Java中的RPC(远程服务调用)可以通过Serializable的方式进行。
序(序列化和反序列化)
是什么?为啥用?怎么用?——灵魂三连
-
序列化和反序列化是什么?
序列化:把
对象转变为字节序列的过程称为对象的序列化。反序列化:把
字节序列恢复为对象的过程称为对象的反序列化。
-
对象序列化的用途
- 将内存中对象的字节持久化到硬盘中的时候;
- 当使用Socket在网络上传输对象的时候;
- 当使用RMI(远程方法调用)传输对象的时候;
1. Serializable序列化
类的序列化是实现java.io.Serializable接口启动的,不实现此接口的类将不会有任何状态的序列化和反序列化。序列化接口没有方法或字段,仅用于标识序列化的语义。
1.1 Serializable序列化的注意事项
1.1.1 序列化ID问题
Intellij IDEA生成serialVersionUID
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,还取决于两个类序列化ID是否一致
(ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;)。
如果可序列化类没有显示声明SerialVersionUID,则序列化运行时将根据Java对象序列化规范中所述的类的各方面计算该类的默认SerialVersionUID。但是强烈建议所有可序列化的类都明确声明serialVersionUID值。因为默认得UID计算对类详细信息非常敏感,这可能因编译器实现而异,可能会导致反序列化InvalidClassException。
序列化和反序列化代码详见JAVA BIO体系——ObjectInputStream/ObjectOutputStream对象流的使用
1. 反序列化不同的类路径导致ClassCastException异常
Exception in thread "main" java.lang.ClassCastException:
com.JsonSerializer.User cannot be cast to com.IODemo.BIODemo.User
at com.IODemo.BIODemo.ObjectOut.main(ObjectOut.java:12)
2. 反序列化不同的UID导致InvalidClassException异常
java.io.InvalidClassException: com.JsonSerializer.User; local class incompatible:
stream classdesc serialVersionUID = 4731277808546534921,
local class serialVersionUID = 4731277808546534920
序列化ID一般有两种生成规则,一种是固定的1L,一种是随机生成一个不重复long类型数据。
如果是没有特殊需求,就用默认的1L就可以,这样就可以确保代码一致时反序列化成功;
随机生成的序列化ID有什么用呢?有些时候,通过改变序列ID可以用来限制某些用户的使用;
1.1.2 特殊变量序列化
1. 静态变量的序列化
序列化并不保存静态变量,序列化保存的是对象的状态,而静态变量是类的状态。
2. Transient关键字
transient([ˈtrænziənt]临时态)关键字的作用就是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量序列化到文件中,在反序列化后,transient变量会被设为初始值,如int型的为0,对象型的为null。
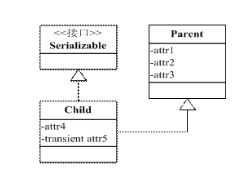
3. 父类的序列化特性
如果子类实现了Serializable接口而父类没有实现,那么父类不会被序列化,但是父类必须有默认的无参构造方法,否则会抛出InvalidClassException异常。如下图所示
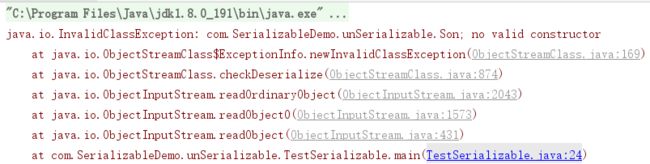
解决方案:想要将父类对象也序列化,就需要让父类也实现Serializable接口;如果父类不实现的话,就需要有默认的无参构造函数,并且父类的变量值都是默认声明的值。
在父类没有实现Serializable接口时,虚拟机不会序列化父对象,而一个Java对象的初始化必须先初始化父对象,再初始化子对象,反序列化也不例外。所以在反序列化时,为了构造父对象,只能调用父类对象的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值。
使用
Transient关键字可以使得字段不被序列化,还有别的方法吗?
