计算机与软件工程作业四
| 作业要求 | 第四周作业 |
|---|---|
| 课程要求 | 按照作业要求完成作业并进行自我总结 |
| 参考文献 | 参考文献 |
| 作业帮助 | 了解代码的使用规范 掌握结对编程技能 |
正文
https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534
代码规范复审
作业一
每个人针对之前两次作业所写的代码,针对要求,并按照代码规范(风格规范、设计规范)要求评判其他学生的程序,同时进行代码复审(按照代码复审核表 https://www.cnblogs.com/xinz/archive/2011/11/20/2255971.html),要求评价数目不少于8人次,
评价内容直接放在你被评价的作业后面评论中
同时另建立一个博客,将你作的评论的截图或者链接,放在博客中,并在你的博客中谈谈自己的总体看法
作业评论链接
1.https://www.cnblogs.com/zwx1998-1221/
2.https://www.cnblogs.com/hyjlove/p/12460522.html
3.https://www.cnblogs.com/wyc1/p/12459804.html
4.https://www.cnblogs.com/jian-He/p/12456325.html
5.https://www.cnblogs.com/17074211zh/p/12454354.html
6.https://www.cnblogs.com/yjh1128/p/12451503.html
7.https://www.cnblogs.com/MOLEkiss/p/12456370.html
8.https://www.cnblogs.com/guozhiwei123/p/12435308.html
评论代码截图








结对编程
参考结对编程的方法、过程(https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html)开展两人合作完成本项目
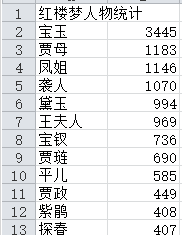
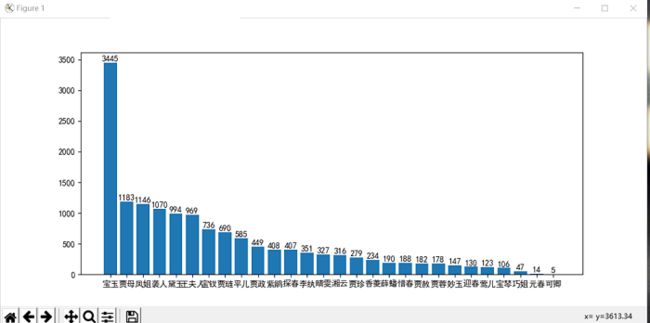
实现一个简单而完整的软件工具(中文文本文件人物统计程序):针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。
进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。
将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
《红楼梦》与《水浒传》的文本小说将会发到群里。
注意,要求能够分章节自动获得人物出现次数
红楼梦代码
import jieba
import csv
class NameCount():
def getNameTimesSort(self, name_list, txt_path):
# 添加jieba分词
mydict = ['琏二奶奶', '凤哥儿', '凤丫头', '宝姑娘', '颦儿', '二姑娘', '三姑娘', '四姑娘', '云妹妹', '蓉大奶奶']
for item in mydict:
jieba.add_word(item)
#打开并读取txt文件
txt = open(txt_path, "r", encoding='utf-8').read()
# 定义别名列表
bieming = [["王熙凤", "凤丫头", '琏二奶奶', '凤姐', '凤哥儿', '凤辣子','熙凤'],["林妹妹", "黛玉", '林姑娘', '林黛玉'], ["宝钗", '宝姑娘', '宝丫头', '宝姐姐', '薛宝钗'],
['探春', '三姑娘', '贾探春'], ['湘云', '云妹妹', '史湘云'],['迎春', '二姑娘', '贾迎春'],['元春', '大姑娘', '娘娘', '贵妃', '元妃', '贾元春'],
['惜春', '四姑娘', '贾惜春'], ['妙玉'],['巧姐'], ['李纨', '大嫂子'], ['秦可卿', '可卿', '蓉大奶奶']]
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
# 计算出场次数(各个别名的合计次数)
lst = list()
for i in range(12):
lt = 0
for item in bieming[i]:
lt += counts.get(item, 0)
lst.append(lt)
items = list()
for i in range(12):
items.append([name_list[i], lst[i]])
items.sort(key=lambda x: x[1], reverse=True)
# csv文件
f = open('红楼梦人物统计.csv', 'w', newline='', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['红楼梦人物统计'])
csv_writer.writerow(["姓名", "出现次数"])
for i in range(12):
word, count = items[i]
csv_writer.writerow([word, count])
print("{0:<10}{1:>5}".format(word, count))
f.close()
return items
if __name__ == '__main__':
# 参与统计的人名列表,可修改成自己想要的列表
name_list = ['熙凤', '黛玉', '宝钗', '探春', '湘云', '迎春', '元春', '惜春', '妙玉', '巧姐', '李纨', '可卿']
# txt文件所在路径
txt_path = '/Users/hejian/Desktop/红楼梦.txt'
NameCount().getNameTimesSort(name_list,txt_path)
水浒传代码
# -*- coding: gb2312 -*-
import jieba
import csv
import pstats
import profile
class NameCount():
def getNameTimesSort(self, name_list, txt_path):
mydict = ['及时雨','黑旋风', '行者','豹子头','花和尚', '智多星', '玉麒麟', '神行太保', '小李广','九纹龙','青面兽', '高太尉','鼓上蚤']
for item in mydict:
jieba.add_word(item)
txt = open(txt_path, "r", encoding='utf-8').read()
bieming = [['及时雨', '宋江', '呼保义', '孝义黑三郎', '宋公明', '宋押司'],['黑旋风', '李逵', '铁牛'],['武松', '武二郎', '行者', '武行者', '武都头'],['豹子头', '林冲', '林教头'],
['鲁提辖', '鲁达', '智深', '花和尚', '鲁智深'],['智多星', '吴用', '吴学究', '吴加亮', '赛诸葛', '加亮先生'],['卢俊义', '玉麒麟', '卢员外'], ['戴宗','戴院长','神行太保'],['花荣', '花知寨', '小李广'],
['九纹龙', '史进'], ['杨志', '杨制使', '杨提辖', '青面兽'], ['高俅,‘高二','高太尉'],['时迁','鼓上蚤'] ]
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
# 计算出场次数(各个别名的合计次数)
lst = list()
for i in range(13):
lt = 0
for item in bieming[i]:
lt += counts.get(item, 0)
lst.append(lt)
items = list()
for i in range(13):
items.append([name_list[i], lst[i]])
items.sort(key=lambda x: x[1], reverse=True)
f = open('水浒传人物统计.csv', 'w', newline='', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['水浒传人物统计'])
csv_writer.writerow(["姓名", "出现次数"])
for i in range(13):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
csv_writer.writerow([word, count])
f.close()
return items
if __name__ == '__main__':
# 参与统计的人名列表,可修改成自己想要的列表
name_list = ['宋江', '鲁智深', '花荣', '武松', '吴用', '高俅', '史进', '卢俊义', '李逵', '林冲', '杨志','戴宗','时迁']
# 水浒传txt文件所在路径
txt_path = 'D:\水浒传.txt'
NameCount().getNameTimesSort(name_list, txt_path)
print("效能测试:")
profile.run('NameCount()', "result")
# 直接把分析结果打印到控制台
p = pstats.Stats('result') # 创建Stats对象
p.strip_dirs().sort_stats("call").print_stats() # 按照调用的次数排序
p.strip_dirs().sort_stats("cumulative").print_stats() # 按执行时间次数排序
他山之石 可以攻玉
https://blog.csdn.net/weixin_43936464/article/details/84779924
运行截图


结对人博客 https://i-beta.cnblogs.com/posts/edit