零、特征工程(数据-特征-模型)
1、数据特征处理
* 数据选择 /清洗 /采样
* 数据型 / 类别型 /日期型 / 文本型特征处理
* 组合特征处理
2、filter/ wrapper/ embedded 三种特征选择方式
一、前言:
1、有监督学习/ 无监督学习/ 强化学习
2、无监督学习 聚类算法,只有x,没有y,进行prediction 【啤酒、尿布 超市案例】
3、分类问题【猫或狗】/ 聚类问题/ 回归问题/ 降维问题【pca 】
4、每行样本、每列特征
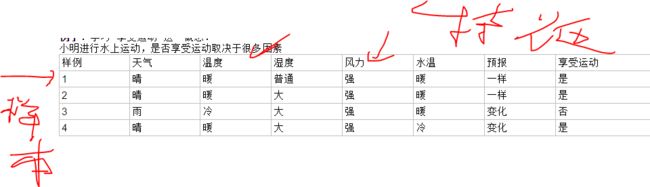
二、回归问题
1、线性回归(预测房价,面积/地段等)
a、有监督学习,输出/预测的结果y 为连续的变量;输入x、y有线性关系。(用等式描绘出 递增/递减/线性关系)
b、多变量的话,x1、x2等,分配权重,显示出对y的贡献程度。
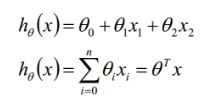
* 损失函数 (loss function)
a、找到最好的权重/参数。 判定做的好不好,得出具体差异度【标准答案/ f(x)的答案】。
b、 平方损失(凸函数-有全局最低点);训练集最优,真实世界的子集。
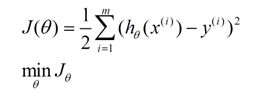
* 梯度下降
a、逐步最小化损失函数的过程,找到方向(斜率),上升最快的方向,直到最低点。a-步长(小些比较好,不要太小)
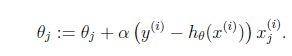
* 过拟合(a,b)与正则化
a、很多特征/模型复杂,假设函数曲线可以对原始数据拟合很好(训练集),但是丧失了一般性,导致新给的特征预测样本效果不好的情况。
b、一次函数/ 二次函数/ 曲线(过拟合,记下了所有的样本点,学习太好,能力太强,容易出现过拟合)
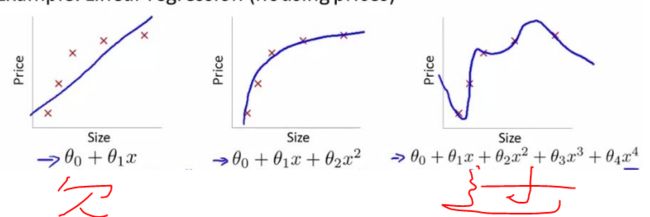
c、控制参数幅度,限制参数搜索空间。 (做题100道,不能背; 给1000道题,背去吧)
d、L1 正则化 ’谁他‘ 的绝对值,L2正则化’水塔‘的平方。
2、 逻辑回归
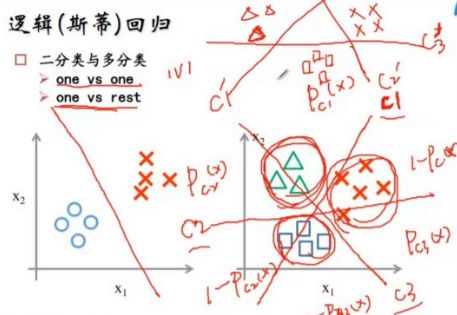
a、健壮性不够,噪声有的话,不稳定。
b、对离散值预测(分类),因为sigmoid函数叫回归。 s(x)取值(0,1)
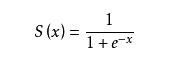
c、判定边界分正样本、负样本。
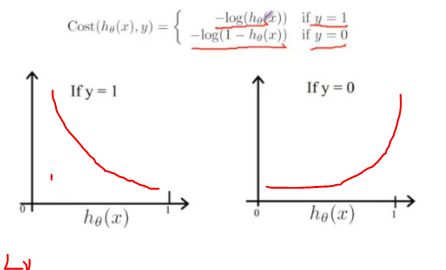
* 损失函数
a、与标准函数的差异,希望损失函数凸函数。
* 梯度下降
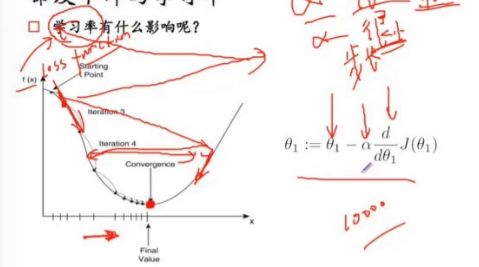
* 过拟合与正则化
3、工程应用
* 优缺点/ 样本处理/ 特征处理/ 算法调优
a、 LR -- SVM/ GDBT/ RandomForest 对比
LR能以概率的形式输出结果,而非只是1,0的判定; LR的可解释性强,可控度高; 训练快,feature engineering 之后效果好; 因为结果是概率,可以做ranking model; 添加feature 容易。
b、应用
CTR预估/ 推荐系统的learning to rank /各种分类场景; 搜索引擎的广告CTR预估/ 搜索排序广告CTR预估/ 购物搭配推荐/ 一天广告赚1000w+的新闻app排序 等基线版都是LR;