根据父类对象序列化的规则,可以将不需要被序列化的字段抽取出来放到父类中,子类实现Serializable接口,父类不实现,根据父类序列化规则,父类的字段数据将不会被序列化。
4. 定制序列化方法
在序列化过程中,虚拟机会试图调用对象类中的
writeObject和readObject方法,进行用户自定义的序列化和反序列化,如果没有这样的方法,则默认调用defaultWriteObject方法以及defaultReadObject方法。用户自定义的writeObject和readObject方法运允许用户控制序列化过程。比如可以在序列化过程中动态的改变序列化的数值。基于这个原理,可以在实际应用中得到使用,用于敏感字段的加密工作。
ObjectOutputStream使用getPrivateMethod
方法writeObject可以自定义用户的序列化过程,如果声明了private void writeObject(),它将会被ObjectOutputStream调用。尽管它们被外部类调用但是他们实际上是private的方法。
writeObject和readObject既不存在于java.lang.Object中,也没有在Serializable中声明,那么ObjectOutputStream如何调用他们的?
ObjectOutputStream使用了反射寻找是否声明了这两个方法。并且ObjectOutputStream使用getPrivateMethod,所以这些方法必须声明为private以至于可以被ObjectOutputStream调用。

在两个方法的开始处,你会发现调用了defaultWriteObject()和defaultReadObject()。它们的作用就是默认序列化进程,就像写/读所有的no-transient和non-static字段。通常来说,所有我们需要处理的字段都应该声明为transient,这样的话,defaultWriteObject/defaultReadObject便可以专注于其余字段,而我们则为特定的字段定制序列化。但是使用默认序列化方法并不是强制的。
需要注意的是:序列化和反序列化的writeXXX()和readXXX()的顺序需要对应。比如有多个字段都用writeInt()——序列化,那么readInt()需要按照顺序将其赋值。
4.1. 使用transient和defaultWriteObject()定制序列化
public class EncryptUser implements Serializable {
private static final long serialVersionUID = 1L;
private String userName;
transient private String password; //不进行序列化,需要自己手动处理的
transient private String sex;
//为节省篇幅 省略get/set/toString()方法
private void writeObject(ObjectOutputStream oos) throws IOException {
oos.defaultWriteObject();
String password = this.password + ":加密";
oos.writeUTF(password); //将密码手动处理加密后序列化
System.out.println("EntryUser序列化成功:" + toString());
}
private void readObject(ObjectInputStream ios) throws IOException, ClassNotFoundException {
ios.defaultReadObject();
password = ios.readUTF() + "解密";
System.out.println("EntryUser反序列化成功:" + toString());
}
}
4.2. ObjectOutputStream.PutField定制序列化
public class EncryptUser implements Serializable {
private static final long serialVersionUID = 1L;
private String userName;
private String password; //不进行序列化,需要自己手动处理的
//为节省篇幅 省略get/set/toString()方法
private void writeObject(ObjectOutputStream oos) throws IOException {
ObjectOutputStream.PutField putField = oos.putFields();//检索写入流的字段
password = "加密:" + password; //模拟加密
//设置写入流的字段
putField.put("password", password);
//将字段写入流
oos.writeFields();
}
private void readObject(ObjectInputStream ios) throws IOException, ClassNotFoundException {
ObjectInputStream.GetField getField = ios.readFields();
Object encryptPassword = getField.get("password", "");
System.out.println("加密的字符串:" + encryptPassword);
password = encryptPassword + "解密";
}
}
4.3. 测试方法
private static void writeObject() {
try {
// 检索用于缓冲要写入流的持久性字段的对象。 当调用writeFields方法时,字段将被写入流。
EncryptUser encryptUser = new EncryptUser();
encryptUser.setUserName("tom");
encryptUser.setPassword("tom245");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("./EncryptUser.txt"));
objectOutputStream.writeObject(encryptUser);
objectOutputStream.flush();
ObjectInputStream objectInputStream=new ObjectInputStream(new FileInputStream("./EncryptUser.txt"));
EncryptUser readObject = (EncryptUser)objectInputStream.readObject();
