.NET4.0并行计算技术基础(6)
这是一个系列讲座,前面几讲的链接为:
.NET 4.0 并行计算技术基础(1)
.NET 4.0 并行计算技术基础(2)
.
NET 4.0并行计算技术基础(3)
NET4.0并行计算技术基础(4)
.NET4.0并行计算技术基础(5)
=========================================
19.3.3 使用Parallel类——让一切并行起来
在TPL中,最容易使用的类是Parallel,此类提供了三个方法“群”用于实现三种常用的并行程序执行结构。
1使用Parallel.Invoke并行执行任务
当我们有一系列相互独立的工作需要并行执行时,最简单的方法是使用TPL的Parallel类的Invoke()方法来并行执行它们。
例如,假设以下三个方法调用语句之间是相互独立的
[1]
,则它们可以并行执行:
StatementA();
StatementB();
StatementC();
使用Parrallel.Invoke()方法可以让它们并行执行:
Parallel.Invoke(
() => StatementA(),
() => StatementB(),
() => StatementC() );
Parrallel.Invoke()方法的声明如下:
public static void Invoke(params Action[] actions);
请注意其参数中有一个params前缀,表明此方法接收可变数目的参数。您可以根据需要传给它任意多条语句。
Parrallel.Invoke()能够调用的方法必须满足Action委托的要求(即不能有参数,也不能有返回值),对于不满足这个条件的方法,必须对方法本身进行修改,或者是给其添加一个“外套函数:
//需要并行执行的方法
public static int SomeFunc(int i, int j)
{
//...
}
//可以让Parallel.Invoke()方法调用的“外套”函数
public static void SomeFuncWrapper()
{
int i = 100;
int j = 200;
int result= SomeFunc(i, j);
//...
}
现在,以SomeFuncWrapper()方法为“中介”,SomeFunc()方法就可以和其它方法并行执行了:
Parallel.Invoke(
()=>SomeFuncWrapper(),
()=>OtherFunc(),
……
);
[1]
所谓“相互独立”的方法,指这些方法未共享任何资源,对执行顺序也没有任何要求。
2 使用Parallel.For并行访问数据(partition))
另一种非常常见的并行场景是并行循环,例如:
for (int i = 0; i < 100; i++)
{
DoWork(i); //完成某些工作
}
上述循环中,要等待前一个循环结束之后,下一个循环才开始执行。如果将其改为以下形式:
Parallel.For(0, 100, (i) => DoWork(i));
则这些循环就可以并行执行了。
注意:
并行执行的循环其执行顺序是“乱”的,每次运行都可能会有不同的执行顺序。示例项目ParallelFor展示了这一特性。
Parallel.For还有几个重载的形式,涉及到中途取消操作和异常捕获的问题,我们将在后面的章节中介绍。
一个有意思的问题是,如果在一段顺序执行的程序代码中有一句调用了Parallel.For启动一个并行循环,如下所示:
语句1;
Parallel.For(…);
语句2;
//……其他语句
那么,语句2(及后继语句)是在Parallel.For执行完后才执行呢还是与Parallel.For并行执行?
在MSDN中并没有明确地回答这个问题。
而我经过实验,发现要等到Parallel.For执行完后才会执行语句2(及后继语句)。
技术探险之旅:
Parallel.For
的内部实现
对于好奇的读者,不妨使用Reflector工具去深入探究一下Parallel.For的实现代码,虽然这些代码比较复杂,但不难发现以下代码框架:
//…(代码略)
ParallelForReplicatingTask rootTask = null;
rootTask = new ParallelForReplicatingTask(…);
rootTask.RunSynchronously(parallelOptions.EffectiveTaskScheduler);
//…(代码略)
rootTask.Wait();
//…(代码略)
rootTask.Dispose();
//…(代码略)
其中ParallelForReplicatingTask类是TPL内部定义的一个类,其基类是Task。
从上述代码框架中,不难明白Parallel.For的工作原理:
TPL在Parallel.For方法内部创建了一个任务对象rootTask,然后调用此对象的RunSynchronously()方法以“同步”方式执行并行循环,注意,别被这里的单词“Synchronously(中文译为“同步地”)给欺骗了,此方法绝不是串行执行的。因为此方法接收一个参数,此参数引用一个任务调度器对象,由此调度器对象将任务进行分解,交由线程池中的线程执行,这是实现并行循环的关键!
