深度学习之概述(Overview)
原创 2017-10-11 HILL 沪江技术学院
作者: HILL
本文为原创文章,转载请注明作者及出
2016年被称为人工智能的元年,2017年是人能智能应用的元年;深度学习技术和应用取得飞速发展;深度学习在互联网教育场景也得到广泛应用。本文主要介绍机器学习及深度学习之定义及基本概念、相关网络结构等。
本文主要内容包括机器学习的定义及组成分类、深度学习的定义、深度学习和机器学习的区别、神经网络基本概念及基本结构、深度学习的相关核心概念(基本假设、数据集、表示、泛化、容量、优化、超参数、误差、欠拟合、过拟合、正则化)、两种典型深度网络结构(CNN、RNN)基本介绍。
引言
人工智能究竟能够做什么?对我们有什么影响?我们从下面两张图说起:图1是工业革命时期的《纱厂女孩 Cotton Mill Girl》,说明了工业革命导致机器替代人的体力劳动,把大量人从繁重的体力劳动中解放出来,更多人从事思考的、创新的、科学工作,生产力大大提高;图2说明了在人工智能时代,通过算法和计算力代替人类思考,把人类从重复性的脑力劳动解放出来,再次解放生产力,使生产力得到提高和飞跃。

图1

图2
关于机器学习
机器学习是机器通过统计学算法,对大量的历史数据进行学习规律从而生成经验模型,利用经验模型对新的样本做出智能识别或对未来做出预测,从而指导业务。机器学习严格定义为:不显式编程地赋予计算机能力的研究领域。机器学习的组成是有数据、算法、模型构成的,数据+算法生成模型,通过进行预测和模式识别,进而提供智能化的服务和产品;参考图3:机器学习和烹饪的形象对比,更好理解机器学习。

图3
机器学习算法分类方式包括学习方式、算法的类似性两种分类方式。
学习方式
通过学习方式将机器学习算法进行分类,主要包括:监督式学习、非监督式学习、半监督式学习、强化学习。
- 监督式学习
在监督式学习方式下,输入数据被称为训练数据,每组训练数据有一个明确的表示或结果(Label);在建立预测模型的时候,监督学习建立一个学习过程,将预测结果与训练数据的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。常见应用场景如分类问题和回归问题。参见算法如逻辑回归(Logistic Regression)、反向传播神经网络(Back Propagation Neural Network)。 - 非监督式学习
在非监督式学习中,数据并不被标识,学习模型为为了推断出数据的一些内在结构。常见应用场景有关联规则的学习以及聚类等。常见算法有Apriori算法、K-Means算法。 - 半监督式学习
在半监督式学习方式下,输入数据部分被标识,部分没有被标识,模型首先需要学习数据的内在结构以便合理的组织数据来进行预测;算法包括一些对常用监督学习算法的延伸,算法首先试图对为标记数据进行建模,在此基础上对标记数据进行预测。算法例如图论推理算法(Graph Inference)、拉普拉斯支持向量机(Laplacian SVM)等。 - 强化学习
在强化学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
算法类似性
根据算法的功能和形式的类似性对算法进行分类,例如:基于树的算法、基于神经网络的算法等。 - 回归算法
回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。常见算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)等。 - 基于实例的算法
