作者 | 元乙 阿里云存储服务技术专家
导读:上一篇文章主要介绍 Kubernetes 日志输出的一些注意事项,日志输出最终的目的还是做统一的采集和分析。在 Kubernetes 中,日志采集和普通虚拟机的方式有很大不同,相对实现难度和部署代价也略大,但若使用恰当则比传统方式自动化程度更高、运维代价更低。本文为日志系列文章的第 4 篇。
第一篇:《6 个 K8s 日志系统建设中的典型问题,你遇到过几个?》
第二篇:《一文看懂 K8s 日志系统设计和实践》
第三篇:《9 个技巧,解决 K8s 中的日志输出问题》
Kubernetes 日志采集难点
在 Kubernetes 中,日志采集相比传统虚拟机、物理机方式要复杂很多,最根本的原因是 Kubernetes 把底层异常屏蔽,提供更加细粒度的资源调度,向上提供稳定、动态的环境。因此日志采集面对的是更加丰富、动态的环境,需要考虑的点也更加的多。
例如:
- 对于运行时间很短的 Job 类应用,从启动到停止只有几秒的时间,如何保证日志采集的实时性能够跟上而且数据不丢?
- K8s 一般推荐使用大规格节点,每个节点可以运行 10-100+ 的容器,如何在资源消耗尽可能低的情况下采集 100+ 的容器?
- 在 K8s 中,应用都以 yaml 的方式部署,而日志采集还是以手工的配置文件形式为主,如何能够让日志采集以 K8s 的方式进行部署?
| Kubernetes | 传统方式 | |
|---|---|---|
| 日志种类 | 文件、stdout、宿主机文件、journal | 文件、journal |
| 日志源 | 业务容器、系统组件、宿主机 | 业务、宿主机 |
| 采集方式 | Agent(Sidecar、DaemonSet)、直写(DockerEngine、业务) | Agent、直写 |
| 单机应用数 | 10-100 | 1-10 |
| 应用动态性 | 高 | 低 |
| 节点动态性 | 高 | 低 |
| 采集部署方式 | 手动、Yaml | 手动、自定义 |
采集方式:主动 or 被动
日志的采集方式分为被动采集和主动推送两种,在 K8s 中,被动采集一般分为 Sidecar 和 DaemonSet 两种方式,主动推送有 DockerEngine 推送和业务直写两种方式。
- DockerEngine 本身具有 LogDriver 功能,可通过配置不同的 LogDriver 将容器的 stdout 通过 DockerEngine 写入到远端存储,以此达到日志采集的目的。这种方式的可定制化、灵活性、资源隔离性都很低,一般不建议在生产环境中使用;
- 业务直写是在应用中集成日志采集的 SDK,通过 SDK 直接将日志发送到服务端。这种方式省去了落盘采集的逻辑,也不需要额外部署 Agent,对于系统的资源消耗最低,但由于业务和日志 SDK 强绑定,整体灵活性很低,一般只有日志量极大的场景中使用;
- DaemonSet 方式在每个 node 节点上只运行一个日志 agent,采集这个节点上所有的日志。DaemonSet 相对资源占用要小很多,但扩展性、租户隔离性受限,比较适用于功能单一或业务不是很多的集群;
- Sidecar 方式为每个 POD 单独部署日志 agent,这个 agent 只负责一个业务应用的日志采集。Sidecar 相对资源占用较多,但灵活性以及多租户隔离性较强,建议大型的 K8s 集群或作为 PaaS 平台为多个业务方服务的集群使用该方式。
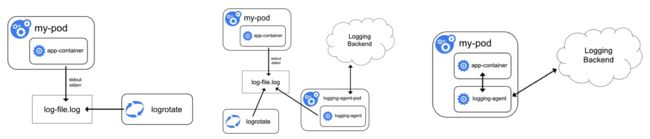
总结下来:
- DockerEngine 直写一般不推荐;
- 业务直写推荐在日志量极大的场景中使用;
- DaemonSet 一般在中小型集群中使用;
- Sidecar 推荐在超大型的集群中使用。