System.out.println(readObject);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
注:因为JDK1.7之后ObjectOutputStream实现了AutoCloseable接口,会在try方法结束之后,自动关闭资源。
5. 对象属性序列化
如果一个类有引用类型的实例变量,那么这个引用也要实现Serializable接口,否则会出现:
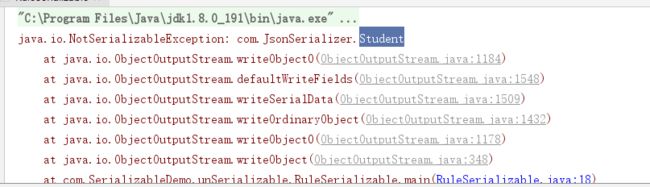
可以使用transient关键字阻止该变量的序列化。
1.1.3 序列化的存储
Java序列化机制为了节省磁盘空间,具有特定的存储规则:当写入文件为同一个对象时,并不会将对象的内容进行存储,而是再次存储一份引用。反序列化时,恢复引用关系。
序列化同一对象
public class RuleSerializable {
public static void main(String[] args) {
try {
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("user.inf"));
User user = new User();
user.setName("tom");
oos.writeObject(user);
oos.flush();
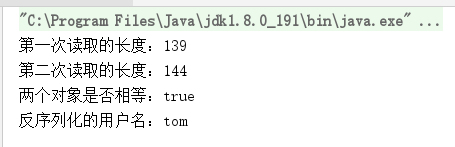
System.out.println("第一次读取的长度:" + new File("user.inf").length());
//第二次序列化后修改数据
user.setName("lili");
oos.writeObject(user);
oos.flush();
System.out.println("第二次读取的长度:" + new File("user.inf").length());
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("user.inf"));
//反序列化
User user1 = (User) objectInputStream.readObject();
User user2 = (User) objectInputStream.readObject();
System.out.println("两个对象是否相等:" + (user1 == user2));
System.out.println("反序列化的用户名:"+user1.getName());
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
我们看到最后的结果是输出
tom,原因是第一次写入对象以后,第二次在试图写入的时候,虚拟机根据引用关系知道已经有一个对象内容写入文件,因此只保存第二次写的引用。所以在读取时,获取的是第一次保存的对象。
2. Protostuff序列化
我们看到Java内置的序列化API
Serializable,但是效率不是很高的。Google提供了一个效率很高的序列化APIProtobuf,但是使用过于复杂。开源社区在Protobuf的基础上封装出Protostuff,在不丢失效率的前提上,使用更加简单。一般情况下,protostuff序列化后的数据大小是Serializable的1/10之一,速度更是两个量级以上。
2.1 protostuff序列化简单使用
MAVEN依赖
io.protostuff
protostuff-runtime
1.6.0
io.protostuff
protostuff-core
1.6.0
序列化:
public static byte[] serializer(T obj) {
Class clazz = (Class) obj.getClass();
//本质上是一个数组对象
LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE);
try {
//获取模板
Schema schema = RuntimeSchema.getSchema(clazz);
//将Object对象装换按照schema对象,转化成byte[]对象
byte[] bytes = ProtostuffIOUtil.toByteArray(obj, schema, buffer);
return bytes;
} catch (Exception e) {
throw new RuntimeException("序列化失败...");
} finally {
buffer.clear();
}
}
- 获取传入对象的
class对象; - 获取一个
byte[]缓冲数组LinkBuffer; - 根据
class对象获取Schema对象 - 将
Object对象序列化成byte[]数组;
反序列化:
public static T deserializer(byte[] data, Class clazz) {
if (data == null || data.length == 0) {
throw new RuntimeException("反序列化失败,byte[]不能为空");
}
T obj = null;
try {
obj = clazz.newInstance();
Schema schema = RuntimeSchema.getSchema(clazz);
ProtostuffIOUtil.mergeFrom(data, obj, schema);
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
return obj;
}
- 传入
byte[]数组和class对象; - 通过反射初始化
class对象; - 获取
Schema对象; - 将
byte[]数组反序列化为Object对象;
注:
RuntimeSchema.getSchema(clazz);实际上会将Schema对象缓存。
2.2 protostuff定制开发
- 使用
transient修饰就不用进行序列化; - 定制序列化时,即用户判断什么情况下才进行序列化,可以使用自定义
Schema进行实现。
1. 定义Java Bean类
此处使用了lombok插件,@Data标签即实现get()和set()方法;@Builder标签实现了建造者设计模式,即静态内部类实现建造者角色,客户端进行导演者角色。
//地址类
@Builder(toBuilder = true)
@Data
public class Address {
private String address;
private String phone;
}
//用户类
@Data
@Builder
public class Person {
private String name;
private Integer age;
//表明该字段不进行序列化
private transient String password;
private List addressList;
}
2. 自定义Address的Schema