基于实例的算法常常用来对决策问题建立模型,这样的模型常常先选取一批样本数据,然后根据某些近似性把新数据与样本数据进行比较。通过这种方式来寻找最佳的匹配。因此,基于实例的算法常常也被称为“赢家通吃”学习或者“基于记忆的学习”。常见的算法包括 k-Nearest Neighbor(KNN), 学习矢量量化(Learning Vector Quantization, LVQ),以及自组织映射算法(Self-Organizing Map , SOM) - 正则化方法
正则化方法通常回归算法的延伸,根据算法的复杂度对算法进行调整,通常解决过拟合问题,通过正则化项对简单模型予以奖励而对复杂算法予以惩罚。算法包括:Ridge Regression, Least Absolute Shrinkage and Selection Operator(LASSO),以及弹性网络(Elastic Net)。 - 决策树学习
决策树算法根据数据的属性采用树状结构建立决策模型, 决策树模型常常用来解决分类和回归问题。常见的算法包括:分类及回归树(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest), 多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine,GBM)。 - 基于核的方法
基于核的算法中最著名的是支持向量机(SVM)。 基于核的算法把输入数据映射到一个高阶的向量空间, 在这些高阶向量空间里, 有些分类或者回归问题能够更容易的解决。 常见的基于核的算法包括:支持向量机(Support Vector Machine,SVM),径向基函数(Radial Basis Function,RBF), 以及线性判别分析(Linear Discriminate Analysis,LDA)等 - 聚类算法
聚类算法通常按照中心点或者分层的方式对输入数据进行归并。所有的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类。常见的聚类算法包括 k-Means算法以及期望最大化算法(Expectation Maximization,EM)。 - 关联规则学习
关联规则学习通过寻找最能够解释数据变量之间关系的规则,来找出大量多元数据集中有用的关联规则。常见算法包括 Apriori算法和Eclat算法等。 - 降低维度算法
降低维度算法试图分析数据的内在结构,不过降低维度算法是以非监督学习的方式试图利用较少的信息来归纳或者解释数据。这类算法可以用于高维数据的可视化或者用来简化数据以便监督式学习使用。常见的算法包括:主成份分析(Principle Component Analysis, PCA),偏最小二乘回归(Partial Least Square Regression,PLS), Sammon映射,多维尺度(Multi-Dimensional Scaling, MDS), 投影追踪(Projection Pursuit)等。 - 集成方法
集成算法用一些相对较弱的学习模型独立地就同样的样本进行训练,然后把结果整合起来进行整体预测。集成算法的主要难点在于究竟集成哪些独立的较弱的学习模型以及如何把学习结果整合起来。这是一类非常强大的算法,同时也非常流行。常见的算法包括:Boosting,Bootstrapped Aggregation(Bagging),AdaBoost,堆叠泛化(Stacked Generalization,Blending),梯度推进机(Gradient Boosting Machine, GBM),随机森林(Random Forest)。
机器学习分类及实践路线图参考图4。

图4
关于深度学习