详细的各种采集方式对比如下:
| DockerEngine | 业务直写 | DaemonSet方式 | Sidecar方式 | |
|---|---|---|---|---|
| 采集日志类型 | 标准输出 | 业务日志 | 标准输出+部分文件 | 文件 |
| 部署运维 | 低,原生支持 | 低,只需维护好配置文件即可 | 一般,需维护DaemonSet | 较高,每个需要采集日志的POD都需要部署sidecar容器 |
| 日志分类存储 | 无法实现 | 业务独立配置 | 一般,可通过容器/路径等映射 | 每个POD可单独配置,灵活性高 |
| 多租户隔离 | 弱 | 弱,日志直写会和业务逻辑竞争资源 | 一般,只能通过配置间隔离 | 强,通过容器进行隔离,可单独分配资源 |
| 支持集群规模 | 本地存储无限制,若使用syslog、fluentd会有单点限制 | 无限制 | 取决于配置数 | 无限制 |
| 资源占用 | 低,docker | |||
| engine提供 | 整体最低,省去采集开销 | 较低,每个节点运行一个容器 | 较高,每个POD运行一个容器 | |
| 查询便捷性 | 低,只能grep原始日志 | 高,可根据业务特点进行定制 | 较高,可进行自定义的查询、统计 | 高,可根据业务特点进行定制 |
| 可定制性 | 低 | 高,可自由扩展 | 低 | 高,每个POD单独配置 |
| 耦合度 | 高,与DockerEngine强绑定,修改需要重启DockerEngine | 高,采集模块修改/升级需要重新发布业务 | 低,Agent可独立升级 | 一般,默认采集Agent升级对应Sidecar业务也会重启(有一些扩展包可以支持Sidecar热升级) |
| 适用场景 | 测试、POC等非生产场景 | 对性能要求极高的场景 | 日志分类明确、功能较单一的集群 | 大型、混合型、PAAS型集群 |
日志输出:Stdout or 文件
和虚拟机/物理机不同,K8s 的容器提供标准输出和文件两种方式。在容器中,标准输出将日志直接输出到 stdout 或 stderr,而 DockerEngine 接管 stdout 和 stderr 文件描述符,将日志接收后按照 DockerEngine 配置的 LogDriver 规则进行处理;日志打印到文件的方式和虚拟机/物理机基本类似,只是日志可以使用不同的存储方式,例如默认存储、EmptyDir、HostVolume、NFS 等。
虽然使用 Stdout 打印日志是 Docker 官方推荐的方式,但大家需要注意:这个推荐是基于容器只作为简单应用的场景,实际的业务场景中我们还是建议大家尽可能使用文件的方式,主要的原因有以下几点:
-
Stdout 性能问题,从应用输出 stdout 到服务端,中间会经过好几个流程(例如普遍使用的 JSON LogDriver):应用 stdout -> DockerEngine -> LogDriver -> 序列化成 JSON -> 保存到文件 -> Agent 采集文件 -> 解析 JSON -> 上传服务端。整个流程相比文件的额外开销要多很多,在压测时,每秒 10 万行日志输出就会额外占用 DockerEngine 1 个 CPU 核;
-
Stdout 不支持分类,即所有的输出都混在一个流中,无法像文件一样分类输出,通常一个应用中有 AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog 等,而这些日志的格式、用途不一,如果混在同一个流中将很难采集和分析;
-
Stdout 只支持容器的主程序输出,如果是 daemon/fork 方式运行的程序将无法使用 stdout;
- 文件的 Dump 方式支持各种策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对更加灵活。
