一、MyCat简介
1.什么是MyCat?
MyCat 是目前最流行的基于 java 语言编写的数据库中间件,是一个实现了 MySQL 协议的服务器,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用 MySQL 原生协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分库分表。配合数据库的主从模式还可实现读写分离。
MyCat 官网:http://www.mycat.io/
MyCat 是基于阿里开源的 Cobar 产品而研发,Cobar 的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得 MyCat 变得非常的强大。
MyCat 发展到目前的版本,已经不是一个单纯的 MySQL 代理了,它的后端可以支持MySQL、SQL Server、Oracle、DB2、PostgreSQL 等主流数据库,也支持 MongoDB 这种新型NoSQL 方式的存储,未来还会支持更多类型的存储。而在最终用户看来,无论是那种存储方式,在 MyCat 里,都是一个传统的数据库表,支持标准的 SQL 语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
2.使用MyCat后的结构图:
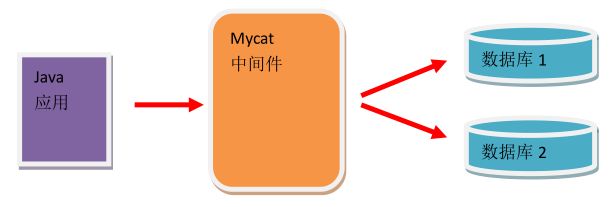
3.MyCat的优势:
(1)数据量级:
Mycat 可以管理若干 MySQL 数据库,同时实现数据的存储和操作。
(2)开源性质:
Mycat 是 java 编写的中间件. 开源,免费。
有非常多的人和组织对 Mycat 实行开发,维护,管理,更新。
Mycat 版本提升较快,可以跟随环境发展.如果有问题,可以快速解决。
Mycat 有开源网站和开源社区.且有官方发布的电子书籍。
Mycat 是阿里原应用 corba 转型而来的。
(3)市场应用:
Mycat 在互联网应用中占比非常高。
二、MyCat中的概念:
1.切分:
1.1 纵向切分/垂直切分:
就是把原本存储于一个库的数据存储到多个库上。由于对数据库的读写都是对同一个库进行操作,所以单库并不能解决大规模并发写入的问题。
例如,我们会建立定义数据库 workDB、商品数据库 payDB、用户数据库 userDB、日志数据库 logDB 等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
- 优点:
(1)减少增量数据写入时的锁对查询的影响。
(2)由于单表数量下降,常见的查询操作由于减少了需要扫描的记录,使得单表单次查询所需的检索行数变少,减少了磁盘 IO,时延变短。
- 缺点:
无法解决单表数据量太大的问题。
2.横向切分/水平切分:
把原本存储于一个表的数据分块存储到多个表上。当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,进行划分,然后存储到多个结构相同的表,和不同的库上。
例如,我们 userDB 中的 userTable 中数据量很大,那么可以把 userDB 切分为结构相同的多个 userDB:part0DB、part1DB 等,再将 userDB 上的 userTable,切分为很多 userTable:userTable0、userTable1 等,然后将这些表按照一定的规则存储到多个 userDB 上。
- 优点:
(1)单表的并发能力提高了,磁盘 I/O 性能也提高了。
(2)如果出现高并发的话,总表可以根据不同的查询,将并发压力分到不同的小表里面。
- 缺点:
无法实现表连接查询。
3.其他概念:
3.1逻辑库-Schema:
Mycat 中定义的 database.是逻辑上存在的.但是物理上是不存在的.