深度学习是一种特定类型的机器学习,具有强大的能力和灵活性,它将大千世界表示为嵌套的层次概念体系(由较简单概念间的联系定义复杂概念、从一般抽象概括到高级抽象表示)。 深度学习层次概念体系如图5.
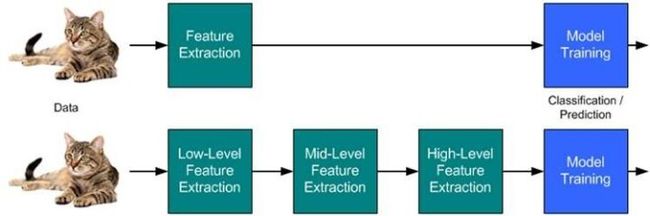
图5
深度学习模型的示意图(图6)。计算机难以理解原始感观输入数据的含义,如表示为像素值集合的图像。将一组像素映射到对象标识的函数非常复杂。如果直接处理,学习或评估此映射似乎是不可能的。深度学习将所需的复杂映射分解为一系列嵌套的简单映射(每个由模型的不同层描述)来解决这一难题。输入展示在 可见层(visible layer),这样命名的原因是因为它包含我们能观察到的变量。然后是一系列从图像中提取越来越多抽象特征的 隐藏层(hidden layer)。因为它们的值不在数据中给出,所以将这些层称为 ‘‘隐藏”; 模型必须确定哪些概念有利于解释观察数据中的关系。这里的图像是每个隐藏单元表示的特征的可视化。给定像素,第一层可以轻易地通过比较相邻像素的亮度来识别边缘。有了第一隐藏层描述的边缘,第二隐藏层可以容易地搜索可识别为角和扩展轮廓的边集合。给定第二隐藏层中关于角和轮廓的图像描述,第三隐藏层可以找到轮廓和角的特定集合来检测特定对象的整个部分。最后,根据图像描述中包含的对象部分,可以识别图像中存在的对象。
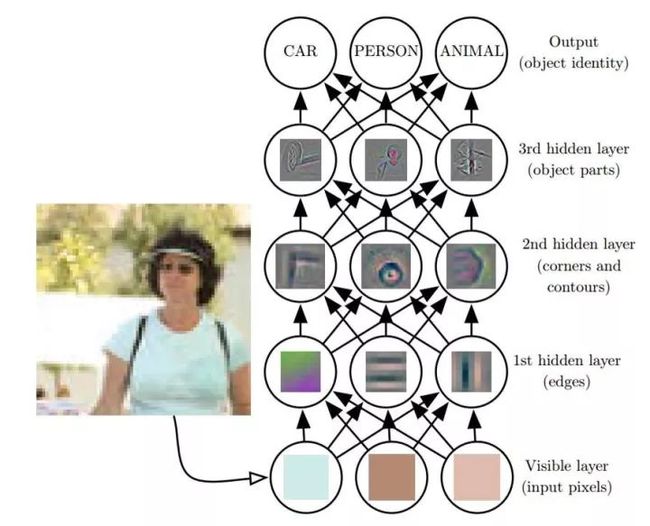
图6
深度学习与机器学习的区别
深度学习与机器学习的主要区别体现以下两个方面:
数据规模上:深度学习需要大规模的数据,数据规模越大对深度学习的效果越好。经验法则是,监督深度学习算法在每类给定约 5000 个标注样本情况下使用机器学习算法一般将达到可以接受的性能,当至少有 1000 万个标注样本的数据集用于训练深度学习模型时,它将达到或超过人类表现。
特征处理方式:深度学习有一个振奋的优点,它可以自动的从数据中提取特征。深度学习通过其他较简单的表示来表达复杂表示。
图7:韦恩图展示了深度学习是一种表示学习,也是一种机器学习。
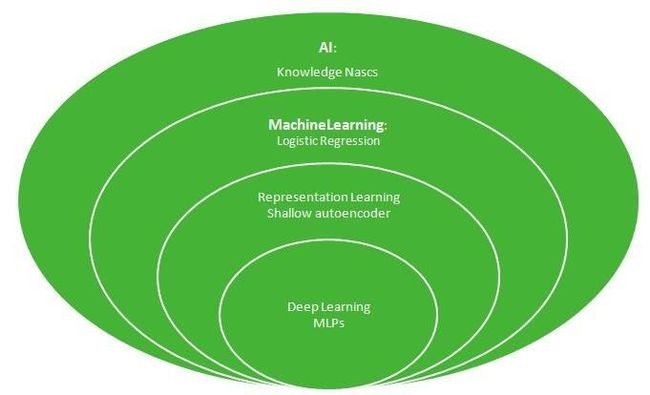
图7
图8流程图展示了AI系统不同部分如何在不同的AI学科中彼此相关,阴影框表示能从数据中学习的组件。
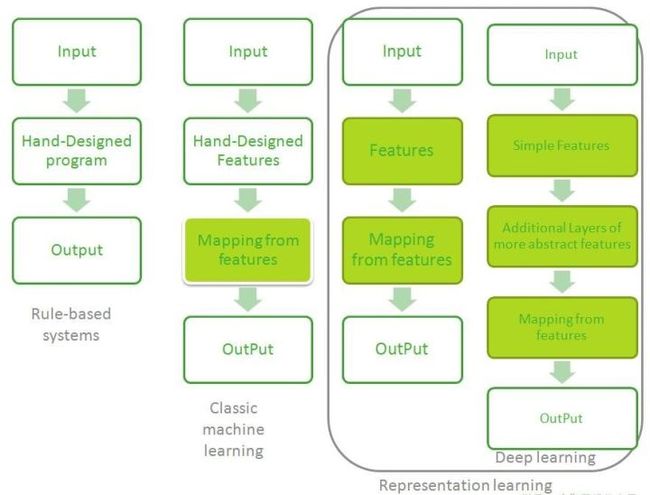
图8
神经网络基本概念及结构
深度学习这个概念是架构在神经网络上的。而一个简单的神经网络如图9所示。其中每个圆圈表示神经元,每个神经元存储一个数,这些神经元通过权重和激活函数通过一定的连接结构和下一层的神经元连接在一起。在这些神经元中,接受外界输入的神经元被统称为输入层(input layer),中间和外界没有联系的神经元被称作隐含层(hidden layer),向外界输出的神经元被称作输出层(output layer)。在神经网络中,神经元之间连接的权重作为训练参数,通过反向传播算法(Backpropagation)进行训练。
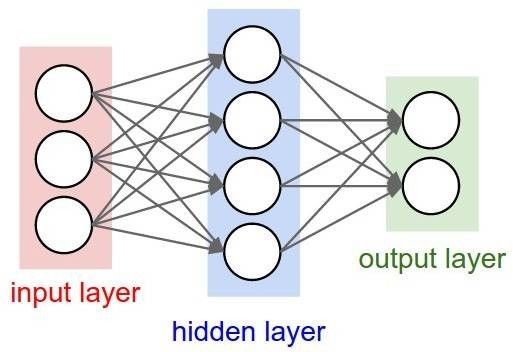
图9
深度学习的相关核心概念
- 泛化
在先前未观测到的输入上表现良好的能力被称为泛化(generalization)。机器学习的主要挑战就是算法模型的泛化能力,我们的算法必须能够在先前未观测的新输入上表现良好,而不只是在训练集上表现良好。深度学习部分发展动机就是解决人工智能问题的泛化能力。 - 基本假设
平滑先验(smoothnexx prior)、局部不变性先验(local constancy prior)是使用最广泛的先验假设,这个先验表明学习的函数不应在小区域内发生很大的变化。