因此我们建议线上应用使用文件的方式输出日志,Stdout 只在功能单一的应用或一些 K8s 系统/运维组件中使用。
CICD集成:Logging Operator
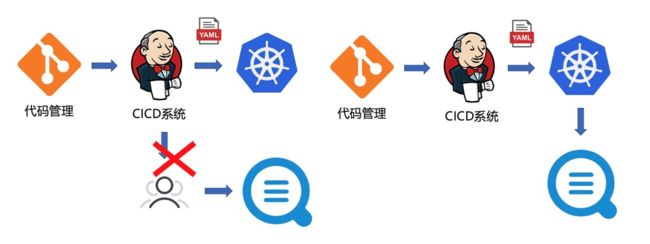
Kubernetes 提供了标准化的业务部署方式,可以通过 yaml(K8s API)来声明路由规则、暴露服务、挂载存储、运行业务、定义缩扩容规则等,所以 Kubernetes 很容易和 CICD 系统集成。而日志采集也是运维监控过程中的重要部分,业务上线后的所有日志都要进行实时的收集。
原始的方式是在发布之后手动去部署日志采集的逻辑,这种方式需要手工干预,违背 CICD 自动化的宗旨;为了实现自动化,有人开始基于日志采集的 API/SDK 包装一个自动部署的服务,在发布后通过 CICD 的 webhook 触发调用,但这种方式的开发代价很高。
在 Kubernetes 中,日志最标准的集成方式是以一个新资源注册到 Kubernetes 系统中,以 Operator(CRD)的方式来进行管理和维护。在这种方式下,CICD 系统不需要额外的开发,只需在部署到 Kubernetes 系统时附加上日志相关的配置即可实现。
Kubernetes 日志采集方案
早在 Kubernetes 出现之前,我们就开始为容器环境开发日志采集方案,随着 K8s 的逐渐稳定,我们开始将很多业务迁移到 K8s 平台上,因此也基于之前的基础专门开发了一套 K8s 上的日志采集方案。主要具备的功能有:
- 支持各类数据的实时采集,包括容器文件、容器 Stdout、宿主机文件、Journal、Event 等;
- 支持多种采集部署方式,包括 DaemonSet、Sidecar、DockerEngine LogDriver 等;
- 支持对日志数据进行富化,包括附加 Namespace、Pod、Container、Image、Node 等信息;
- 稳定、高可靠,基于阿里自研的 Logtail 采集 Agent 实现,目前全网已有几百万的部署实例;
- 基于 CRD 进行扩展,可使用 Kubernetes 部署发布的方式来部署日志采集规则,与 CICD 完美集成。
安装日志采集组件
目前这套采集方案已经对外开放,我们提供了一个 Helm 安装包,其中包括 Logtail 的 DaemonSet、AliyunlogConfig 的 CRD 声明以及 CRD Controller,安装之后就能直接使用 DaemonSet 采集以及 CRD 配置了。安装方式如下:
- 阿里云 Kubernetes 集群在开通的时候可以勾选安装,这样在集群创建的时候会自动安装上述组件。如果开通的时候没有安装,则可以手动安装;
- 如果是自建的 Kubernetes,无论是在阿里云上自建还是在其他云或者是线下,也可以使用这样采集方案,具体安装方式参考自建 Kubernetes 安装。
安装好上述组件之后,Logtail 和对应的 Controller 就会运行在集群中,但默认这些组件并不会采集任何日志,需要配置日志采集规则来采集指定 Pod 的各类日志。
采集规则配置:环境变量 or CRD
除了在日志服务控制台上手动配置之外,对于 Kubernetes 还额外支持两种配置方式:环境变量和 CRD。
- 环境变量是自 swarm 时代一直使用的配置方式,只需要在想要采集的容器环境变量上声明需要采集的数据地址即可,Logtail 会自动将这些数据采集到服务端;
这种方式部署简单,学习成本低,很容易上手;但能够支持的配置规则很少,很多高级配置(例如解析方式、过滤方式、黑白名单等)都不支持,而且这种声明的方式不支持修改/删除,每次修改其实都是创建 1 个新的采集配置,历史的采集配置需要手动清理,否则会造成资源浪费。
