前言:
分布式存储系统需要让数据均匀的分布在集群中的物理设备上,同时在新设备加入,旧设备退出之后让数据重新达到平衡状态尤为重要。新设备加入后,数据要从不同的老设备中迁移过来。老设备退出后,数据迁移分摊到其他设备。将文件、块设备等数据分片,经过哈希,然后写入不同的设备,从而尽可能提高I/O并发与聚合带宽。
在实际场景中如何通过最小数据迁移使得集群恢复平衡,如何分配备份到设备上,使得数据尽可能的安全是很重要的问题。Ceph对普通哈希函数扩展后解决了上述问题,Ceph基于哈希的数据分布算法就是CRUSH。
CRUSH支持副本、Raid、纠删码数据备份策略,并受控的将数据的多个备份映射到集群不同故障域的底层设备上。
straw算法
最初提供了四种基本选择算法:

观察图中数据得到,unique执行效率最高,抵御结构变化能力最差,straw算法执行效率相较unique于tree要差,但是抵御结构变化的能力最强。因为数据可靠性最为重要,随着扩容引入越来越多的设备加上使用时间的推移,集群设备需要经常更换固件,因此目前基本生产环境的Ceph集群都选择straw算法。
straw算法为每个元素随机计算一个签长,选择签长最长的元素输出,签长越长的元素被选中的概率越大,数据落在上面的概率就越大。straw算法通过累计当前元素与前后元素的权重差值作为计算下一个元素签长的基准,因此在每次加入或删除osd时,都会引起不相干的数据迁移。后修改为签长计算仅与自身权重有关系,避免了这一现象,称为straw2算法,此算法目前为ceph的默认算法。
cluster map
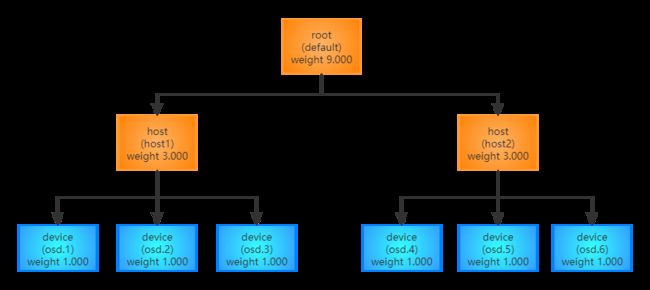
cluster map是集群层级拓扑结构的逻辑描述形式,其简单的拓扑如:数据中心->机加->主机->磁盘,因此cluster map采用树这种数据结构。根节点root是整个集群的入口;所有叶子节点device都是真实的最小物理存储设备(磁盘);中间节点bucket可以是device的集合,也可以是低级的bucket的集合。
cluster map这种层级关系通过
简单图示如下,最下面的叶子节点device(如磁盘)存放数据,中间是host类型的bucket(物理主机),最上面root是集群入口:
配置示例:
host default_10.10.10.125 { # 类型host,名字为default_10.10.10.125
id -3 # bucket的id,root与bucket的数字标识都为负值,只有device是 非负的数字标识,表明device是承载数据的真实设备。
# weight 14.126 # 权重,默认为子item的权重之和
alg straw2 # bucket的随机选择算法,这里用 straw2
hash 0 # rjenkins1 # 使用hash函数rjenkins1
item osd.0 weight 6.852 # osd.0的权重
item osd.1 weight 7.274 # osd.1的权重
}
placement rule
cluster map定义了存储集群的物理拓扑描述。placement rule完成数据映射,即决定一个PG的对象副本如何选择的规则,用户可自定义副本在集群中的分布。
placement rule可含有多个操作,包括以下三种类型:
-
take:从cluster map中选择指定编号的bucket,系统默认为root类型的节点
-
select:接收take输入的bucket,从中随机选择指定类型和数量的item。
step [choose|chooseleaf] [firstn|indep]type [choose|chooseleaf]:choose操作有不同的选择方式
- choose选择出Num个类型为bucket-type的子bucket
- chooseleaf选择出Num个类型为bucket-type的子bucket,然后递归到叶子节点选择一个OSD设备
[firstn|indep]:ceph有两种select算法(均为深度优先遍历)。不同之处在于纠删码要求的结果是有序的,因此如果指定输出数量为4而无法满足时:
- firstn(多副本):[1,2,4]
- indep(纠删码):[1,2,CRUSH_ITEM_NONE,4]
[Num] :
- Num == 0,选出的子buket为pool设置的副本数
- pool副本数 > Num > 0,选出的子buket为Num
- Num < 0, 选出的子buket为pool设置的副本数减去Num的绝对值
[type] :故障域的类型,如果为rack,保证选出的副本都位于不同机架的主机磁盘上,如果为host,则保证 选出的副本位于不同主机上。
如果选中条目因故障、冲突等原因无法使用,则会重新执行select。
-
emit:输出选择结果
配置示例:
rule {
id [a unique whole numeric ID]
type [ replicated | erasure ]
min_size
max_size
step take [class ]
step [choose|chooseleaf] [firstn|indep] type
step emit
}
rule data {
ruleset 0 //ruleset 编号
type replicated //多副本类型
min_size 1 //副本最小值为1
max_size 10 //副本最大值为10
step take default //选择default buket输入{take(default)}
step chooseleaf firstn 0 type host //选择当前副本数个主机下的OSD{select(replicas, type)}
step emit //输出将要分布的bucket的列表{emit(void)}
}
选择方式
CHRUSH算法依赖以上的算法(默认为straw2)实现对PG的映射,输入pg_id、Cluster map、Cluster rule,与随机因子经过哈希计算,输出一组OSD列表,即该pg要落在OSD的编号。
但是选出的OSD有可能会出现冲突或过载,就需要重新选择:
-
冲突:指选中条目已经存在于输出条目中,如osd.1已经存在于输出列表中,下一个经计算同样选出了osd.1,此时需要调整随机因子,再次计算进行选择。
-
过载或失效:指选出的OSD无法提供足够的空间来存储数据,虽然CRUSH算法理论上可以让数据在所有device(磁盘)中均匀分布,但实际并非如此:
- 小规模集群,PG数量较少,则CRUSH输入的样本容量不够,导致数据计算分布不均匀。
- crush自身对于多副本模式数据均匀分布做的不够完善。
ceph引入过载测试reweight可人工干预对OSD的选择概率,reweight的值设置的越高,则通过测试概率越高,因此可以通过降低过载OSD的reweight和增加低负载OSD的reweight来使得数据均衡。
引入过载测试也可以区分OSD暂时失效和被永久删除
如果OSD暂时失效(如拔出对应磁盘一段时间,ceph将其设置为OUT),可以将其reweight的值设置为0.000,利用过载测试将其从候选条目中筛掉,进而将其承载的数据迁移到其他OSD。恢复后再将reweight设置为1.000,即可迁回数据(指OSD离线期间产生的新数据)
如果是被永久删除,那么它会被从候选条目删除,即便后续再次添加进来,因为cluster map中的唯一编号变化而承载与之前不同的数据,使得集群出现大规模的数据均衡。
学习自:
《Ceph源码分析》 常涛
《Ceph之RADOS设计原理与实现》 谢型果 严军
https://docs.ceph.com/docs/kraken/rados/operations/crush-map/