流形(manifold)指连接在一起的区域。数学上,它是指一组点,且每个点都有其邻域。给定一个任意的点,其流形局部看起来像是欧几里得空间。流形学习的目的是将其映射回低维空间中,揭示其本质;流形学习基本思想:假设数据在高维具有某种结构特征,希望降到低维后,仍能保持该结构。
- 表示
表示的概念是深度学习核心主题之一;传统的机器学习算法的性能很大程度上依赖于给定数据的表示,表示的选择对机器学习算法的性能有巨大的影响;有很多算法的任务是找到数据的最佳表示,最佳表示是指该表示在比本身表示的信息更简单或更易访问而受到一些惩罚或限制的情况下,尽可能地保存关系数据x更多的信息。常见的三种表示包括低维表示、稀疏表示和独立表示。图10展示了一个简单数据不同表示的例子,左边是极坐标的表示,右边是笛卡尔坐标的表示。
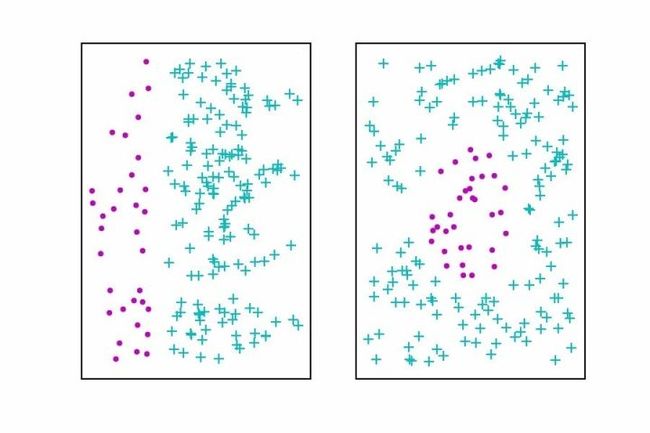
图10
- 误差、过拟合、欠拟合、容量
误差:误差包括训练误差(training error)和泛化误差(generalization error)(也称为测试误差,test error);机器学习的核心目标是降低泛化误差。
过拟合:过拟合是指训练误差和和测试误差之间的差距太大。
欠拟合:欠拟合是指模型不能在训练集上获得足够低的误差。
容量:模型的容量是指其拟合各种函数的能力。
容量和误差之间的典型关系:图11。 训练误差和测试误差表现得非常不同。在图的左端, 训练误差和泛化误差都非常高。这是 欠拟合机制(underfitting regime)。当我们增加容量时, 训练误差减小,但是训练误差和泛化误差之间的间距却不断扩大。最终,这个间距的大小超过了训练误差的下降,我们进入到了 过拟合机制(overfitting regime),其中容量过大,超过了 最佳容量(optimal capacity)
图11
- 优化、正则化、超参数
在机器学习的实践中,一个很重要的问题是优化的问题。所谓优化就是寻找一组机器学习模型的参数,使得在该参数条件下,整个模型的损失函数(loss function)的值最小,即在该参数条件下模型和训练样本拟合得最好。相比于传统的机器学习而言,深度学习的优化过程有一个特点就是深度学习的损失函数是非凸(non-convex)的,也就是损失函数有许多局部极小值点,而非仅仅有一个局部极小值点。这样就增加了深度学习模型寻找最优参数的难度。在深度学习过程中,一般使用的是小批量梯度下降法(mini-batch gradient descent),设置一个合适的下降速率(即学习率,learning rate),进行优化。值得注意的一点是,在优化过程中,损失函数的值并非一定是下降的,而是在波动中逐渐下降,如图12所示。
图12
前面已经提到,虽然在整个训练过程中训练集的损失函数在不断地下降,但是测试集的损失函数有一个先下降然后升高的过程(如图11所示)。为了防止过拟合,我们需要人为的对参数进行一定的限制,这个限制就叫做正则化(Regularization)。正常用的正则化的方法主要包含L1正则化,L2正则化和Dropout正则化方法。通过调节这些正则化方法的权重,可以调节模型过拟合的程度。在深度学习的训练过程中,为了能够使模型更好的拟合训练样本,需要手动调节深度学习网络的一些参数。这些参数被称作超参数 (Hyperparameter)。这些参数包含了前面所提到的学习率,正则化的权重等等。由于可调节的超参数很多,可以先随机选定一些参数的值,从中取出最好的,然后再对参数进行微调。
- 卷积神经网络(Convolutional Neural Network, CNN)