任务交给线程池中的线程执行之后,Parallel.For方法调用rootTask .Wait()方法等待所有线程完成工作。最后,销毁rootTask对象。
通过仔细分析源码,我们明白了为何在串行代码中使用Parallel.For会出现“串行à并行à串行”这种执行顺序。
另外,我们还可以得到另一个结论:
使用Parallel启动的并行计算,在底层使用Task来完成。
有关Task和任务调度器的内容,在后面的章节中还有介绍。
3 在并行循环中使用线程局部存储区
我们在第17章中介绍过线程局部存储区(TLS:Thread Local Storage),TLS中保存的数据只允许与它相关联的线程独占访问。
在并行循环中,将会启动多个线程执行循环,如果需要的话,我们可以将一些数据放到TLS中,并且在多个循环中共享。
.NET提供了一个泛型的Parallel.For() 方法在并行循环中使用TLS,以下是此方法声明:
public static ParallelLoopResult For(
int fromInclusive,
int toExclusive,
Func localInit,
Func body,
Action localFinally
)
这个方法有相当多的参数,需要仔细地辨析使用。
1.
泛型参数TLocal表明要保存在TLS中的数据的类型。
2.
fromInclusive和toExclusive表示循环控制变量的起始值和结束值,由它们控制循环次数。
3.
localInit引用一个函数,它的返回值将作为保存到TLS中的数据初始值
4.
body是循环体,引用一个函数,注意它也有一个TLocal类型的返回值,此返回值将会被自动保存到TLS中。而它的第3个参数(也是TLocal类型)则代表在TLS中的数据的当前值
5.
localFinally引用一个返回void的函数,此函数在body执行完毕后自动调用,可以在此函数中完成一些清理工作,此函数执行结束之后,线程中止,TLS中的数据将不再可用。
示例ParallelForUseTLS展示了如何在一个执行10次的并行循环中使用TLS保存“时间”数据。
以下是示例程序的某次运行结果:
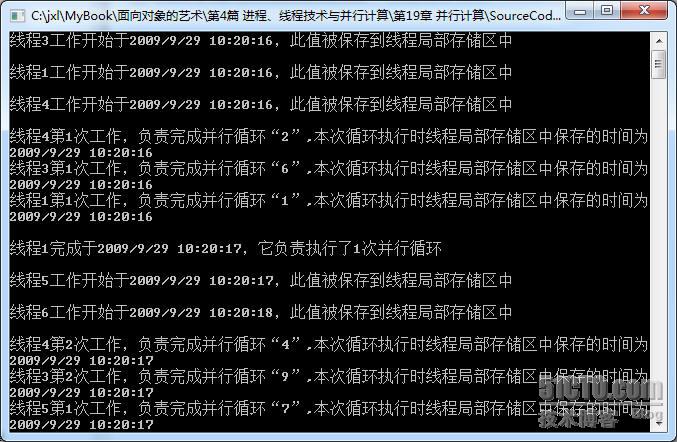
请读者先看源码,然后多次运行示例程序,仔细地分析一下运行结果,可以得到以下结论:
(1)
每次启动的线程个数有可能不同。
(2)
每个线程负责执行的“工作负荷”是不一样的,有的线程可能承担了多个并行循环,而有的线程可能只执行一个并行循环。
(3)
每个线程都有自已的局部存储区。
从上述结论中读者可以“初窥”任务并行库的工作原理。
4 使用Parallel.ForEach
如果你有一大堆“单个”的数据,并且每个数据都需要进行处理时,如果这些针对单个数据的处理是可以并行的话,那么,使用Parallel.ForEach()方法可以加快数据的处理工作。
请看以下示例代码(串行算法):
//循环迭代对象集合中的每个对象
foreach (var item in sourceCollection)
{
Process(item); //处理单个对象
}
要让Process()方法并行执行,可以这样写:
Parallel.ForEach(sourceCollection, item => Process(item));
在后台,任务并行库“悄悄地”把整个集合分成若干个不相交的子集,然后,针对每个集合从线程池中选择一个线程对集合中的对象进行处理。由于每个子集都只对应着一个线程,因此,无需担心发生多线程访问共享资源的问题,而且多个子集的处理工作可以并行执行。
扩充阅读:
自定义数据集“划分(Partition)”算法
Parallel.ForEach()
方法的并行执行依赖于对数据集合的有效划分。负责设计TPL的工程师们已经在设计时考虑了多种可能的情形,并且选择了尽可能高效的数据集划分算法,大多数情况下用默认划分算法就足够了。然而,如果您要解决的问题比较特殊,需要按特定的规则来区分数据集,那么,您就必须定义自己的数据集划分类。
NET提供了两个抽象类作为自定数据划分类的基类(见下图):
.
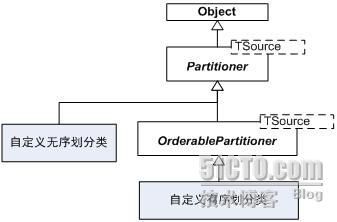
图 19‑14中,如果您所划分的数据子集不需要按次序访问,那么,您可以从Partitioner
Parallel.ForEach()方法有几个重载形式可以接收一个Partitioner
当自定义数据划分类时,需要重写Partitioner
==================================
下一讲,介绍任务并行库的运作机理。
请看:《.NET4.0并行计算技术基础(7)》