主要是针对纵向切分提供的概念。
3.2 逻辑表-table:
Mycat 中定义的 table.是逻辑上存在,物理上是不存在的;主要是针对横向切分提供的概念。
3.3 默认端口:
Mycat 默认端口是 8066。
3.4数据主机 - dataHost:
物理 MySQL 存放的主机地址.可以使用主机名,IP,域名定义。
3.5 数据节点 - dataNode:
配置物理的 database. 数据保存的物理节点.就是 database。
3.6分片规则:
当控制数据的时候,如何访问物理 database 和 table。
就是访问 dataHost 和 dataNode 的算法。
在 Mycat 处理具体的数据 CRUD 的时候,如何访问 dataHost 和 dataNode 的算法.如:哈希算法,crc32 算法等。
三、MyCat 的使用
1.MyCat解决的问题
1.1 读写分离:
原理:需要搭建主从模式,让主数据库(master)处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库(slave)处理 SELECT 查询操作。
Mycat 配合数据库本身的复制功能,可以解决读写分离的问题。
1.2主从备份:
什么是主从备份: 就是一种主备模式的数据库应用。
主库(Master)数据与备库(Slave)数据完全一致;
实现数据的多重备份, 保证数据的安全;
可以在 Master[InnoDB]和 Slave[MyISAM]中使用不同的数据库引擎,实现读写的分离。
1.3主从备份目的:
保证数据的安全;尽量避免数据丢失的可能。
使用不同的数据库引擎,实现读写分离.提高所有的操作效率。
InnoDB 使用 DML 语法操作. MyISAM 使用 DQL 语法操作。
1.4主从备份效果:
所有对 Master 的操作,都会同步到 Slave 中。
如果 Master 和 Salve 天生上环境不同 , 那么对 Master 的操作 , 可能会在 Slave 中出现错误。
如 : 在创建主从模式之前 ,Master 有 database : db1, db2, db3. Slave 有 database: db1,db2。
创建主从模式 . 现在的情况 Master 和 Slave 天生不同。
主从模式创建成功后 , 在 Master 中 drop database db3; Slave 中抛出数据库 SQL 异常;后续所有的命令不能同步。
一旦出现错误;只能重新实现主从模式。
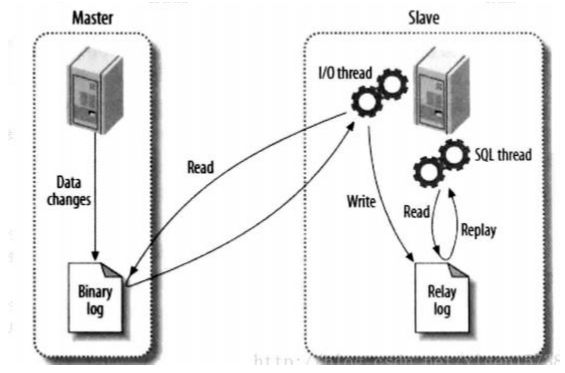
2.MySql 的主从模式搭建:
2.1安装MySQL环境:
将MySQL分别安装到两个Linux服务器中;
主库:192.168.226.130;
从库:192.168.226.128;
3.2主从备份配置:
- 修改Master主库配置文件:
命令:vim /etc/my.cnf;
修改内容: server_id 是MySQL 服务唯一标识;
配置要求:
server_id 任意配置,只要是数字即可; log_bin 值: master_log开启日志功能以及日志文件命名。
server_id Master 唯一标识数字必须小于 Slave从库 唯一标识数字。
- 重启MySQL:
service mysqld restart;
- 创建用户:
(1)先进入MySQL数据库中:mysql -uusername -ppassword;
(2)创建用户:此用户是从库访问主库使用的用户。
grant all privileges on *.* to 'myslave'@'192.168.226.128' identified by
'myslave' with grant option;