用户定制化的开发,此处实现简单,当address为null时,不进行序列化。
//自定义序列化模板
public class AddressSchema implements Schema {
@Override
public String getFieldName(int number) {
String ret = "";
switch (number) {
case 1:
ret = "address";
break;
case 2:
ret = "phone";
break;
default:
break;
}
return ret;
}
@Override
public int getFieldNumber(String name) {
if ("address".equals(name)) {
return 1;
} else if ("phone".equals(name)) {
return 2;
}
return 0;
}
//若是地址为null的话,不允许序列化
@Override
public boolean isInitialized(Address message) {
if (message == null) {
return false;
}
return false;
}
@Override
public Address newMessage() {
return Address.builder().build();
}
@Override
public String messageName() {
return Address.class.getSimpleName();
}
@Override
public String messageFullName() {
return Address.class.getName();
}
@Override
public Class typeClass() {
return Address.class;
}
//反序列化(输入流中读取数据,写入到message中)
@Override
public void mergeFrom(Input input, Address message) throws IOException {
//在流中读取数据(while循环)
while (true) {
int number = input.readFieldNumber(this);//传入的是模板文件
switch (number) {
case 0:
return;
case 1:
message.setAddress(input.readString()); //设置address值
break;
case 2:
message.setPhone(input.readString()); //设置phone值
break;
default:
input.handleUnknownField(number, this);
}
}
}
//序列化(将对象设置到序列化的输出流中)
@Override
public void writeTo(Output output, Address message) throws IOException {
if (message.getAddress() == null) {
throw new UninitializedMessageException(message, this);
}
//属性序号、属性内容,是否允许重复
output.writeString(1, message.getAddress(), false);
if (null != message.getPhone()) {
output.writeString(2, message.getPhone(), false);
}
}
}
3. 编写测试代码
当序列化bjAddress时,因为address字段为null,禁止其序列化。
public class ProtoTest {
public static void main(String[] args) {
Address shAddress = Address.builder().address("上海").phone("123123").build();
Address bjAddress = Address.builder().phone("XXX").build();
Person person = Person.builder().name("yxr").password("123").age(25).
addressList(Arrays.asList(shAddress, bjAddress)).build();
//序列化
Schema schema = RuntimeSchema.createFrom(Person.class);
//创建缓冲区
LinkedBuffer buffer = LinkedBuffer.allocate(1024);
//直接序列化数组
byte[] bytes = ProtostuffIOUtil.toByteArray(person, schema, buffer);
System.out.println("序列化:" + Arrays.toString(bytes));
//反序列化
Schema newSchema = RuntimeSchema.getSchema(Person.class);
Person newPerson = newSchema.newMessage(); //创建了一个person对象
ProtostuffIOUtil.mergeFrom(bytes, newPerson, newSchema);
System.out.println("反序列化:" + newPerson);
buffer.clear(); //释放资源
//创建自定义的Schema对象
Schema addressSchema = new AddressSchema();
byte[] bjArray = ProtostuffIOUtil.toByteArray(bjAddress, addressSchema, buffer);
System.out.println("Address序列化:" + bjAddress);
buffer.clear();
byte[] shArray = ProtostuffIOUtil.toByteArray(shAddress, addressSchema, buffer);
System.out.println(shAddress);
Address newAddress = addressSchema.newMessage();
ProtostuffIOUtil.mergeFrom(shArray, newAddress, addressSchema);
System.out.println("Address反序列化:" + newAddress);
buffer.clear();
}
}
推荐参考:
什么是writeObject 和readObject?可定制的Serializable序列化过程
Protostuff定制Schema开发