书接上文,前面用pyspider实现了去哪网的游记爬取数据存储
然后学习了scrapy之后,用scrapy再次实现了一次,通过实际操做,加深对scrapy的理解
环境介绍:
MacOS Mojave 10.14.5+VSCode1.37.1+Python3.7
1 创建项目
scrapy start project quna
然后项目就创建好了
(base) bogon:~ blaze$ scrapy startproject qunaScrapy
New Scrapy project 'qunaScrapy', using template directory '/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/templates/project', created in:
/Users/blaze/qunaScrapy
You can start your first spider with:
cd qunaScrapy
scrapy genspider example example.com
(base) bogon:~ blaze$ cd qunaScrapy/
(base) bogon:qunaScrapy blaze $ ls
qunaScrapy scrapy.cfg
(base) bogon:qunaScrapy blaze$
2 创建Spider
scrapy genspider quna travel.qunar.com
查看工程目录下的文件

image.png
而我们处理的就是spiders目录下的quna.py
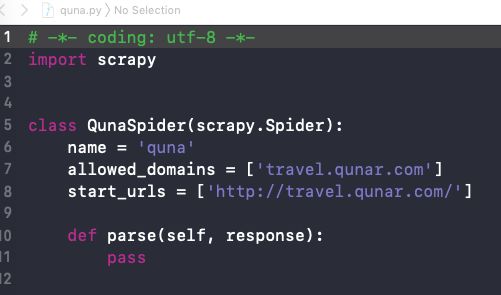
image.png
上面是刚创建的
下面放出爬取去哪网的完整代码,相关的点,我都在代码里做了注释
quna.py
# -*- coding: utf-8 -*-
import os
import scrapy
from scrapy import Selector
from qunaScrapy.items import ImageItem #后面会有讲解
#设置爬取结果存放的路径
DIR_PATH = '/Users/lzx-mac-baibing/Desktop/去哪网游记Scrapy'
#设置分页请求的数量上限
MAX_PAGE = 50
class QunaSpider(scrapy.Spider):
#项目的唯一名,用来区分不同的Spider
name = 'quna'
#允许爬取的域名,凡事不在这里的域名下的请求,都会被过滤
allowed_domains = ['travel.qunar.com','tr-osdcp.qunarzz.com']
#spider启动时,初始化请求的地址
start_urls = ['http://travel.qunar.com/travelbook/list.htm/']
#分页请求时使用
page=1
def __init__(self):
#初始化文件操作类
self.deal = Deal()
#初始化请求默认回掉的方法,作为我们所有解析的入口
#作为scrapy的学习项目,这里我只是实现了爬取第一页数据并获取对应详情的逻辑
#如果有需要,也可以在parse中实现再套一层逻辑,处理page切换
def parse(self, response):
#这里获取的li标签下,class=tit a标签的href数据,也就是所有标题关联的相对url地址
#对应的网页数据如下图图片A所示结构
for each in response.css('li > .tit > a').xpath('@href').extract():
#用获取的相对路径生成完整的路径
url = response.urljoin(each)
#回掉详情
yield scrapy.Request(url=url,callback=self.detail_page,dont_filter=True)
##对应带分页数据请求的parse方法
# def parse(self, response):
# print('====================== ',self.page)
# for each in response.css('li > .tit > a').xpath('@href').extract():
# url = response.urljoin(each)
# yield scrapy.Request(url=url,callback=self.detail_page,dont_filter=True)
# if self.page < MAX_PAGE:
# self.page += 1
# next = response.css('.next').xpath('@href').extract_first()
# if next:
# nextUrl = next
# if next.startswith('http')==False:
# if next.startswith('//'):
# nextUrl = 'http:'+ next
# yield scrapy.Request(url=nextUrl,callback=self.parse,dont_filter=True)
#详情解析
def detail_page(self,response):
#获取图片地地址 class=js_lazyimg 标签下的data-original属性
images = response.css('.js_lazyimg').xpath('@data-original').extract()
#获取title id=booktitle 的文本信息
title = response.css('#booktitle::text').extract_first()
#给每个游记用title创建个文件夹
dir_path = self.deal.mkDir(title)
#图片多了有些乱,加个目录存放图片
self.deal.mkDir(title+'/图片')
#获取标签以及子标签的文本,遍历所有的元素,获得标签文本
contents = response.xpath('//div[@class="b_panel_schedule"]//text()').extract()
