct LinkStack{
LinkStackPtr top;
int count;
}LinkStack;
7.栈的链式存储结构----进栈操作
假设元素值为e的新结点是s,top为栈顶指针

链式---进栈
//插入新元素e新的栈顶元素
Status Push (LinkStack *S, SEleType e)
{
LinkStackPtr s = (LinkStackPtr)malloc)(sizeof(StackNode));
s -> data = e;
s -> next = S -> top;//把当前的栈顶元素赋值给新结点的直接后继 如图1
S -> top = s;//将新的结点s赋值给栈顶指针,如图2
S -> count++;
return Ok;
}
时间复杂度为O(1)
8.栈的链式存储结构---出栈操作
假设变量p用来存储要删除的栈顶结点,将栈顶指针下移一位,最后释放p即可
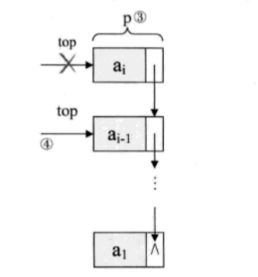
链式----出栈
//若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK,否则返回ERROR
Status Pop (LinkStack *S, SElemType *e){
LinkStackPtr p;
if (StackEmpty(*s))//栈的元素个数
return ERROR;
*e = S -> top -> data;
p = S -> top;//将栈顶结点赋值给p(找到要删除的元素)
S -> top = S -> top -> top;//将栈顶指针向下移一位,指向后一结点
free(p);
S -> count--;
return OK;
}
时间复杂度为O(1)
9.栈的顺序存储和链式存储的比较
他们的时间复杂度均为O(1).对于空间性能,
顺序栈需要实现知道一个固定的长度,可能会存在内存空间的浪费,但是存取时定位方便
链栈要求每个元素都有指针域,增加了内存开销,但是栈的长度无限制
如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,最好用链栈,反之,变化在可控范围内,使用顺序栈会更好
二.队列
1.队列的定义
队列是只允许在一端进行插入操作,而在另一端进行删除操作的线性表
队列是一种先进先出(First In First Out)的线性表,简称FIFO.允许插入的一端称为队尾,允许删除的一端称为队头

队列
2.队列的抽象数据类型
ADT 队列 (Queue)
Data
同线性表.元素具有相同的类型,相邻元素具有前驱和后继的关系
Operation
InitQueue(*Q):初始化操作,进行一个空队列Q
DestroyQueue(*Q):若队列Q存在,则销毁他
ClearQueue(Q):将队列Q清空
GetHead(Q,*e):若队列Q存在且非空,用e返回队列Q的队头元素
EnQueus(*Q,e):若队列Q存在,插入新元素e到队列Q中并成为队尾元素
DeQueue(*Q,*e):删除队列Q中队头元素,并用e返回其值
QueueLength(Q):返回队列Q的元素个数
endADT