HDFS(Hadoop Distributed File System)Hadopp分布式文件系统,Hadoop的设计起源于Apache Lucene,是一个开源的分布式计算平台,也是属于Apache基金会的。Hadoop为用户提供分布式的存储和计算,地产细节对于用户来讲是透明的,用户可以像操纵本地文件一样使用Hadoop。Hadoop主要由HDFS和MapReduce组成。HDFS在处理大文件上有着显著的优势,它以流的方式访问里面的文件。HDFS通常被部署在多个廉价的计算机上,它的可靠性和可扩展性很强。Hadoop MapReduce的设计思想来自于Google MapReduce分布式计算框架,Hadoop MapReduce是Google MapReduce的一种开源实现,它为用户提供了Map函数和Reduce函数的接口,用户可以在不知道底层细节的情况调用这些函数进行应用开发。本文着重介绍Hadoop的文件系统和用于给HDFS提供纠错能力的HDFS-RAID
HDFS文件系统架构:

Namenode是管理节点,主要管理文件系统中的namespace和元数据,数据块分布在节点中的位置,数据块的顺序和数据块副本数等信息。Namenode还负责数据的读写过程。
Datanode是真正存储数据的部分,一个文件被分成大小相等的块然后放在不同的Datanode上,集群运行的时候,Datanode和Namenode会不停的有心跳信息,保证二者之间相互协调工作。
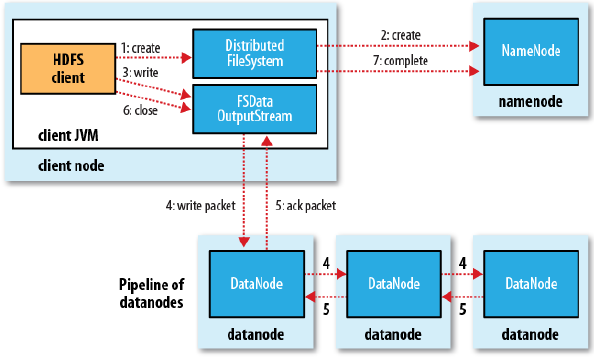
客户端调用create()来创建文件。DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。DistributedFileSystem返回DFSOutputStream,客户端用于写数据。客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
如果数据节点在写入的过程中失败:
1.关闭pipeline,将ack queue中的数据块放入data queue的开始。
2.当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
3.失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
4.元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
问题:为什么写文件是串行的方式而不是并行的方式?secondNameNode是干什么的?HDFS横向扩展遇到单点namenode怎么办?namenode节点故障了怎么办?这是很有意思的问题!

客户端(client)用FileSystem的open()函数打开文件,DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。客户端调用stream的read()函数开始读取数据。DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
Data从数据节点读到客户端(client),当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。失败的数据节点将被记录,以后不再连接。
接下来是MapReduce
MapReduce编程当初是Google提出的,应用于海量数据处理的并行计算模型。Map面对的众多的互不相关的数据,分析这些数据,从里面提取出value和key也就提取了数据特征。Hadoop的MapReduce部署在所有的节点上,Namenode运行的是JobTracker,负责任务的分配与控制,Datanode上运行的是TaskTracker,才是真正并行计算的节点。最后把MapReduce处理后的数据放到HDFS中。

Hadoop中Mapreduce的执行流程如下:
1.分割数据块。MapReduce处理的都是HDFS的数据,计算之前会将他们分成块。
2.创建任务。把任务提交给JobTracker之后,它开始分配MapTask和ReduceTask,并将这些作业分配MapTask和ReduceTask,然后将这些任务交给空闲的TaskTracker。
3.Map过程。TaskTracker运行在每个Datanode上来执行被分配到的Map任务,MapTask开始读取数据,将读到的数据交给Map函数处理,然后把得到结果存在本地磁盘或读到内存。
4.Combiner过程。Map过程得出了很多的中间结果,如果把这些结果直接送到Reduce函数处理会造成网络阻塞,所以Combiner就是将这些数据进行合并的过程。
5.Shuffle过程。将数据从MapTaske传送到ReduceTask这个过程。
6.Reduce过程。将MapTask数据传到Reduce函数,实现数据的合并,得出最后的结果。等Job任务结束后,将最终结果传到HDFS中。
问题: MapReduce相比于Spark的缺点? MapReduce中的Map函数是如何做到分区的?map函数和reduce函数产生的中间结果是放在本地磁盘上还是HDFS上?也是挺有意思的设计层面的问题!