#将获取的搜有内容文本,给他拼起来
content = ''
for text in contents:
content = content + '\n' + text
if dir_path:
#将文本信息以txt存储到指定目录下,也就是我们前面创建的文件夹下
self.deal.saveContent(content,dir_path,title)
#图片的处理,后续详解
for img in images:
if img:
file_name = self.deal.getFileName(img)
file_path = dir_path+'/图片/'+file_name
item = ImageItem()
item['src'] = [img]
item['dir_path']=file_path
yield item
#下面这些就不讲了
class Deal:
def __init__(self):
self.path = DIR_PATH
if not self.path.endswith('/'):
self.path = self.path + '/'
if not os.path.exists(self.path):
os.makedirs(self.path)
def mkDir(self, path):
path = path.strip()
dir_path = self.path + path
exists = os.path.exists(dir_path)
if not exists:
os.makedirs(dir_path)
return dir_path
else:
return dir_path
def saveContent(self, content, dir_path, name):
file_name = dir_path + "/" + name + ".txt"
f = open(file_name, "w+")
f.write(content)
def getFileName(self, url):
(url, tempfilename) = os.path.split(url)
return tempfilename

图片A
3 创建item
item 是保存爬取数据的容器,和字典类似,比字典多了额外保护,可以避免拼写错误或者定义字段错误,反正就是直接报错……别问我咋知道的
我们后续需要使用的就是下载地址和保存路径
完整代码如下
item.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ImageItem(scrapy.Item):
src=scrapy.Field()
dir_path=scrapy.Field()
然后spider中用from qunaScrapy.items import ImageItem导入即可
上述的完工了,就能启动爬虫了,只是图片没法下载和存储
scrapy crawl quna
接下来,我们需要处理图片
4 设置Item Pipeline
项目管道,当item生成后,会自动被送到这来处理。
代码实现如下 pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from qunaScrapy.items import ImageItem
import shutil,os,pymysql
from scrapy.pipelines.images import ImagesPipeline
#这个生成项目的时候就有了,必须实现process_item
class QunascrapyPipeline(object):
def process_item(self, item, spider):
return item
#自定义实现文件下载处理
#def item_completed(self,results,sipders...):
class QunaImgDownloadPipeline(ImagesPipeline):
#获取图片地址,发起请求
def get_media_requests(self, item, info):
for image_url in item['src']:
yield scrapy.Request(image_url)
#下载结束后回调的方法
def item_completed(self, results, item, info):
#获取图片的保存的相对路径,full/****.jpg
image_paths = [x['path'] for ok, x in results if ok]
#生成完全地址
readl_path = '/Users/lzx-mac-baibing/Desktop/去哪网游记Scrapy/图集'+'/'+image_paths[0]
#将下载好的文件,移到对应的游记目录下
shutil.move(readl_path,item['dir_path'])
return item
4 配置setting 激活管道
修改部分的代码如下
#键-需要打开的ItemPipeline类
#值-优先级,数字0-1000,数字越小,优先级越高
ITEM_PIPELINES = {
'qunaScrapy.pipelines.QunascrapyPipeline': 1000,
'qunaScrapy.pipelines.QunaImgDownloadPipeline':1
}
#设置的full文件存放的路径
IMAGES_STORE = '/Users/lzx-mac-baibing/Desktop/去哪网游记Scrapy/图集'
#ImageItem中定义的src
IMAGES_URLS_FIELD = 'src'
至此,使用srcapy爬取去哪网游记代码部分完成
将所有修改的文件保存,再次启动爬虫
结果如下
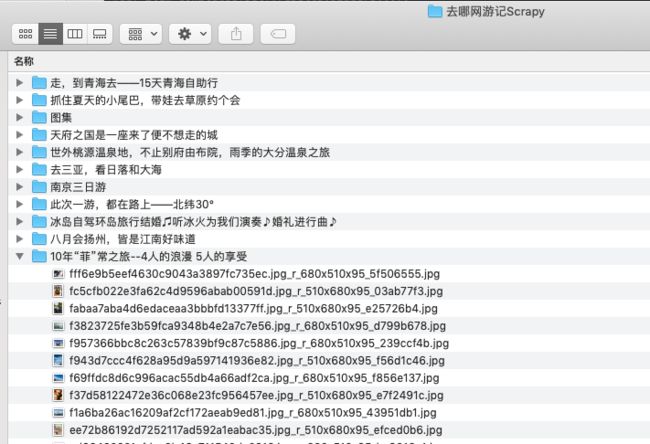
image.png
后记:过程中遇到的问题
1 response.css 和 response.xpath的使用不熟悉,可以加强
2 allowed_domains 中要将自己所有后续用到的添加进去,要不然被过滤了就很尴尬,第一次处理图片时,发现图片请求没反应,然后发现地址和主站地址域名不一样
3
后续再根据学习内容,对这个再优化升级