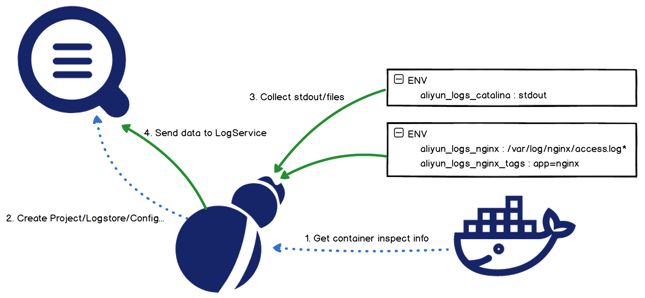
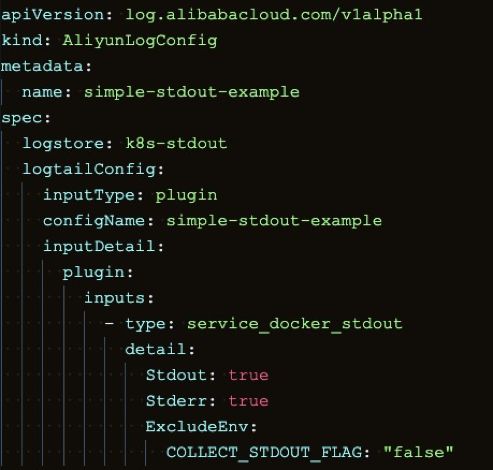
- CRD 配置方式是非常符合 Kubernetes 官方推荐的标准扩展方式,让采集配置以 K8s 资源的方式进行管理,通过向 Kubernetes 部署 AliyunLogConfig 这个特殊的 CRD 资源来声明需要采集的数据。
例如下面的示例就是部署一个容器标准输出的采集,其中定义需要 Stdout 和 Stderr 都采集,并且排除环境变量中包含 COLLEXT_STDOUT_FLAG:false 的容器。
基于 CRD 的配置方式以 Kubernetes 标准扩展资源的方式进行管理,支持配置的增删改查完整语义,而且支持各种高级配置,是我们极其推荐的采集配置方式。
采集规则推荐的配置方式
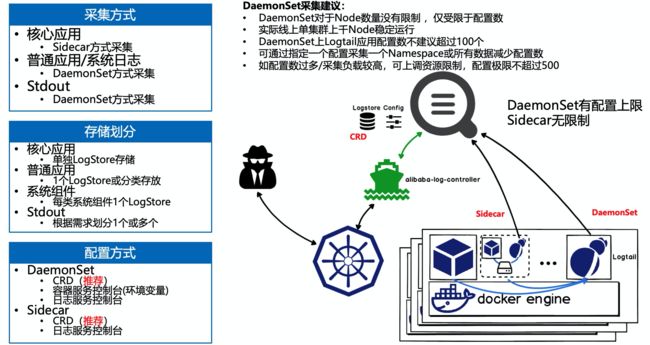
实际应用场景中,一般都是使用 DaemonSet 或 DaemonSet 与 Sidecar 混用方式,DaemonSet 的优势是资源利用率高,但有一个问题是 DaemonSet 的所有 Logtail 都共享全局配置,而单一的 Logtail 有配置支撑的上限,因此无法支撑应用数比较多的集群。
上述是我们给出的推荐配置方式,核心的思想是:
- 一个配置尽可能多的采集同类数据,减少配置数,降低 DaemonSet 压力;
- 核心的应用采集要给予充分的资源,可以使用 Sidecar 方式;
- 配置方式尽可能使用 CRD 方式;
- Sidecar 由于每个 Logtail 是单独的配置,所以没有配置数的限制,这种比较适合于超大型的集群使用。
实践 1 - 中小型集群
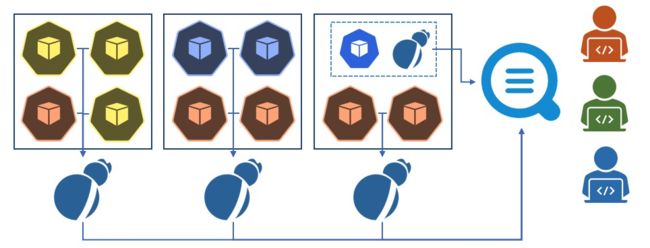
绝大部分 Kubernetes 集群都属于中小型的,对于中小型没有明确的定义,一般应用数在 500 以内,节点规模 1000 以内,没有职能明确的 Kubernetes 平台运维。这种场景应用数不会特别多,DaemonSet 可以支撑所有的采集配置:
- 绝大部分业务应用的数据使用 DaemonSet 采集方式;
- 核心应用(对于采集可靠性要求比较高,例如订单/交易系统)使用 Sidecar 方式单独采集。
实践 2 - 大型集群
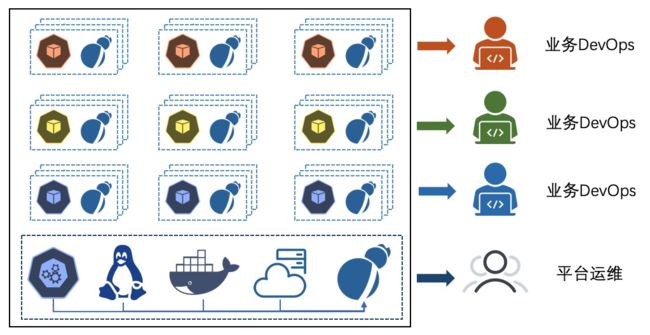
对于一些用作 PaaS 平台的大型/超大型集群,一般业务在 1000 以上,节点规模也在 1000 以上,有专门的 Kubernetes 平台运维人员。这种场景下应用数没有限制,DaemonSet 无法支持,因此必须使用 Sidecar 方式,整体规划如下:
- Kubernetes 平台本身的系统组件日志、内核日志相对种类固定,这部分日志使用 DaemonSet 采集,主要为平台的运维人员提供服务;
- 各个业务的日志使用 Sidecar 方式采集,每个业务可以独立设置 Sidecar 的采集目的地址,为业务的 DevOps 人员提供足够的灵活性。
有一个阿里团队需要你!
云原生应用平台邀 Kubernetes/容器/ Serverless/应用交付技术领域专家(P7-P8)加盟。
-
技术要求:Go/Rust/Java/C++,Linux,分布式系统;
-
工作年限:P7 三年起,P8 五年起,具体看实际能力;
- 工作地点:国内(北京 / 杭州 / 深圳);海外(旧金山湾区 / 西雅图)。
简历投递:xining.zj AT alibaba-inc.com。

“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”