flush privileges;
- 查看用户:
use mysql;
select host, name from user;
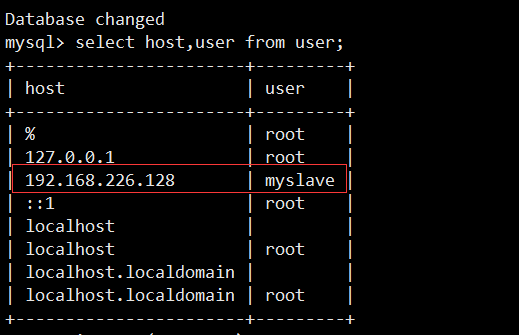
- 查看Master信息:
show master status;

3.2Slave从库配置:
- 修改Slave配置文件:
命令:vim /etc/my.cnf
添加唯一标识:server_id=2;
- 重启MySQL服务:
service mysqld restart;
- 配置主库信息:
(1)进入mysql数据库:mysql -uusername -ppassword;
(2)停止Slave功能:stop slave;
(3) 配置主库信息:需要修改的数据是依据Master信息修改的;ip是Master所在物理机IP. 用户名和密码是Master 提供的 Slave 访问用户名和密码,日志文件是在 Master 中查看的主库信息提供的;在Master 中使用命令 show master status 查看日志文件名称。
change master to master_host='192.168.70.148',master_user='myslave',
master_password='myslave',master_log_file='master_log.000001';
- 启动Slave功能:
start slave;
查看Slave配置:show slave status \G;
检查是否出现异常。
- 注意:
如果Linux服务器是克隆可能会出现下面的错误:
slave have equal MySQL Server UUIDs;清空auto.cnf文件下的内容。重启MySQL服务。
https://www.linuxidc.com/Linux/2015-02/113564.htm
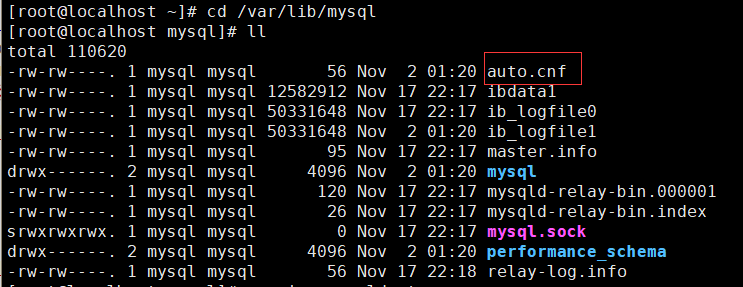
2.3测试主从:
也可以使用客户端工具。
- 创建库:
create database demo1 default character set utf8;
- 新建表:
CREATE TABLE `users` (
`id` int(11) NOT NULL,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 添加数据:
insert into users values(1,‘admin’)
3.安装MyCat:
3.1安装环境:
新建Linux服务器:192.168.226.129;
需要配置JDK;
- 在主从数据库中都要完成:
(1)开放 3306 端口或直接关闭防火墙;
(2)保证 root 用户可以被 mycat 访问:分别进入MySQL中执行下面命令;
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
3.2安装MyCat:
(1)上传并解压My擦通过压缩包:
tar -zxf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz;
(2) 将解压后的文件夹复制到/usr/local/下:
3.3MyCat目录介绍:
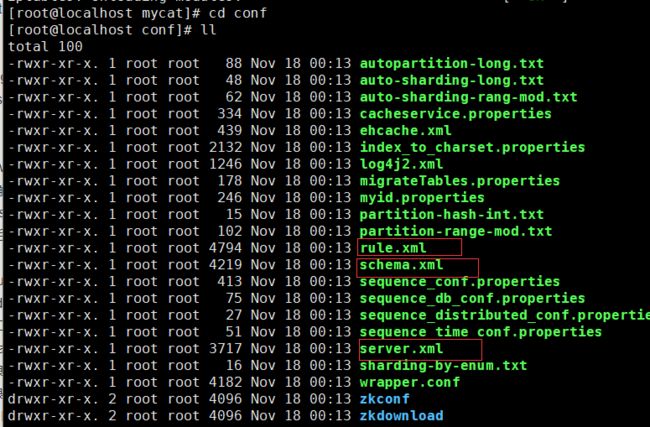
(1)bin 目录里是启动脚本。
(2)conf 目录里是配置文件。
(3)catlet 为 Mycat 的一个扩展功能。
(4)lib 目录里是 Mycat 和它的依赖 jar。
(5)logs 目录里是 console.log 用来保存控制台日志,和 mycat.log 用来保存 mycat 的 log4j日志。