三、决策树、随机森林--GBDT、 XGBoost
1、决策树 Decision Tree
a、一定的条件(x),为达到最后的目标,比如相亲推测,客服电话等。得出一个确定的结果(y)。
b、把数据集分成两组,不同数据点被完美区分(Pure)开,- 不是:重复楼上两步 -是的:即可。
• 熵 Entropy
c、用什么条件进行分割?这时候就需要⼀个衡量Purity(纯洁度)的标准(metrics)
d、4是/0否 = 0是/4否 纯洁(pure) H(s)= 0 熵最低
e、优势:- ⾮⿊盒- 轻松去除⽆关attribute (Gain = 0)- Test起来很快 (O(depth));劣势:- 只能线性分割数据- 贪婪算法(可能找不到最好的树)
•信息增益 Information Gain
a、选择哪个熵,用来增益来衡量;上一层没有分割前的不确定性减去上式的求和 ,越大越好,表示降的越多
•常见算法
a、ID3算法:对当前样本集合,计算所有属性的信息增益; 选择信息增益最⼤的属性作为测试属性,把测试属性取值相同的样本划为同⼀个⼦样本集; 若⼦样本集的类别属性只含有单个属性,则分⽀为叶⼦节点,判断其属性值并标上相应的符号,然后返回调⽤处; 否则对⼦样本集递归调⽤本算法

• 过度拟合 Overfitting
a、避免没必要的分裂。剪枝 Prune,(二叉树样子)把一部分数据放一边,试试结果,然后把数据放进来,看看结果如何变,如果没影响,就可以剪去(整体和去掉一半神经元 类似)
b、增益率 GainRatio
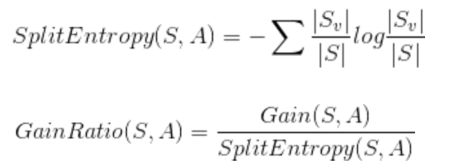
•DT应⽤场景类别:
a、Attribute是连续的,⽽⾮Categoric; 多分类 Multi-Class; 回归Regression
2、决策树的究极进化 Ensemble
• Bagging 取一小部分(属性),子集化。 如下,数据4有个noise,其他几个数据都看不到。 综合结果。
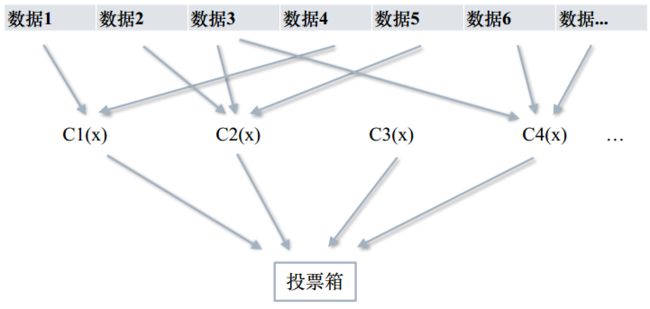
• Random Forest
a、从原始训练数据集中,应⽤bootstrap⽅法有放回地随机抽取k个新的⾃助样本集,并由此构建k棵分类回归树,每次未被抽到的样本组成了K个袋外数据(out-ofbag,BBB)。---设有n个特征,则在每⼀棵树的每个节点处随机抽取m个特征,通过计算每个特征蕴含的信息量,特征中选择⼀个最具有分类能⼒的特征进⾏节点分裂。 ---每棵树最⼤限度地⽣长, 不做任何剪裁。 ---⽣成的多棵树组成随机森林, ⽤随机森林对新的数据进⾏分类,分类结果按树分类器投票多少⽽定。
• Boosting
a、先在原数据集中长出⼀个tree;把前⼀个tree没能完美分类的数据重新weight;⽤新的re-weighted tree再训练出⼀个tree;最终的分类结果由加权投票决定。
b、GBDT
GBDT预测年龄

c、XGBoost --X (Extreme) GBoosted
使⽤L1 L2 Regularization 防⽌Overfitting
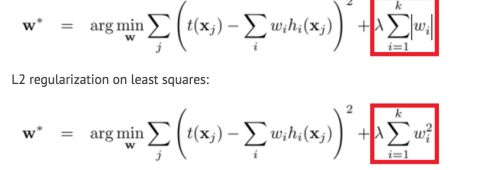
对代价函数⼀阶和⼆阶求导,更快的Converge; 树长全后再从底部向上减枝,防⽌算法贪婪。