卷积神经网络是今年来比较热门的神经网络结构之一,主要应用于图像识别之类的输入数据有一定空间关联性的深度学习场景。在卷积神经网络中,比较重要的两种连接层是卷积层(Convolution Layer)和池化层(Pooling Layer)。下面来简单介绍一下这两种层的结构。
图13
图13简要的描述了卷积层是如何工作的,其中 I是原始的输入图像, K是卷积层中的过滤器(filter)。过滤器是按照空间顺序排列的一系列的参数的集合。在图中这个过滤器是一个3x3的矩形。其中矩形区域填充了9个参数。通过过滤器在原始图像中不断滑动(红色区域,这个区域从图像的左上角一直滑动到右下角),覆盖的红色区域和过滤器的参数按照顺序两两相乘,最后求和得到一个数( IK*)中的绿色区域。这样就进行了一次卷积的运算。通过使用多个不同的过滤器可以从一个原始的图像出发生成包含有原始图像不同特征的新图像。
图14
图14描述了池化层是如何工作的。池化层通过把图像分割成很多小区域,然后取小区域的特征来把一个图像缩减成比较小的图像。图中描述了最大池化(Max-Pool)的一个过程,也就是特征的提取是基于小区域的最大值。可以看到这个池化层把原来的4x4图缩减成了2x2的图,减少了特征的维数。池化层的作用主要是简化模型和提取特征。
- 循环神经网络(Recurrent Neural Network, RNN)
相比于卷积神经网络,循环神经网络主要用于做文字和语音识别之类的深度学习场景。循环神经网络由单元(Cell)按照时间顺序连接在一起,其中单元与单元之间共享参数,通过传递隐含状态(hidden state)相互连接,并且每个单元有输入和输出,如图15所示。其中当前单元隐含状态**ht
和上一个单元的的隐含状态ht-1
以及当前输入值xt
关联在一起,并且决定了当前单元的输出yt
**。
图15
在实际的训练和预测过程中,循环神经网络常常被展开成固定长度单元的连接构成的计算图。在这个计算图中所有的单元共享单元的参数,如图16所示。
图16
Deep Learning的心得:
随机器学习框架如TensorFlow、Caffe等的发展,机器学习及深度学习模型构建及应用成本大大降低,将算法工程师焦点逐步从算法逻辑本身转移业务模型构建及应用,开发效率极大提高;图17形象说明大众对深度学习的理解及深度学习模型构建过程比较像在玩积木一样,尝试各种堆叠的方法。
机器学习(深度学习)系统及应用是复杂的,所需要的周边基础设施是庞大而复杂(参见图18)。
图17
图18:Only a small fraction of real-world ML systems is composed of the ML code, as shown by the small black box in the middle. The required surrounding infrastructure is vast and complex.
关于HILL
智能学习实验室(HILL, Hujiang Intelligent Learning Lab)
沪江智能学习实验室(HILL)成立于 2017 年,旨在融合教育学、心理学和计算机科学等领域的相关理论和技术,探索人工智能在教育领域的应用场景,推进沪江教育产品的智能化能力。未来也希望将这些能力提供给合作伙伴和整个教育行业。HILL的愿景:Activate Intelligence,Innovate Learning。
推荐系统那些事儿
一个关于 nolock 的故事
系列连载 | 带你玩转Netty 之 WebSocket
系列连载 | 带你玩转Netty 之 应用篇
系列连载 | 带你玩转Netty之原理篇

微信扫一扫关注该公众号