4.MyCat 中的配置文件:
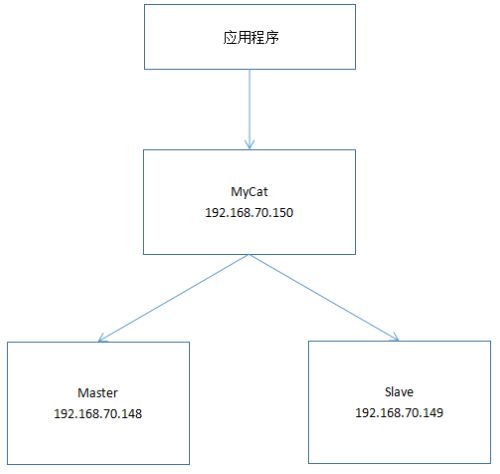
Mycat 的架构其实很好理解,Mycat 是代理,Mycat 后面就是物理数据库。和 Web 服务器的 Nginx 类似。对于使用者来说,访问的都是 Mycat,不会接触到后端的数据库。我们现在做一个主从、读写分离。结构如下图:
4.1Mycat 的配置文件都在 conf 目录下:

4.2 server.xml配置文件:
8066
9066
密码
用户可访问逻辑库名
密码
可访问逻辑库名
是否只读
-
配置 Mycat 服务信息:
 示例
示例 - 配置权限:
dml 权限顺序为:insert(新增),update(修改),select(查询),delete(删除),0000--> 1111,0 为禁止权限,1 为开启权限。

4.3schema.xml配置文件:
select user()
-
用于定义逻辑库和逻辑表的配置文件:
 示例
示例 - 节点和属性的作用:
(1)标签schema配置逻辑库的标签;
属性:
name:逻辑库名称;
checkSQLschema:是否检测 SQL 语法中的 schema 信息;
sqlMaxLimit:Mycat 在执行 SQL 的时候,如果 SQL 语句中没有 limit 子句.自动增加 limit 子句. 避免一次、性得到过多的数据,影响效率. limit子句的限制数量默认配置为100.如果SQL中有具体的limit子句,当前属性失效。
(2)标签 table:定义逻辑表的标签;
属性:
name:逻辑表名;
dataNode:数据节点名称,即物理数据库中的 database 名称;多个名称使用逗号分隔。
rule:分片规则名称.具体的规则名称参考 rule.xml 配置文件。
(3)dataNode:定义数据节点的标签;
属性:
name:数据节点名称, 是定义的逻辑名称,对应具体的物理数据库 database;
dataHost:引用 dataHost 标签的 name 值,代表使用的物理数据库所在位置和配置信息。
database:在 dataHost 物理机中,具体的物理数据库 database 名称。
(4)dataHost 标签:定义数据主机的标签
属性:
name:定义逻辑上的数据主机名称
maxCon/minCon:
最大连接数, max connections;
最小连接数, min connections;
dbType:数据库类型 ;
dbDriver:数据库驱动类型, native,使用 mycat 提供的本地驱动。
(5)dataHost 子标签 writeHost:写数据的数据库定义标签. 实现读写分离操作;
属性:
host:数据库命名;
url:数据库访问路径;
user:数据库访问用户名;
password:访问用户密码;
(6)writeHost 子标签 readHost:读数据的数据库定义标签;
属性:
host:数据库命名;
url:数据库访问路径
user:数据库访问用户名
password:访问用户密码;
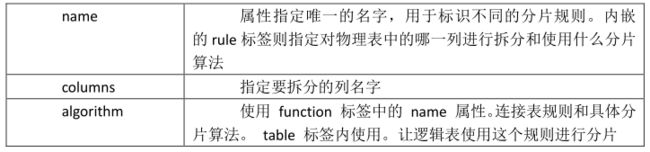
4.4rule.xml配置文件:
用于定义分片规则的配置文件。
mycat 默认的分片规则: 以 500 万为单位,实现分片规则;
逻辑库 A 对应 dataNode - db1 和 db2. 1-500 万保存在 db1 中, 500 万零 1 到 1000 万保存在 db2 中,1000 万零 1 到 1500 万保存在 db1 中.依次类推。
id
func1
-
tableRule:
 示例
示例 - function:
8
128

5.实现读写分离:
- 修改Schema.xml配置文件:
select user()
- 修改Server.xml配置文件:
123456
test
user
test
true
- 测试读写分离:
启动MyCat命令:bin/mycat start;
停止命令:bin/mycat stop;
重启命令:bin/mycat restart;
查看 MyCat 状态:bin/mycat status;
访问方式:客户端软件访问或者命令行访问:
mysql -u 用户名 -p 密码 -hmycat 主机 IP -P8066;链接成功后,可以当做 MySQL 数据库使用。
- 注意balance属性:
(1)balance=”0”, 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上;
(2)balance=”1”,全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡;
(3)balance=”2”,所有读操作都随机的在 writeHost、 readhost 上分发。
(4)balance=”3”, 所有读请求随机的分发到 writeHost 对应的 readhost 执行,writerHost不负担读压力。
6.MyCat实现分库:
6.1分片规则:
(1)auto-sharding-long 范围约定:
以 500 万为单位,实现分片规则。
逻辑库 A 对应 dataNode - db1 和 db2. 1-500 万保存在 db1 中, 500 万零 1 到 1000 万保存在 db2 中,1000 万零 1 到 1500 万保存在 db1 中.依次类推。
(2)crc32slot 规则:
在 CRUD 操作时,根据具体数据的 crc32 算法计算,数据应该保存在哪一个 dataNode 中。
- 需要注意的地方:
(1)
id 中推荐配置主键列;
(2)所有的 tableRule 只能使用一次。如果需要为多个表配置相同的分片规则,那么需要在此重新定义该规则。
(3)在 crc32Slot 算法中的分片数量一旦给定,MyCat 会将该分片数量和 slor 的取值范围保存到文件中。再次修改分片数量时是不会生效的,需要将该文件删除。文件位置位于 conf目录中的 ruledata 目录中。
6.2配置分库:
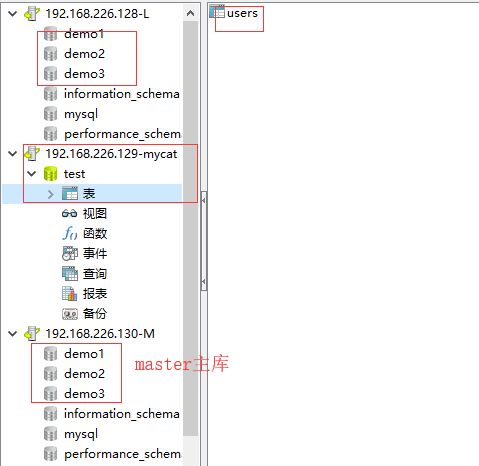
在客户端工具中测试;
在master主库连接中创建数据库;
在MyCat连接中创建表。
- 创建数据库:
create database demo1 default character set utf8;
create database demo2 default character set utf8;
create database demo3 default character set utf8;
- 创建表:
CREATE TABLE `users` (
`id` int(11) NOT NULL,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 修改Schema.xml配置文件:
select user()
-
结果:
 示例
示例 注意:
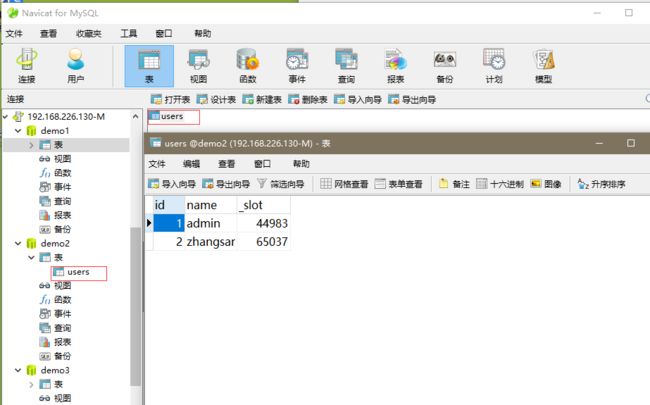
(1)使用 MyCat 实现分库时,先在 MyCat 中定义逻辑库与逻辑表,然后在 MyCat 的链接中执行创建表的命令必须要在 MyCat 中运行。因为MyCat 在创建表时,会在表中添加一个新的列,列名为_slot。
(2)使用 MyCat 插入数据时,语句中必须要指定所有的列。即便是一个完全项插入也不允许省略列名。